|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
הערות הרצאה, דפי רמאות
מאגר מידע. הערות ההרצאה: בקצרה, החשוב ביותר
מדריך / הערות הרצאה, דפי רמאות תוכן העניינים
הרצאה מס' 1. מבוא 1. מערכות ניהול מסדי נתונים מערכות ניהול מסדי נתונים (DBMS) הם מוצרי תוכנה מיוחדים המאפשרים: 1) אחסן לצמיתות כמויות גדולות שרירותיות (אך לא אינסופיות) של נתונים; 2) לחלץ ולשנות את הנתונים המאוחסנים הללו בדרך זו או אחרת, באמצעות מה שנקרא שאילתות; 3) ליצור מסדי נתונים חדשים, כלומר לתאר מבני נתונים לוגיים ולהגדיר את המבנה שלהם, כלומר לספק ממשק תכנות; 4) לגשת לנתונים המאוחסנים על ידי מספר משתמשים בו זמנית (כלומר, לספק גישה למנגנון ניהול העסקאות). בהתאם, מאגרי מידע הם מערכי נתונים הנמצאים בשליטה של מערכות ניהול. כעת מערכות ניהול מסדי נתונים הן מוצרי התוכנה המורכבים ביותר בשוק ומהווים את הבסיס שלו. בעתיד, מתוכנן לבצע פיתוחים בשילוב של מערכות ניהול מסדי נתונים קונבנציונליות עם תכנות מונחה עצמים (OOP) וטכנולוגיות אינטרנט. בתחילה, DBMS התבסס על היררכי и מודלים של נתונים ברשת, כלומר מותר לעבוד רק עם מבני עצים וגרף. בתהליך הפיתוח בשנת 1970, היו מערכות ניהול מסדי נתונים שהוצעו על ידי Codd (Codd), המבוססות על מודל נתונים יחסי. 2. מאגרי מידע יחסיים המונח "יחסי" מגיע מהמילה האנגלית "יחס" - "יחסים". במובן המתמטי הכללי ביותר (כפי שניתן לזכור מקורס האלגברה הקלאסי של הקבוצות) עמדות - זה סט R = {(x1,..., איקסn) | איקס1 ∈ א1,...,איקסn ∈ An}, היכן ש1,...,אn הם הסטים היוצרים את המוצר הקרטזיאני. בדרך זו, יחס R הוא תת-קבוצה של המכפלה הקרטזית של קבוצות: א1 x... x אn : R ⊆ א 1 x... x אn. לדוגמה, שקול יחסים בינאריים בסדר המחמיר "גדול מ" ו"פחות מ" בקבוצת זוגות המספרים המסודרים A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x א2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ א1 x א2. קשרים אלה יכולים להיות מוצגים בצורה של טבלאות. יחס "גדול מ">:
יחס "פחות מ" R<:
לפיכך, אנו רואים שבבסיסי נתונים יחסיים, מגוון רחב של נתונים מאורגן בצורה של קשרים וניתן להציג אותם בצורה של טבלאות. יש לציין ששני היחסים הללו ר> ור< אינן שוות זו לזו, במילים אחרות, הטבלאות המתאימות ליחסים אלו אינן שוות זו לזו. אז צורות ייצוג הנתונים במסדי נתונים יחסיים יכולות להיות שונות. כיצד באה לידי ביטוי אפשרות זו של ייצוג שונה בענייננו? יחסים ר> ור< - אלו קבוצות, וקבוצה היא מבנה לא מסודר, מה שאומר שבטבלאות המתאימות ליחסים אלו, שורות ניתנות להחלפה ביניהן. אבל יחד עם זאת, האלמנטים של קבוצות אלה הם קבוצות מסודרות, במקרה שלנו - זוגות מסודרים של מספרים 3, 4, 5, כלומר, לא ניתן להחליף את העמודות. לפיכך, הראינו שהייצוג של יחס (במובן המתמטי) כטבלה עם סדר שרירותי של שורות ומספר קבוע של עמודות הוא צורת ייצוג מקובלת ונכונה של יחסים. אבל אם נבחן את היחסים ר> ור< מנקודת המבט של המידע המוטבע בהם, ברור שהם מקבילים. לכן, במאגרי מידע יחסיים, למושג "קשר" יש משמעות מעט שונה מהקשר במתמטיקה הכללית. כלומר, זה לא קשור לסדר לפי עמודות בצורה טבלאית של הצגה. במקום זאת, מוצגות סכימות קשרים המכונות "כותרת עמודה שורה", כלומר, כל עמודה מקבלת כותרת, ולאחר מכן ניתן להחליף אותן באופן חופשי. כך ייראה מערכת היחסים R שלנו> ור< במסד נתונים יחסי. יחס סדר קפדני (במקום היחס R>):
יחס סדר קפדני (במקום היחס R<):
שני הטבלאות-יחסים מקבלים קשר חדש (במקרה זה, אותו הדבר, שכן על ידי הכנסת כותרות נוספות מחקנו את ההבדלים בין היחסים R> ור<) כותרת. אז, אנו רואים שבעזרת טריק פשוט כמו הוספת הכותרות הנחוצות לטבלאות, אנו מגיעים למסקנה שהיחסים R> ור< הופכים שוות ערך זה לזה. לפיכך, אנו מסיקים שהמושג "יחסים" במובן המתמטי והיחסי הכללי אינו חופף לחלוטין, הם אינם זהים. נכון להיום, מערכות ניהול מסדי נתונים יחסי מהוות את הבסיס לשוק טכנולוגיית המידע. מחקר נוסף נערך בכיוון של שילוב דרגות שונות של המודל ההתייחסותי. הרצאה מס' 2. נתונים חסרים שני סוגים של ערכים מתוארים במערכות ניהול מסד נתונים לאיתור נתונים חסרים: ריקים (או Empty-values) ו-Undefined (או Null-values). בספרות מסויימת (בעיקר מסחרית), ערכי Null מכונים לפעמים כערכים ריקים או אפסים, אך זה לא נכון. המשמעות של המשמעויות הריקות והבלתי מוגדרות שונה מהותית, ולכן יש צורך לעקוב בקפידה אחר ההקשר של השימוש במונח מסוים. 1. ערכים ריקים (Empty-values) ערך ריק הוא פשוט אחד מערכים אפשריים רבים עבור סוג נתונים מוגדר היטב. אנו מציגים את הכי "טבעי", מיידי ערכים ריקים (כלומר ערכים ריקים שנוכל להקצות בעצמנו מבלי שיהיה לנו מידע נוסף): 1) 0 (אפס) - ערך null ריק עבור סוגי נתונים מספריים; 2) false (שגוי) - הוא ערך ריק עבור סוג נתונים בוליאני; 3) B'' - מחרוזת סיביות ריקה עבור מחרוזות באורך משתנה; 4) "" - מחרוזת ריקה למחרוזות תווים באורך משתנה. במקרים לעיל, תוכל לקבוע אם ערך הוא null או לא על ידי השוואת הערך הקיים עם קבוע null שהוגדר עבור כל סוג נתונים. אבל מערכות ניהול מסדי נתונים, בשל הסכמות המיושמות בהן לאחסון נתונים לטווח ארוך, יכולות לעבוד רק עם מחרוזות באורך קבוע. בגלל זה, מחרוזת ריקה של ביטים יכולה להיקרא מחרוזת של אפסים בינאריים. או מחרוזת המורכבת מרווחים או כל תווי בקרה אחר היא מחרוזת ריקה של תווים. הנה כמה דוגמאות למחרוזות ריקות באורך קבוע: 1) B'0'; 2) B'000'; 3) ''. כיצד ניתן לדעת אם מחרוזת ריקה במקרים אלה? במערכות ניהול מסדי נתונים, פונקציה לוגית משמשת לבדיקת ריקנות, כלומר הפרדיקט IsEmpty(<expression>), שפירושו המילולי "לאכול ריק". פרדיקט זה מובנה בדרך כלל במערכת ניהול מסד הנתונים וניתן להחיל אותו על כל סוג של ביטוי. אם אין פרדיקט כזה במערכות ניהול מסד נתונים, אז אתה יכול לכתוב פונקציה לוגית בעצמך ולכלול אותה ברשימת האובייקטים של מסד הנתונים המתוכנן. שקול דוגמה נוספת שבה לא כל כך קל לקבוע אם יש לנו ערך ריק. נתוני סוג תאריך. איזה ערך בסוג זה צריך להיחשב כערך ריק אם התאריך יכול להשתנות בטווח שבין 01.01.0100. לפני 31.12.9999/XNUMX/XNUMX? לשם כך, ייעוד מיוחד מוכנס ל-DBMS עבור קבועי תאריך ריקים {...}, אם הערך מסוג זה כתוב: {DD. מ.מ. YY} או {YY. מ.מ. DD}. עם ערך זה, מתרחשת השוואה בעת בדיקת הערך לריקנות. זה נחשב לערך מוגדר היטב, "מלא" של ביטוי מסוג זה, והקטן ביותר האפשרי. בעבודה עם מסדי נתונים, ערכי null משמשים לעתים קרובות כערכי ברירת מחדל או משמשים כאשר חסרים ערכי ביטוי. 2. ערכים לא מוגדרים (ערכים אפסים) מלה Null נהגו לציין ערכים לא מוגדרים במאגרי מידע. כדי להבין טוב יותר אילו ערכים מובנים כ-null, שקול טבלה שהיא קטע של מסד נתונים:
לפיכך, ערך לא מוגדר או ערך ריק - זה: 1) לא ידוע, אבל רגיל, כלומר ערך ישים. לדוגמא, למר חאירדינוב, שהוא מספר אחת במאגר המידע שלנו, יש ללא ספק נתוני דרכונים (כמו אדם יליד 1980 ואזרח המדינה), אך הם אינם ידועים ולכן הם אינם כלולים במאגר . לכן, הערך Null ייכתב לעמודה המתאימה של הטבלה; 2) ערך לא ישים. מר קרמזוב (מס' 2 במסד הנתונים שלנו) פשוט אינו יכול להחזיק בנתוני דרכון כלשהם, כי בעת יצירת מאגר מידע זה או הזנת נתונים לתוכו, הוא היה ילד; 3) הערך של כל תא בטבלה, אם איננו יכולים לומר אם הוא ישים או לא. כך למשל, מר קובלנקו, אשר תופס את התפקיד השלישי במאגר הנתונים שנערך על ידינו, אינו יודע את שנת הלידה, ולכן איננו יכולים לומר בוודאות אם יש לו או אין לו נתוני דרכון. וכתוצאה מכך, הערכים של שני תאים בשורה המוקדשת למר קובלנקו יהיו בעלי ערך Nul (הראשון - כבלתי ידוע באופן כללי, השני - כערך שטבעו אינו ידוע). כמו כל סוג נתונים אחר, גם לערכי Null יש מסוימים נכסים. אנו מפרטים את המשמעותיים שבהם: 1) עם הזמן, ההבנה של הערך Null עשויה להשתנות. לדוגמה, עבור מר קרמזוב (מס' 2 במסד הנתונים שלנו) בשנת 2014, כלומר, בהגיעו לגיל הבגרות, הערך Null ישתנה לערך מסוים ומוגדר היטב; 2) ניתן להקצות ערך Null למשתנה או קבוע מכל סוג (מספרי, מחרוזת, בוליאני, תאריך, שעה וכו'); 3) התוצאה של פעולות כלשהן על ביטויים עם ערכי Null כאופרנדים היא ערך Null; 4) חריג לכלל הקודם הם פעולות צירוף ופירוק בתנאי דיני הקליטה (להרחבה על דיני הקליטה ראה סעיף 4 להרצאה מס' 2). 3. ערכי אפס והכלל הכללי להערכת ביטויים בואו נדבר יותר על פעולות על ביטויים המכילים ערכי Null. הכלל הכללי להתמודדות עם ערכי Null (שהתוצאה של פעולות על ערכי Null היא ערך Null) חל על הפעולות הבאות: 1) לאריתמטיקה; 2) לפעולות שלילה, צירוף ופירוק סיביות (למעט חוקי קליטה); 3) לפעולות עם מחרוזות (לדוגמה, שרשור - שרשור של מחרוזות); 4) לפעולות השוואה (<, ≤, ≠, ≥, >). בואו ניתן דוגמאות. כתוצאה מיישום הפעולות הבאות, יתקבלו ערכי Null: 3 + Null, 1/ Null, (Ivanov' + '' + Null) ≔ Null כאן, במקום השוויון הרגיל, אנו משתמשים פעולת החלפה "≔" בשל האופי המיוחד של עבודה עם ערכי Null. בהמשך, תו זה ישמש גם במצבים דומים, מה שאומר שהביטוי מימין לתו הכללי יכול להחליף כל ביטוי מהרשימה משמאל לתו הכללי. האופי של ערכי Null גורם לרוב לכך שביטויים מסוימים מייצרים ערך Null במקום האפס הצפוי, למשל: (x - x), y * (x - x), x * 0 ≔ Null כאשר x = Null. העניין הוא שכאשר מחליפים, למשל, בביטוי (x - x) את הערכים x = Null, נקבל את הביטוי (Null - Null), ואת הכלל הכללי לחישוב הערך של הביטוי המכיל ערכי Null נכנס לתוקף, ומידע על העובדה שכאן הערך Null מתאים לאותו משתנה אובד. אנו יכולים להסיק כי בעת חישוב כל פעולות שאינן לוגיות, ערכי Null מתפרשים כ לֹא יָשִׂים, ולכן התוצאה היא גם ערך Null. השימוש בערכי Null בפעולות השוואה מוביל לתוצאות לא פחות צפויות. לדוגמה, הביטויים הבאים מייצרים גם ערכי Null במקום הערכים הבוליאניים True או False הצפויים: (Null < Null); (ריק ≤ ריק); (Null = Null); (Null ≠ Null); (Null > Null); (Null ≥ Null) ≔ Null; לפיכך, אנו מסיקים שאי אפשר לומר שערך Null שווה או לא שווה לעצמו. כל הופעה חדשה של ערך Null מטופלת כבלתי תלויה, ובכל פעם ערכי Null מטופלים כערכים לא ידועים שונים. בכך, ערכי Null שונים מהותית מכל סוגי הנתונים האחרים, מכיוון שאנו יודעים שהיה בטוח לומר על כל הערכים שהועברו קודם לכן והסוגים שלהם שהם שווים או לא שווים זה לזה. אז, אנו רואים שערכי Null אינם ערכי משתנים במובן הרגיל של המילה. לכן, זה הופך להיות בלתי אפשרי להשוות את הערכים של משתנים או ביטויים המכילים ערכי Null, מכיוון שכתוצאה מכך נקבל לא את ערכי True או False בוליאני, אלא ערכי Null, כמו בדוגמאות הבאות: (x < Null); (איקס ≤ ריק); (x=Null); (x ≠ Null); (x > Null); (x ≥ Null) ≔ Null; לכן, באנלוגיה לערכים ריקים, כדי לבדוק ביטוי עבור ערכי Null, עליך להשתמש בפרדיקט מיוחד: IsNull(<expression>), שפירושו המילולי "הוא ריק". הפונקציה הבוליאנית מחזירה True אם הביטוי מכיל Null או שווה Null, ו-False אחרת, אך לעולם לא מחזירה Null. ניתן להחיל את הפרדיקט IsNull על משתנים וביטויים מכל סוג. כאשר מוחל על ביטויים מהסוג הריק, הפרדיקט תמיד יחזיר False. לדוגמה:
אז, אכן, אנו רואים שבמקרה הראשון, כאשר הפרדיקט IsNull נלקח מאפס, הפלט התברר כ-False. בכל המקרים, כולל השני והשלישי, כאשר הארגומנטים של הפונקציה הלוגית התבררו כשווים לערך Null, ובמקרה הרביעי, כאשר הארגומנט עצמו היה שווה בתחילה לערך Null, הפרדיקט החזיר True. 4. ערכים אפסים ופעולות לוגיות בדרך כלל, רק שלוש פעולות לוגיות נתמכות ישירות במערכות ניהול מסד נתונים: שלילה ¬, צירוף &, ו-disjunction ∨. פעולות הרצף ⇒ והשקילות ⇔ מתבטאות במונחים שלהן באמצעות החלפות: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); שים לב שהחלפות אלה נשמרות במלואן בעת שימוש בערכי Null. באופן מעניין, באמצעות אופרטור השלילה "¬" כל אחת מהפעולות צירוף & או ניתוק ∨ יכולה להתבטא אחת דרך השנייה באופן הבא: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); ההחלפות הללו, כמו גם הקודמות, אינן מושפעות מערכי Null. ועכשיו אנו מציגים את טבלאות האמת של הפעולות הלוגיות של שלילה, צירוף ופיזור, אך בנוסף לערכי True and False הרגילים, אנו משתמשים גם בערך Null כאופרנדים. מטעמי נוחות, אנו מציגים את הסימון הבא: במקום True, נכתוב t, במקום False - f, ובמקום Null - n. 1. הכחשה xx.
ראוי לציין את הנקודות המעניינות הבאות לגבי פעולת השלילה באמצעות ערכי Null: 1) ¬¬x ≔ x - חוק השלילה הכפולה; 2) ¬Null ≔ Null - הערך Null הוא נקודה קבועה. 2. צירוף x ו-y.
לפעולה זו יש גם מאפיינים משלה: 1) x & y ≔ y & x - קומוטטיביות; 2) x & x ≔ x - אימפוטנציה; 3) False & y ≔ False, כאן False הוא אלמנט סופג; 4) True & y ≔ y, כאן True הוא האלמנט הנייטרלי. 3. ניתוק x ∨ y.
מאפיינים: 1) x ∨ y ≔ y ∨ x - קומוטטיביות; 2) x ∨ x ≔ x - אימפוטנציה; 3) False ∨ y ≔ y, כאן False הוא היסוד הנייטרלי; 4) נכון ∨ y ≔ נכון, כאן True הוא אלמנט סופג. חריג לכלל הכללי הוא הכללים לחישוב הפעולות הלוגיות צירוף & וניתוק ∨ בתנאי הפעולה חוקי הקליטה: (False & y) ≔ (x & False) ≔ False; (True ∨ y) ≔ (x ∨ True) ≔ True; כללים נוספים אלה מנוסחים כך שכאשר מחליפים ערך Null ב-False או True, התוצאה עדיין לא תהיה תלויה בערך זה. כפי שהוצג בעבר עבור סוגים אחרים של פעולות, שימוש בערכי Null בפעולות בוליאניות יכול גם לגרום לערכים בלתי צפויים. לדוגמה, ההיגיון במבט ראשון פרוץ דין הדרת השלישי (x ∨ ¬x) ו חוק הרפלקסיביות (x = x), שכן עבור x ≔ Null יש לנו: (x ∨ ¬x), (x = x) ≔ ריק. חוקים לא נאכפים! זה מוסבר באותו אופן כמו קודם: כאשר ערך Null מוחלף לביטוי, המידע שערך זה מדווח על ידי אותו משתנה אובד, והכלל הכללי לעבודה עם ערכי Null נכנס לתוקף. לפיכך, אנו מסיקים: כאשר מבצעים פעולות לוגיות עם ערכי Null כאופרנד, ערכים אלו נקבעים על ידי מערכות ניהול מסד נתונים כמו ישים אך לא ידועים. 5. ערכי אפס ובדיקת מצב לכן, מהאמור לעיל, אנו יכולים להסיק כי בלוגיקה של מערכות ניהול מסד נתונים אין שני ערכים לוגיים (True and False), אלא שלושה, כי הערך Null נחשב גם כאחד הערכים הלוגיים האפשריים. לכן הוא מכונה לעתים קרובות הערך הלא ידוע, הערך הלא ידוע. עם זאת, למרות זאת, רק לוגיקה דו-ערכית מיושמת במערכות ניהול מסדי נתונים. לכן, תנאי עם ערך Null (תנאי לא מוגדר) חייב להתפרש על ידי המכונה כ-True או False. כברירת מחדל, שפת DBMS מזהה תנאי עם ערך Null כ-False. אנו מדגים זאת באמצעות הדוגמאות הבאות ליישום של הצהרות If and While מותנות במערכות ניהול מסדי נתונים: אם P אז A אחר B; ערך זה אומר: אם P מוערך כ-True, אז פעולה A מבוצעת, ואם P מוערך ל-False או Null, אז פעולה B מבוצעת. כעת אנו מיישמים את פעולת השלילה על אופרטור זה, אנו מקבלים: אם ¬P אז B אחרת A; בתורו, האופרטור הזה מתכוון לדברים הבאים: אם ¬P מוערך ל-True, אז פעולה B מבוצעת, ואם ¬P מוערך ל-False או Null, אז פעולה A תבוצע. ושוב, כפי שאנו יכולים לראות, כאשר מופיע ערך Null, אנו נתקלים בתוצאות בלתי צפויות. הנקודה היא ששתי הצהרות If בדוגמה זו אינן שוות ערך! אמנם אחד מהם מתקבל מהשני על ידי שלילת המצב וסידור הענפים מחדש, כלומר על ידי הפעולה הרגילה. מפעילים כאלה הם בדרך כלל מקבילים! אבל בדוגמה שלנו, אנו רואים שהערך Null של התנאי P במקרה הראשון מתאים לפקודה B, ובשני - A. עכשיו שקול את הפעולה של ההצהרה מותנית בעוד: בעוד P לעשות א; ב; איך המפעיל הזה עובד? כל עוד P נכון, פעולה א' תתבצע, וברגע ש-P היא שקר או ריק, פעולה ב' תתבצע. אבל ערכי Null לא תמיד מתפרשים כשווא. לדוגמה, באילוצי יושרה, תנאים לא מוגדרים מוכרים כ-True (אילוצי יושר הם תנאים המוטלים על נתוני הקלט ומבטיחים את נכונותם). הסיבה לכך היא שבאילוצים כאלה יש לדחות רק נתונים כוזבים בכוונה. ושוב, במערכות ניהול מסדי נתונים, יש מיוחד פונקציית החלפה IfNull(אילוצי שלמות, נכון), שאיתם ניתן לייצג במפורש ערכי Null ותנאים לא מוגדרים. הבה נכתוב מחדש את הצהרות ה-If ו-Why המותנות באמצעות הפונקציה הזו: 1) אם IfNull (P, False) אז A אחר B; 2) בעוד IfNull( P, False) לעשות A; ב; לכן, פונקציית ההחלפה IfNull(ביטוי 1, ביטוי 2) מחזירה את הערך של הביטוי הראשון אם היא אינה מכילה ערך Null, וערך הביטוי השני אחרת. יש לציין שלא מוטלות הגבלות על סוג הביטוי המוחזר על ידי הפונקציה IfNull. לכן, באמצעות פונקציה זו, אתה יכול לעקוף במפורש כל כללים לעבודה עם ערכי Null. הרצאה מס' 3. אובייקטי נתונים יחסיים 1. דרישות לצורת ייצוג טבלאית של יחסים 1. הדרישה הראשונה לצורת הטבלה של ייצוג היחסים היא סופיות. עבודה עם אינסוף טבלאות, מערכות יחסים או כל ייצוג וארגון אחר של נתונים אינה נוחה, המאמץ המושקע לעתים רחוקות מוצדק, ויתרה מכך, לכיוון זה יש מעט יישום מעשי. אבל חוץ מזה, די צפוי, יש דרישות אחרות. 2. כותרת הטבלה המייצגת את הקשר חייבת להיות מורכבת משורה אחת - כותרת העמודות, ועם שמות ייחודיים. כותרות מרובות רמות אינן מותרות. לדוגמה, אלה:
כל הכותרות הרב-שכבות מוחלפות בכותרות חד-שכבות על ידי בחירת כותרות מתאימות. בדוגמה שלנו, הטבלה לאחר התמורות שצוינו תיראה כך:
אנו רואים שהשם של כל עמודה הוא ייחודי, כך שניתן להחליף אותם כרצונך, כלומר הסדר שלהם הופך ללא רלוונטי. וזה חשוב מאוד כי זה הנכס השלישי. 3. סדר השורות לא צריך להיות משמעותי. עם זאת, גם דרישה זו אינה מגבילה לחלוטין, שכן ניתן לצמצם בקלות כל טבלה לטופס הנדרש. לדוגמה, ניתן להזין עמודה נוספת שתקבע את סדר השורות. במקרה זה, שום דבר לא ישתנה גם מסידור מחדש של הקווים. הנה דוגמה לטבלה כזו:
4. לא אמורות להיות שורות כפולות בטבלה המייצגות את הקשר. אם ישנן שורות כפולות בטבלה, ניתן לתקן זאת בקלות על ידי הכנסת עמודה נוספת האחראית למספר הכפילויות של כל שורה, למשל:
גם המאפיין הבא צפוי למדי, מכיוון שהוא עומד בבסיס כל העקרונות של תכנות ועיצוב מסדי נתונים יחסיים. 5. הנתונים בכל העמודות חייבים להיות מאותו סוג. וחוץ מזה, הם חייבים להיות מסוג פשוט. בואו נסביר מהם סוגי נתונים פשוטים ומורכבים. סוג נתונים פשוט הוא כזה שערכי הנתונים שלו אינם מורכבים, כלומר אינם מכילים מרכיבים. לפיכך, לא רשימות, לא מערכים, לא עצים, ולא אובייקטים מרוכבים דומים צריכים להיות נוכחים בעמודות הטבלה. חפצים כאלה הם סוג נתונים מורכב - במערכות ניהול מסדי נתונים יחסי, הם עצמם מוצגים בצורה של קשרי טבלאות עצמאיים. 2. תחומים ותכונות תחומים ותכונות הם מושגי יסוד בתורת היצירה והניהול של מסדי נתונים. בואו נסביר מה זה. רִשְׁמִית, תחום תכונה (מסומן dom(a)), כאשר a הוא תכונה, מוגדר כקבוצה של ערכים חוקיים מאותו סוג של התכונה המתאימה a. סוג זה חייב להיות פשוט, כלומר: dom(a) ⊆ {x | type(x) = type(a)}; תכונה (מסומן a) בתורו מוגדר כזוג מסודר המורכב משם התכונה (a) ותחום התכונה domain(a), כלומר: a = (שם(א): dom(a)); הגדרה זו משתמשת ב-":" במקום "," הרגיל (כמו בהגדרות זוג מסודר סטנדרטי). זה נעשה כדי להדגיש את השיוך של התחום של התכונה וסוג הנתונים של התכונה. הנה כמה דוגמאות לתכונות שונות: а1 = (קורס: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | type(x) = real, x 0}); а3 = (LengthSm: {x | type(x) = real, x 0}); שימו לב שהתכונות א2 ו3 דומיינים תואמים רשמית. אבל המשמעות הסמנטית של תכונות אלה שונה, מכיוון שהשוואת ערכי המסה והאורך היא חסרת משמעות. לכן, תחום תכונה משויך לא רק לסוג הערכים התקפים, אלא גם למשמעות סמנטית. בצורה טבלאית של קשר, התכונה מוצגת ככותרת עמודה בטבלה, והתחום של התכונה אינו מצוין, אלא משתמע. זה נראה כמו זה:
קל לראות שכאן כל אחת מהכותרות א1,2,3 עמודות של טבלה המייצגות קשר הוא תכונה נפרדת. 3. סכימות של מערכות יחסים. טופלים בעלי שם בתיאוריה ובפרקטיקה של DBMS, המושגים של סכימת יחס וערך שם של tuple על תכונה הם בסיסיים. בואו נביא אותם. ערכת יחסים (מסומן S) מוגדר כקבוצה סופית של תכונות עם שמות ייחודיים, כלומר: S = {a | a ∈ S}; בכל טבלה המייצגת יחס, כל כותרות העמודות (כל התכונות) משולבות בסכימה של היחס. מספר התכונות בסכימת קשרים קובע כיתה זה עמדות ומסומן כקרדינליות הסט: |S|. סכימת קשר עשוי להיות משויך לשם סכימת קשר. בצורה טבלאית של ייצוג קשרים, כפי שניתן לראות בקלות, סכימת הקשר היא לא יותר משורה של כותרות עמודות.
S = {א1,2,3,4} - סכימת קשרים של טבלה זו. שם הקשר מוצג ככותרת סכמטית של הטבלה. בצורת טקסט, ניתן לייצג את סכימת הקשר כרשימה בעלת שם של שמות תכונות, לדוגמה: תלמידים (מספר כיתה, שם משפחה, שם פרטי, פטרונימי, תאריך לידה). כאן, כמו בטופס הטבלה, תחומי תכונות אינם מצוינים אלא משתמעים. מההגדרה עולה שגם הסכימה של יחס יכולה להיות ריקה (S = ∅). נכון, זה אפשרי רק בתיאוריה, שכן בפועל מערכת ניהול מסדי הנתונים לעולם לא תאפשר יצירת סכימת קשרים ריקה. ערך tuple בשם בתכונה (מסומן t(א)) מוגדר באנלוגיה עם תכונה כזוג מסודר המורכב משם תכונה וערך תכונה, כלומר: t(a) = (שם(a) : x), x ∈ dom(a); אנו רואים שערך התכונה נלקח מתחום התכונה. בצורה הטבלה של יחס, כל ערך בעל שם של tuple על תכונה הוא תא טבלה מתאים:
כאן t(א1), t(א2), t(א3) - ערכים בשם של tuple t על תכונות א1ו -2ו -3. הדוגמאות הפשוטות ביותר של ערכי tuple בשם על תכונות: (קורס: 5), (ציון: 5); כאן קורס וציון הם שמות של שתי תכונות, בהתאמה, ו-5 הוא אחד מהערכים שלהם שנלקח מהדומיינים שלהם. כמובן, למרות שערכים אלה שווים בשני המקרים, הם שונים מבחינה סמנטית, מכיוון שקבוצות הערכים הללו בשני המקרים שונות זו מזו. 4. Tuples. סוגי טופל את הרעיון של tuple במערכות ניהול מסד נתונים אפשר למצוא אינטואיטיבית כבר מהנקודה הקודמת, כשדיברנו על הערך הנקוב של tuple על תכונות שונות. כך, tuple (מסומן t, מאנגלית. tuple - "tuple") עם סכימת יחס S מוגדרת כקבוצת הערכים הנקובים של tuple זה על כל התכונות הכלולות בסכימת יחס זה S. במילים אחרות, תכונות לקוחות מ היקף של tuple, def(t), כלומר: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;. חשוב שלא יותר מערך תכונה אחד חייב להתאים לשם תכונה אחד. בצורה הטבלה של הקשר, tuple יהיה כל שורה בטבלה, כלומר:
כאן t1(S) = {t(a1), t(א2), t(א3), t(א4)} ו-t2(S) = {t(a5), t(א6), t(א7), t(א8)} - tuples. Tuples ב-DBMS נבדלים זה מזה סוגים בהתאם לתחום ההגדרה שלו. הטפולים נקראים: 1) חלקי, אם תחום ההגדרה שלהם נכלל או עולה בקנה אחד עם הסכימה של היחס, כלומר def(t) ⊆ S. זהו מקרה שכיח בפרקטיקה של מסדי נתונים; 2) שלם, במקרה שתחום ההגדרה שלהם חופף לחלוטין, שווה לסכימת היחסים, כלומר def(t) = S; 3) לא שלם, אם תחום ההגדרה נכלל לחלוטין בסכמת היחסים, כלומר def(t) ⊂ S; 4) בשום מקום לא מוגדר, אם תחום ההגדרה שלהם שווה לקבוצה הריקה, כלומר def(t) = ∅. בואו נסביר עם דוגמה. נניח שיש לנו קשר נתון בטבלה הבאה.
תן כאן לא1 = {10, 20, 30}, ט2 = {10, 20, Null}, t3 = {Null, Null, Null}. אז קל לראות שהטופל ט1 - שלם, מכיוון שתחום ההגדרה שלו הוא def(t1) = {a, b, c} = S. Tuple t2 - לא שלם, def(t2) = { a, b} ⊂ S. לבסוף, ה-tuple t3 - לא מוגדר בשום מקום, מכיוון שה-def(t3) שלו = ∅. יש לציין ש-tuple שלא הוגדר בשום מקום הוא קבוצה ריקה, בכל זאת משויכת לסכימת יחס. לפעמים tuple מוגדר בשום מקום מסומן: ∅(S). כפי שכבר ראינו בדוגמה לעיל, tuple כזה הוא שורת טבלה המורכבת רק מערכי Null. מעניין, בר השוואה, כלומר אולי שווים, הם רק tuples עם אותה סכימת קשר. לכן, למשל, שני tuples מוגדרים בשום מקום עם סכימות יחסים שונות לא יהיו שווים, כפי שניתן לצפות. הם יהיו שונים בדיוק כמו דפוסי היחסים שלהם. 5. מערכות יחסים. סוגי מערכות יחסים ולבסוף, בואו נגדיר את מערכת היחסים כמעין חלק העליון של הפירמידה, המורכב מכל המושגים הקודמים. כך, עמדות (מסומן r, מאנגלית. יחס) עם סכימת יחס S מוגדרת כקבוצה סופית בהכרח של טפולים בעלי אותה סכימת יחס S. לפיכך: r ≡ r(S) = {t(S) | t ∈r}; באנלוגיה לסכימות יחס, נקרא מספר הטפולים ביחס כוח מערכת יחסים ומסומן כקרדינליות הסט: |r|. יחסים, כמו tuples, שונים בסוגים. אז הקשר נקרא: 1) חלקי, אם התנאי הבא מתקיים עבור כל tuple שנכלל ביחס: [def(t) ⊆ S]. זה (כמו עם tuples) המקרה הכללי; 2) שלם, למקרה שאם ∀t ∈ r(S) יש לנו [def(t) = S]; 3) לא שלם, אם ∃t ∈ r(S) def(t) ⊂ S; 4) בשום מקום לא מוגדר, אם ∀t ∈ r(S) [def(t) = ∅]. הבה נשים תשומת לב מיוחדת ליחסים מוגדרים בשום מקום. שלא כמו tuples, עבודה עם מערכות יחסים כאלה כרוכה במעט עדינות. הנקודה היא שקשרים מוגדרים בשום מקום יכולים להיות משני סוגים: הם יכולים להיות ריקים, או שהם יכולים להכיל טופלה יחידה שהוגדרה בשום מקום (יחסים כאלה מסומנים על ידי {∅(S)}). בר השוואה (באנלוגיה עם tuples), כלומר, אולי שווים, הם רק יחסים עם אותה סכימת יחס. לכן, מערכות יחסים עם דפוסי יחסים שונים שונים. בצורת טבלה, היחס הוא גוף הטבלה, שאליו מתאימה השורה - כותרת העמודות, כלומר פשוטו כמשמעו - הטבלה כולה, יחד עם השורה הראשונה המכילה את הכותרות. הרצאה מס' 4. אלגברה יחסית. פעולות לא חוקיות אלגברה יחסי, כפי שניתן לנחש, הוא סוג מיוחד של אלגברה שבה כל הפעולות מבוצעות על מודלים של נתונים יחסיים, כלומר על קשרים. במונחים טבלאיים, יחס כולל שורות, עמודות ושורה - כותרת העמודות. לכן, פעולות אונאריות טבעיות הן פעולות של בחירת שורות או עמודות מסוימות, כמו גם שינוי כותרות עמודות - שינוי שמות של תכונות. 1. פעולת בחירה לא נורית המבצע האנרי הראשון שנבחן הוא פעולת אחזור - פעולת בחירת שורות מטבלה המייצגת יחס, לפי עיקרון כלשהו, כלומר, בחירת שורות-טופלות המקיימות תנאי או תנאים מסוימים. מפעיל אחזור מסומן על ידי σ , מצב דגימה - P , כלומר, האופרטור σ נלקח תמיד עם תנאי מסוים על הטפולים P, והתנאי P עצמו נכתב בהתאם לסכימה של היחס S. בהתחשב בכל זה, פעולת אחזור מעל הסכימה של היחס S ביחס ליחס r ייראה כך: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, False}; התוצאה של פעולה זו תהיה יחס חדש עם אותה סכימת יחס S, המורכבת מאותם tuples t(S) של היחס-אופרנד המקורי שעומדים בתנאי הבחירה P t. ברור שכדי להחיל תנאי כלשהו על טאפל, יש צורך להחליף את הערכים של תכונות ה tuple במקום את שמות התכונות. כדי להבין טוב יותר איך הפעולה הזו עובדת, בואו נסתכל על דוגמה. תן את סכימת היחסים הבאה: S: מפגש (מספר ציונים, שם משפחה, נושא, ציון). ניקח את תנאי הבחירה כדלקמן: P = (נושא = 'מדעי המחשב' והערכה > 3). אנחנו צריכים לחלץ מה-relation-operand את אותם tuples המכילים מידע על תלמידים שעברו את המקצוע "מדעי המחשב" בשלוש נקודות לפחות. ניתן גם את הטפול הבא מיחס זה: t0(S) ∈ r(S): {(מספר ציונים: 100), (שם משפחה: 'איבנוב'), (נושא: 'מאגרי מידע'), (ציון: 5)}; החלת תנאי הבחירה שלנו על ה-tuple t0, אנחנו מקבלים: פ ט0 = ('מאגרי מידע' = 'אינפורמטיקה' ו-5 > 3); בטפול המסוים הזה, תנאי הבחירה אינו מתקיים. באופן כללי, התוצאה של המדגם המסוים הזה σ<Subject = 'מדעי המחשב' וציון > 3 > מפגש תהיה טבלה "Session", שבה נותרו שורות העונות על תנאי הבחירה. 2. פעולת הקרנה לא נורית מבצע אונרי סטנדרטי נוסף שנלמד הוא מבצע ההקרנה. פעולת הקרנה היא פעולת בחירת עמודות מטבלה המייצגת יחס, לפי תכונה כלשהי. כלומר, המכונה בוחרת את התכונות האלה (כלומר, ממש אותן עמודות) של יחס האופרנד המקורי שצוינו בהקרנה. מפעיל הקרנה מסומן ב-[S'] או π . כאן S' היא תת-סכימה של הסכימה המקורית של היחס S, כלומר חלק מהעמודות שלה. מה זה אומר? משמעות הדבר היא של-S' יש פחות תכונות מ-S, מכיוון שרק אותן תכונות נשארו ב-S' שלגביהן התקיים תנאי ההשלכה. ובטבלה המייצגת את היחס r(S' ), יש כמה שורות כמו שיש בטבלה r(S), ויש פחות עמודות, שכן נשארות רק אלו המתאימות לשאר התכונות. לפיכך, אופרטור ההשלכה π< S'> המוחל על היחס r(S) מביא ליחס חדש עם סכימת יחס שונה r(S' ), המורכבת מהשלכות t(S) [S' ] של tuples של המקור. יַחַס. כיצד מוגדרות תחזיות הטפולות הללו? הַקרָנָה של כל tuple t(S) של היחס המקורי r(S) למעגל המשנה S' נקבע על ידי הנוסחה הבאה: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. חשוב לציין כי טופלים כפולים אינם נכללים בתוצאה, כלומר לא יהיו שורות כפולות בטבלה המייצגת את החדשה. עם כל האמור לעיל, פעולת הקרנה במונחים של מערכות ניהול מסדי נתונים תיראה כך: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; הבה נסתכל על דוגמה הממחישה כיצד פועלת פעולת האחזור. תנו ליחס "מפגש" ולסכימת היחס הזה להינתן: S: מפגש (מספר ספר כיתה, שם משפחה, נושא, כיתה); נהיה מעוניינים רק בשתי תכונות מהסכימה הזו, כלומר "ספר הציונים #" ו"שם משפחה" של התלמיד, אז תת הסכימה של S תיראה כך: ש': (מספר ספר רישום, שם משפחה). עלינו להשליך את היחס הראשוני r(S) על תת-המעגל S'. לאחר מכן, תן לנו tuple t0(S) מהקשר המקורי: t0(S) ∈ r(S): {(מספר ציונים: 100), (שם משפחה: 'איבנוב'), (נושא: 'מאגרי מידע'), (ציון: 5)}; לפיכך, ההשלכה של tuple זה על תת-מעגל S' הנתון תיראה כך: t0(ס) ש': {(מספר ספר חשבון: 100), (שם משפחה: 'איבנוב')}; אם אנחנו מדברים על פעולת ההשלכה במונחים של טבלאות, אז ההשלכה Session [מספר ספר ציונים, שם משפחה] של היחס המקורי הוא טבלת Session, ממנה נמחקים כל העמודות, למעט שתיים: מספר ציונים ושם משפחה. בנוסף, כל השורות הכפולות גם הוסרו. 3. פעולת שינוי שם אחד והמבצע האנרי האחרון שנבחן הוא פעולת שינוי שם התכונה. אם מדברים על הקשר כעל טבלה, אזי יש צורך בפעולת שינוי השם על מנת לשנות את שמות כל העמודות או חלקן. שנה שם מפעיל נראה כך: ρ<φ>, כאן φ - שנה שם פונקציה. פונקציה זו מייצרת התאמה אחד לאחד בין שמות תכונות הסכימה S ו- Ŝ, כאשר בהתאמה S היא הסכימה של היחס המקורי ו-Ŝ היא הסכימה של היחס עם תכונות ששמם שונה. לפיכך, האופרטור ρ<φ> המוחל על היחס r(S) נותן יחס חדש עם הסכימה Ŝ, המורכב מטופלים של היחס המקורי עם רק תכונות ששונו. בואו נכתוב את הפעולה של שינוי שמות של תכונות במונחים של מערכות ניהול מסד נתונים: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; הנה דוגמה לשימוש בפעולה זו: בואו ניקח בחשבון את מפגש היחסים שכבר מוכר לנו, עם הסכמה: S: מפגש (מספר ספר כיתה, שם משפחה, נושא, כיתה); בואו נציג סכימת קשרים חדשה Ŝ, עם שמות מאפיינים שונים שהיינו רוצים לראות במקום הקיימים: Ŝ : (מס' ZK, שם משפחה, נושא, ציון); לדוגמה, לקוח מסד נתונים רצה לראות שמות אחרים בקשר שלך מחוץ לקופסה. כדי ליישם הזמנה זו, עליך לעצב את פונקציית שינוי השם הבאה: φ : (מספר ספר חשבון, שם משפחה, נושא, ציון) ← (מספר ZK, שם משפחה, נושא, ציון); למעשה, רק שני מאפיינים צריכים לשנות את השם, ולכן זה חוקי לכתוב את פונקציית שינוי השם הבאה במקום הנוכחית: φ : (מספר ספר השיאים, כיתה) → (מס' ז"ק, ציון); יתר על כן, ניתן לתת גם את הטפול המוכר ממילא השייך ליחס הפגישה: t0(S) ∈ r(S): {(מספר ציונים: 100), (שם משפחה: 'איבנוב'), (נושא: 'מאגרי מידע'), (ציון: 5)}; החל את האופרטור לשינוי שם על טופלה זו: ρ<φ>t0(S): {(ZK #: 100), (שם משפחה: 'איבנוב'), (נושא: 'מאגרי מידע'), (ציון: 5)}; אז זהו אחד מהטפולים של הקשר שלנו, ששמותיהם שונה. במונחים טבלה, היחס ρ < מספר ספר ציונים, ציון → "לא. ZK, ציון > סשן - זוהי טבלה חדשה המתקבלת מטבלת הקשרים "Session" על ידי שינוי שמות התכונות שצוינו. 4. מאפיינים של פעולות לא נכונות לפעולות לא נכונות, כמו לכל פעולות אחרות, יש תכונות מסוימות. בואו ניקח בחשבון את החשוב שבהם. התכונה הראשונה של הפעולות האנואריות של בחירה, השלכה ושינוי שמות היא התכונה המאפיינת את היחס בין הקרדינליות של היחסים. (נזכיר שהקרדינליות היא מספר הטפולים ביחס כזה או אחר.) ברור שכאן אנו בוחנים, בהתאמה, את היחס הראשוני ואת היחס המתקבל כתוצאה מיישום פעולה כזו או אחרת. שימו לב שכל המאפיינים של פעולות לא נוריות נובעות ישירות מההגדרות שלהן, כך שניתן להסביר אותן בקלות ואפילו, אם רוצים, להסיק אותן באופן עצמאי. אז: 1) יחס כוח: א) עבור פעולת הבחירה: | σ r |≤ |r|; ב) עבור פעולת ההקרנה: | r[S'] | ≤ |r|; ג) עבור פעולת שינוי השם: | ρ<φ>r | = |r|; בסך הכל, אנו רואים כי עבור שני אופרטורים, דהיינו עבור אופרטור הבחירה ואופרטור ההקרנה, כוחם של היחסים המקוריים - אופרנדים גדול מהכוח של היחסים המתקבלים מהמקוריים על ידי יישום הפעולות המתאימות. הסיבה לכך היא שהבחירה הנלווית לשתי פעולות הבחירה והפרויקט הללו לא כוללת כמה שורות או עמודות שאינן עומדות בתנאי הבחירה. במקרה שבו כל השורות או העמודות עומדות בתנאים, אין ירידה בעוצמה (כלומר, מספר הטפולים), ולכן אי השוויון בנוסחאות אינו קפדני. במקרה של פעולת שינוי השם, כוחו של היחס אינו משתנה, בשל העובדה שבעת החלפת שמות, אין טופלים מודרים מהיחס; 2) מאפיין אימפוטנטי: א) עבור פעולת הדגימה: σ σ r = σ ; ב) עבור פעולת ההקרנה: r [S'] [S'] = r [S']; ג) עבור פעולת שינוי השם, במקרה הכללי, המאפיין של אי-פוטנציה אינו ישים. מאפיין זה אומר שהחלת אותו אופרטור פעמיים ברציפות על כל קשר שווה ערך להחלה פעם אחת. עבור פעולת שינוי שמות של תכונות יחס, באופן כללי, ניתן להחיל מאפיין זה, אך עם הסתייגויות ותנאים מיוחדים. המאפיין של אידמפוטנציה משמש לעתים קרובות מאוד כדי לפשט את צורת הביטוי ולהביא אותו לצורה יותר חסכונית, ממשית. והתכונה האחרונה שנבחן היא תכונת המונוטוניות. מעניין לציין שבכל תנאי כל שלושת האופרטורים הם מונוטוניים; 3) מאפיין מונוטוניות: א) לפעולת אחזור: ר1 ⊆ r2 ⇒σ ר1 ⇒ σ ר2; ב) לפעולת ההקרנה: ר1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; ג) עבור פעולת שינוי השם: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; מושג המונוטוניות באלגברה יחסי דומה לאותו מושג מאלגברה כללית רגילה. הבה נבהיר: אם בתחילה היחסים r1 ו-r2 היו קשורים זה לזה בצורה כזו ש-r ⊆ r2, אז גם לאחר החלת כל אחד משלושת אופרטורי הבחירה, ההקרנה או שינוי השם, הקשר הזה יישמר. הרצאה מס' 5. אלגברה יחסית. פעולות בינאריות 1. פעולות של איחוד, צומת, הבדל לכל פעולות יש כללי תחולה משלהם שיש להקפיד עליהם כדי שביטויים ופעולות לא יאבדו את משמעותם. ניתן ליישם את הפעולות התיאורטיות של הקבוצות הבינאריות של איחוד, צומת והבדל רק על שני יחסים בהכרח עם אותה סכימת יחס. התוצאה של פעולות בינאריות כאלה יהיו יחסים המורכבים מטופלים העומדים בתנאי הפעולות, אך עם אותה סכימת יחס כמו האופרנדים. 1. התוצאה פעולות האיגוד שני יחסים ר1(ש) ו-ר2(S) יהיה קשר חדש r3(S) המורכב מאותם tuples של יחסים r1(ש) ו-ר2(S) השייכים לפחות לאחד מהיחסים המקוריים ועם אותה סכימת קשר. אז המפגש בין שני היחסים הוא: r3(S) = r1(ש) ר2(S) = {t(S) | t ∈r1 ∪t ∈r2}; לשם הבהירות, הנה דוגמה במונחים של טבלאות: תנו שני יחסים: r1(S):
r2(S):
אנו רואים שהסכמות של היחסים הראשון והשני זהים, רק שיש להם מספר שונה של tuples. האיחוד של שני היחסים הללו יהיה היחס r3(S), שתתאים לטבלה הבאה: r3(S) = r1(ש) ר2(S):
אז, הסכימה של היחס S לא השתנתה, רק מספר הטפולים גדל. 2. נעבור לשיקול של הפעולה הבינארית הבאה - פעולות צומת שתי מערכות יחסים. כפי שאנו יודעים מהגיאומטריה של בית הספר, היחס המתקבל יכלול רק את הטפולים של היחסים המקוריים שנמצאים בו זמנית בשני היחסים r1(ש) ו-ר2(S) (שוב, שימו לב לאותו דפוס יחסים). פעולת ההצטלבות של שני יחסים תיראה כך: r4(S) = r1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; ושוב, שקול את ההשפעה של פעולה זו על היחסים המוצגים בצורה של טבלאות: r1(S):
r2(S):
לפי הגדרת הפעולה לפי צומת היחסים r1(ש) ו-ר2(S) יהיה קשר חדש r4(S), שתצוגת הטבלה שלו תיראה כך: r4(S) = r1(S)∩r2(S):
ואכן, אם נתבונן בטפולים של היחסים הראשוניים הראשון והשני, יש ביניהם רק אחד משותף: {ב, ב}. זה הפך להיות הטפול היחיד של היחס החדש r4(S). 3. פעולת הבדל שני יחסים מוגדרים באופן דומה לפעולות הקודמות. ליחסי אופרנד, כמו בפעולות הקודמות, חייבות להיות אותן סכימות יחס, ואז היחס שיתקבל יכלול את כל אותם tuples של היחס הראשון שאינם נמצאים בשני, כלומר: r5(S) = r1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; היחסים הידועים כבר ר1(ש) ו-ר2(S), בתצוגה טבלה הנראית כך: r1(S):
r2(S):
נשקול את שני האופרנדים בפעולת ההצטלבות של שני יחסים. לאחר מכן, בעקבות הגדרה זו, הקשר המתקבל r5(S) ייראה כך: r5(S) = r1(S)\r2(S):
הפעולות הבינאריות הנחשבות הן בסיסיות; פעולות אחרות, מורכבות יותר, מבוססות עליהן. 2. פעולות מוצר קרטזי ושילוב טבעי פעולת המוצר הקרטזיאני ופעולת ההצטרפות הטבעית הן פעולות בינאריות מסוג המוצר ומבוססות על פעולת האיחוד של שני יחסים שדיברנו עליה קודם לכן. למרות שהפעולה של פעולת המוצר הקרטזיאני עשויה להיראות מוכרת לרבים, בכל זאת נתחיל בפעולת המוצר הטבעי, שכן מדובר במקרה כללי יותר מהפעולה הראשונה. אז, שקול את פעולת ההצטרפות הטבעית. יש לציין מיד שהאופרנדים של פעולה זו יכולים להיות קשרים עם סכמות שונות, בניגוד לשלוש הפעולות הבינאריות של איחוד, צומת ושינוי שם. אם ניקח בחשבון שני יחסים עם סכימות יחסים שונות r1(S1) ור2(S2), ואז שלהם תרכובת טבעית יהיה קשר חדש r3(S3), שיורכב רק מאותם טופלים של אופרנדים שתואמים בצומת של סכימות יחסים. בהתאם לכך, תכנית היחסים החדשה תהיה גדולה יותר מכל תכנית היחסים של היחסים המקוריים, שכן מדובר בחיבור שלהם, "הדבקה". אגב, טופלים זהים בשני יחסי אופרנד, לפיהם מתרחשת ה"הדבקה" הזו, נקראים ניתן לחיבור. נכתוב את ההגדרה של פעולת החיבור הטבעי בשפת הנוסחה של מערכות ניהול מסד נתונים: r3(S3) = ר1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ ר1 &t(S2) ∈ ר2}; הבה נבחן דוגמה הממחישה היטב את עבודתו של חיבור טבעי, "הדבקה" שלו. תנו שני יחסים r1(S1) ור2(S2), בצורה טבלאית של ייצוג, בהתאמה, שווה: r1(S1):
r2(S2):
אנו רואים שליחסים אלה יש tuples החופפים בצומת של סכמות S1 ו-S2 יחסים. בואו נרשום אותם: 1) tuple {a, 1} של קשר r1(S1) תואם את הטפול {1, x} של היחס r2(S2); 2) טופל {ב, 1} מ-ר1(S1) מתאים גם לטופל {1, x} מ-r2(S2); 3) הטפול {c, 3} תואם את הטפול {3, z}. מכאן, תחת הצטרפות טבעית, הקשר החדש r3(S3) מתקבל על ידי "הדבקה" בדיוק על הטפלים הללו. אז ר3(S3) בתצוגת טבלה ייראה כך: r3(S3) = ר1(S1)xr2(S2):
מסתבר בהגדרה: תכנית S3 אינו עולה בקנה אחד עם תכנית S1, וגם לא עם התוכנית S2, "הדבקנו" את שתי הסכמות המקוריות על ידי צלבים של tuples כדי לקבל את ההצטרפות הטבעית שלהם. הבה נראה באופן סכמטי כיצד מצטרפים tuples בעת יישום פעולת החיבור הטבעי. תן ליחס r1 יש צורה מותנית:
והיחס r2 - נוף:
אז הקשר הטבעי שלהם ייראה כך:
אנו רואים שה"הדבקה" של יחסי-אופרנדים מתרחשת לפי אותה סכמה שהבאנו קודם, בהתחשב בדוגמה. מבצע קשר קרטזיאני הוא מקרה מיוחד של פעולת ההצטרפות הטבעית. ליתר דיוק, כאשר בוחנים את ההשפעה של פעולת המוצר הקרטזיאנית על יחסים, אנו קובעים בכוונה שבמקרה זה נוכל לדבר רק על סכמות יחסים שאינן מצטלבות. כתוצאה מיישום שתי הפעולות, מתקבלים יחסים עם סכמות השווים לאיחוד הסכמות של יחסי אופרנד, רק כל הזוגות האפשריים של הטפולים שלהם נופלים למכפלה הקרטזיאנית של שני יחסים, שכן סכימות האופרנדים לא אמורות בשום מקרה להצטלב. לפיכך, בהתבסס על האמור לעיל, אנו כותבים נוסחה מתמטית לפעולת המוצר הקרטזיאני: r4(S4) = ר1(S1)xr2(S2) = {t(S1 ∪ ס2) | t[S1] ∈ ר1 &t(S2) ∈ ר2}, ס1 ∩ ס2= ∅; כעת נסתכל על דוגמה כדי להראות כיצד תיראה סכימת היחסים המתקבלת בעת יישום פעולת המוצר הקרטזיאני. תנו שני יחסים r1(S1) ו-r2(S2), המוצגים בצורה טבלה כדלקמן: r1(S1):
r2(S2):
אז אנחנו רואים שאף אחד מהטפולים של היחסים r1(S1) ור2(S2), אכן, אינו חופף בצומת שלהם. לכן, ביחס המתקבל r4(S4) כל הזוגות האפשריים של tuples של יחסי האופרנד הראשון והשני ייפלו. לקבל: r4(S4) = ר1(S1)xr2(S2):
השגנו סכימת קשר חדשה r4(S4) לא על ידי "הדבקה" של tuples כמו במקרה הקודם, אלא על ידי ספירה של כל הזוגות השונים האפשריים של tuples שאינם תואמים במפגש בין הסכמות המקוריות. שוב, כמו במקרה של חיבור טבעי, אנו נותנים דוגמה סכמטית לפעולת פעולת המוצר הקרטזיאני. תן ר1 להגדיר באופן הבא:
והיחס r2 נָתוּן:
אז ניתן לייצג את המוצר הקרטזיאני באופן סכמטי באופן הבא:
בדרך זו מתקבל היחס המתקבל בעת יישום פעולת המוצר הקרטזיאני. 3. מאפיינים של פעולות בינאריות מההגדרות שלעיל של הפעולות הבינאריות של איחוד, צומת, הבדל, תוצר קרטזיאני והצטרפות טבעית, עוקבים מאפיינים. 1. המאפיין הראשון, כמו במקרה של פעולות לא נוריות, ממחיש יחס כוח יחסים: 1) עבור פעולת האיגוד: |r1 ∪ר2| ≤ |r1| + |ר2|; 2) עבור פעולת הצומת: |r1 ∩ ר2 | ≤ min(|r1|, |ר2|); 3) עבור פעולת ההבדל: |r1 \r2| ≤ |ר1|; 4) עבור פעולת המוצר הקרטזית: |r1 xr2| = |ר1| |ר2|; 5) לפעולת הצטרפות טבעית: |r1 xr2| ≤ |ר1| |ר2|. יחס הכוחות, כזכור, מאפיין כיצד מספר הטפולים ביחסים משתנה לאחר ביצוע פעולה כזו או אחרת. אז מה אנחנו רואים? כּוֹחַ אסוציאציות שני יחסים ר1 ו-r2 פחות מסכום הקרדינליות של היחסים-אופרנדים המקוריים. למה זה קורה? העניין הוא שכשאתה מתמזג, טופלים תואמים נעלמים, חופפים זה לזה. אז, בהתייחס לדוגמה שחשבנו לאחר שעברנו את הפעולה הזו, אתה יכול לראות שביחס הראשון היו שני טפולים, בשני - שלושה, ובתוצאה - ארבע, כלומר פחות מחמישה (סכום ה- הקרדינליות של היחסים-אופרנדים). לפי הטפול התואם {ב, 2}, יחסים אלה "מודבקים יחד". כוח תוצאה צמתים שני יחסים קטן או שווה לקרדינליות המינימלית של יחסי האופרנד המקוריים. הבה נפנה להגדרה של פעולה זו: רק אותם tuples שנמצאים בשני היחסים הראשוניים נכנסים ליחס המתקבל. המשמעות היא שהקרדינליות של היחס החדש לא יכולה לעלות על הקרדינליות של היחס-אופרנד שמספר הטפולים שלו הוא הקטן מבין השניים. ועוצמת התוצאה יכולה להיות שווה לקרדינליות המינימלית הזו, שכן המקרה תמיד מותר כאשר כל הטפולים של יחס עם קרדינליות נמוכה יותר חופפים לכמה tuples של היחס-אופרנד השני. במקרה של ניתוח הבדלים הכל די טריוויאלי. ואכן, אם כל הטפולים שנמצאים גם ביחס השני "יוחזקו" מהיחס-אופרנד הראשון, אזי מספרם (וכתוצאה מכך גם כוחם) יקטן. במקרה שאף טופלה אחת של היחס הראשון לא תתאים לטופל כלשהו של היחס השני, כלומר, אין מה "להחסיר", כוחו לא יקטן. מעניין, אם המבצע מכפלה קרטזית כוחו של היחס המתקבל שווה בדיוק למכפלת הכוחות של שני יחסי האופרנד. ברור שזה קורה מכיוון שכל הזוגות האפשריים של tuples של היחסים המקוריים נכתבים בתוצאה, ושום דבר אינו נכלל. ולבסוף, המבצע חיבור טבעי מתקבל יחס שכוחו גדול או שווה למכפלת הכוחות של שני היחסים המקוריים. שוב, זה קורה מכיוון שיחסי האופרנד "מודבקים יחד" על ידי tuples תואמים, ואלה שאינם תואמים אינם נכללים מהתוצאה לחלוטין. 2. מאפיין אי-פוטנציה: 1) עבור פעולת האיחוד: r ∪ r = r; 2) לפעולת הצומת: r ∩ r = r; 3) עבור פעולת ההבדל: r \ r ≠ r; 4) עבור פעולת המוצר הקרטזיאני (במקרה הכללי, הנכס אינו ישים); 5) עבור פעולת החיבור הטבעי: r x r = r. מעניין לציין כי תכונת האידמפוטנציה אינה נכונה עבור כל הפעולות הנ"ל, ועבור פעולת המוצר הקרטזיאני, היא אינה ישימה כלל. ואכן, אם תשלבו, תצטלב או תחבר באופן טבעי כל קשר עם עצמו, הוא לא ישתנה. אבל אם מחסירים מיחס השווה לו בדיוק, התוצאה תהיה יחס ריק. 3. מאפיין קומוטטיבי: 1) עבור פעולת האיגוד: r1 ∪ר2 M. 492 ∪ר1; 2) עבור פעולת הצומת: r ∩ r = r ∩ r; 3) עבור פעולת ההבדל: r1 \r2 ≠r2 \r1; 4) עבור פעולת המוצר הקרטזית: r1 xr2 M. 492 xr1; 5) לפעולת הצטרפות טבעית: r1 xr2 M. 492 xr1. מאפיין הקומוטטיביות מתקיים עבור כל הפעולות מלבד פעולת ההפרש. קל להבין זאת, מכיוון שההרכב שלהם (טפולים) אינו משתנה מסידור מחדש של יחסים במקומות. וכאשר מיישמים את פעולת ההבדל, חשוב איזה מיחסי האופרנדים בא קודם, כי זה תלוי אילו tuples של איזה יחס יילקחו כהתייחסות, כלומר, עם אילו tuples tuples אחרים יושוו להדרה. 4. מאפיין אסוציאטיביות: 1) עבור פעולת האיגוד: (r1 ∪ר2) ∪ ר3 M. 491 ∪(ר2 ∪ר3); 2) עבור פעולת הצומת: (r1 ∩ ר2)∩ר3 M. 491 ∩ (ר2 ∩ ר3); 3) עבור פעולת ההבדל: (r1 \r2)\r3 ≠r1 \ (ר2 \r3); 4) עבור פעולת המוצר הקרטזית: (r1 xr2)xr3 M. 491 x(r2 xr3); 5) לפעולת הצטרפות טבעית: (r1 xr2)xr3 M. 491 x(r2 xr3). ושוב אנו רואים שהנכס מבוצע עבור כל הפעולות מלבד פעולת ההפרש. זה מוסבר באותו אופן כמו במקרה של החלת מאפיין הקומוטטיביות. בגדול, לפעולות של איחוד, צומת, שוני והצטרפות טבעית לא אכפת באיזה סדר נמצאים יחסי האופרנד. אבל כש"לוקחים" מערכות יחסים זה מזה, הסדר משחק תפקיד דומיננטי. בהתבסס על המאפיינים וההיגיון לעיל, נוכל להסיק את המסקנה הבאה: שלושת המאפיינים האחרונים, דהיינו תכונת האי-דמוטנטיות, הקומוטטיביות והאסוציאטיביות, נכונים לכל הפעולות שחשבנו, למעט פעולת ההבדל של שני יחסים , שכלל לא התקיים לגביו אף אחד משלושת הנכסים שצוינו, ורק במקרה אחד נמצא שהנכס אינו מתאים. 4. אפשרויות תפעול חיבור שימוש כבסיס בפעולות האנרריות של בחירה, השלכה, שינוי שמות ופעולות בינאריות של איחוד, צומת, הבדל, תוצר קרטזי והצטרפות טבעית שנחשבו קודם לכן (כולן נקראות בדרך כלל פעולות חיבור), נוכל להציג פעולות חדשות שנגזרו באמצעות המושגים וההגדרות שלעיל. פעילות זו נקראת קומפילציה. הצטרפות לאפשרויות הפעולה. הגרסה הראשונה כזו של פעולות הצטרפות היא הפעולה חיבור פנימי בהתאם למצב החיבור שצוין. פעולת החיבור הפנימי, לפי תנאי ספציפי כלשהו, מוגדרת כפעולה נגזרת מפעולות המוצר והבחירה הקרטזית. אנו כותבים את הגדרת הנוסחה של פעולה זו: r1(S1) איקס P r2(S2) = σ (ר1 xr2), ש1 ∩ ס2 = ∅; כאן P = P<S1 ∪ ס2> - תנאי שהוטל על איחוד שתי תוכניות של היחסים-אופרנדים המקוריים. לפי תנאי זה נבחרים tuples מתוך היחסים r1 ו-r2 לתוך היחס שנוצר. שים לב שניתן להחיל את פעולת ההצטרפות הפנימית על קשרים עם סכימות קשרים שונות. תוכניות אלה יכולות להיות כל אחת, אבל בשום מקרה הן לא צריכות להצטלב. הטפולים של אופרנדים-יחסים המקוריים שהם תוצאה של פעולת החיבור הפנימי נקראים tuples הניתנים לחיבור. כדי להמחיש חזותית את פעולת פעולת החיבור הפנימי, ניתן את הדוגמה הבאה. תנו לנו שני יחסים r1(S1) ור2(S2) עם סכימות יחסים שונות: r1(S1):
r2(S2):
הטבלה הבאה תיתן את התוצאה של יישום פעולת החיבור הפנימי על התנאי P = (b1 = b2). r1(S1) איקס P r2(S2):
אז, אנו רואים שה"הדבקה" של שתי הטבלאות המייצגות את הקשר באמת התרחשה בדיוק עבור אותם tuples שבהם מתקיים התנאי של פעולת ההצטרפות הפנימית P = (b1 = b2). כעת, בהתבסס על פעולת ההצטרפות הפנימית שכבר הוצגה, אנו יכולים להציג את הפעולה חיבור חיצוני שמאלי и חיבור חיצוני ימני. בואו נסביר. התוצאה של הפעולה שמאלה את החיבור החיצוני היא תוצאה של החיבור הפנימי, שהושלם עם tuples בלתי ניתנים לחיבור של אופרנד יחס המקור השמאלי. באופן דומה, התוצאה של פעולת צירוף חיצוני ימני מוגדרת כתוצאה של פעולת צירוף פנימי, שהושלמה עם tuples בלתי ניתנים לחיבור של אופרנד יחס המקור בצד ימין. השאלה כיצד מתחדשים היחסים הנובעים של פעולות החיבורים החיצוניים השמאלי והימני צפויה למדי. טפולים של אופרנד יחס אחד משלימים על הסכימה של אופרנד יחס אחר ערכים אפסים. ראוי לציין שפעולות ההצטרפות החיצונית השמאלית והימנית המוכנסות בדרך זו הן פעולות נגזרות מפעולת ההצטרפות הפנימית. כדי לרשום את הנוסחאות הכלליות לפעולות החיבור החיצוני השמאלי והימני, נבצע כמה קונסטרוקציות נוספות. תנו לנו שני יחסים r1(S1) ור2(S2) עם סכמות שונות של יחסים S1 ו-S2, שאינם מצטלבים זה את זה. מכיוון שכבר קבענו שפעולות החיבור הפנימי השמאלי והימני הן נגזרות, נוכל לקבל את נוסחאות העזר הבאות לקביעת פעולת החיבור החיצוני השמאלי: 1) ר3 (S2 ∪ ס1) ≔ r1(S1) איקס Pr2(S2); r 3 (S2 ∪ ס1) הוא פשוט תוצאה של החיבור הפנימי של היחסים r1(S1) ור2(S2). החיבור החיצוני השמאלי הוא פעולה נגזרת של החיבור הפנימי, וזו הסיבה שאנו מתחילים את הבנייה שלנו איתו; 2) ר4(S1) ≔ r 3(S2 ∪S1) [ס1]; לפיכך, בעזרת פעולת הקרנה לא-נארית, בחרנו את כל הטפולים הניתנים לחיבור של אופרנד היחס ההתחלתי השמאלי r1(S1). התוצאה מסומנת r4(S1) לנוחות השימוש; 3) ר5 (S1) ≔ r1(S1)\r4(S1); כאן ר1(S1) הם כולם tuples של יחס המקור השמאלי-אופרנד, ו-r4(S1) - tuples משלו, רק מחובר. לפיכך, באמצעות הפעולה הבינארית של ההפרש, ביחס ל-r5(S1) קיבלנו את כל הטפולים שאינם ניתנים לחיבור של יחס האופרנד השמאלי; 4) ר6(S2)≔{∅(S2)}}; {∅(S2)} הוא קשר חדש עם הסכימה (S2) מכיל רק tuple אחד, ומורכב מערכי Null. מטעמי נוחות, ציינו את היחס הזה כ-r6(S2); 5) ר7 (S2 ∪ ס1) ≔ r5(S1)xr6(S2); כאן לקחנו את הטפולים הלא מחוברים של יחס האופרנד השמאלי (r5(S1)) והשלים אותם על סכמת היחס השני-אופרנד S2 ערכים אפסים, כלומר קרטזיאני הכפיל את היחס המורכב מאותם tuples בלתי ניתנים לחיבור ביחס r6(S2) המוגדר בפסקה רביעית; 6) ר1(S1) →x P r2(S2) ≔ (ר1 x P r2) ∪ ר7 (S2 ∪ ס1); זה מה שזה חיבור חיצוני שמאלי, המתקבל, כפי שניתן לראות, על ידי איחוד התוצר הקרטזיאני של היחסים-אופרנדים המקוריים r1 ו-r2 ויחסים ר7 (S2 ∪ S1) כהגדרתו בסעיף XNUMX. כעת יש לנו את כל החישובים הדרושים כדי לקבוע לא רק את פעולת החיבור החיצוני השמאלי, אלא באנלוגיה ולקבוע את פעולת החיבור החיצוני הימני. כך: 1) פעולה חיבור חיצוני שמאלי בצורה קפדנית זה נראה כך: r1(S1) →x P r2(S2) ≔ (ר1 x P r2) ∪ [(ר1 \ (ר1 x P r2) [ס1]) x {∅(S2)}]; 2) פעולה חיבור חיצוני ימני מוגדר בצורה דומה לפעולת החיבור החיצוני השמאלי ויש לו את הצורה הבאה: r1(S1) →x P r2(S2) ≔ (ר1 x P r2) ∪ [(ר2 \ (ר1 x P r2) [ס2]) x {∅(S1)}]; לשתי הפעולות הנגזרות הללו יש רק שני מאפיינים שכדאי להזכיר. 1. מאפיין של קומוטטיביות: 1) עבור פעולת ההצטרפות החיצונית השמאלית: r1(S1) →x P r2(S2) ≠ ר2(S2) →x P r1(S1); 2) לפעולת ההצטרפות החיצונית הימנית: r1(S1) ←x P r2(S2) ≠ ר2(S2) ←x P r1(S1) אז, אנו רואים שתכונת הקומוטטיביות אינה מסופקת עבור פעולות אלה במונחים כלליים, אך הפעולות של החיבורים החיצוניים השמאלי והימני הפוכים זה לזה, כלומר, הדבר הבא נכון: 1) עבור פעולת ההצטרפות החיצונית השמאלית: r1(S1) →x P r2(S2) = ר2(S2) →x P r1(S1); 2) לפעולת ההצטרפות החיצונית הימנית: r1(S1) ←x P r2(S2) = ר2(S2) ←x Pr1(S1). 2. המאפיין העיקרי של פעולות חיבור חיצוני שמאל וימין הוא שהן מאפשרות להתאושש אופרנד היחס הראשוני בהתאם לתוצאה הסופית של פעולת צירוף מסוימת, כלומר, מתבצעות הפעולות הבאות: 1) עבור פעולת ההצטרפות החיצונית השמאלית: r1(S1) = (r1 →x P r2) [ס1]; 2) לפעולת ההצטרפות החיצונית הימנית: r2(S2) = (ר1 ←x P r2) [ס2]. לפיכך, אנו רואים שניתן לשחזר את היחס-אופרנד המקורי הראשון מהתוצאה של פעולת החיבור שמאלה-ימין, וליתר דיוק, על ידי החלה על התוצאה של החיבור הזה (r1 xr2) הפעולה האנורית של ההשלכה על התוכנית S1, [ס1]. ובאופן דומה, ניתן לשחזר את היחס-אופרנד המקורי השני על ידי החלת החיבור החיצוני הימני (r1 xr2) הפעולה האנורית של ההשלכה על סכימת היחס S2. בוא ניתן דוגמה לבחינה מפורטת יותר של פעולת פעולות החיבורים החיצוניים השמאלי והימני. הבה נציג את היחסים המוכרים כבר r1(S1) ור2(S2) עם סכימות יחסים שונות: r1(S1):
r2(S2):
Nonjoinable tuple של יחס שמאלי-אופרנד r2(S2) הוא טופל {ד, 4}. בעקבות ההגדרה, הם צריכים להשלים את תוצאת החיבור הפנימי של שני היחסים-אופרנדים הראשוניים. מצב הצטרפות פנימי של יחסים r1(S1) ור2(S2) אנחנו גם משאירים אותו הדבר: P = (b1 = b2). ואז תוצאת הניתוח חיבור חיצוני שמאלי תהיה הטבלה הבאה: r1(S1) →x P r2(S2):
ואכן, כפי שאנו יכולים לראות, כתוצאה מהשפעת פעולת החיבור השמאלי החיצוני, תוצאת פעולת החיבור הפנימי התחדשה בטופלים בלתי ניתנים לחיבור של שמאל, כלומר, במקרה שלנו, היחס הראשון- אופרנד. חידוש ה-tuple על סכמה של אופרנד יחס המקור השני (הימני), בהגדרה, התרחש בעזרת ערכי Null. ובדומה לתוצאה חיבור חיצוני ימני באותו כמו קודם, התנאי P = (b1 = b2) של היחסים-אופרנדים המקוריים r1(S1) ור2(S2) היא הטבלה הבאה: r1(S1) ←x P r2(S2):
אכן, במקרה זה, יש למלא את התוצאה של פעולת ההצטרפות הפנימית בטופלים בלתי ניתנים לחיבור של הימין, במקרה שלנו, אופרנד היחס הראשוני השני. tuple כזה, כפי שלא קשה לראות, ביחס השני r2(S2) אחד, כלומר {2, y}. לאחר מכן, אנו פועלים על פי הגדרת הפעולה של החיבור החיצוני הימני, משלימים את הטפול של האופרנד הראשון (השמאלי) על סכמת האופרנד הראשון עם ערכי Null. לבסוף, בואו נסתכל על הגרסה השלישית של פעולות ההצטרפות לעיל. פעולת הצטרפות חיצונית מלאה. פעולה זו יכולה להיחשב לא רק כפעולה הנגזרת מפעולות הצטרפות פנימיות, אלא גם כאיחוד של פעולות הצטרפות שמאל וימין חיצונית. פעולת הצטרפות חיצונית מלאה מוגדר כתוצאה של השלמת אותו צירוף פנימי (כמו במקרה של ההגדרה של צירוף שמאל וימין חיצוני) עם tuples בלתי ניתנים לחיבור של יחסי אופרנד ראשוניים של שמאל וימין. בהתבסס על הגדרה זו, אנו נותנים את הצורה הנוסחתית של הגדרה זו: r1(S1) ↔x P r2(S2) = (ר1 →x P r2) ∪ (ר1 ←x P r2); לפעולת החיבור החיצוני המלא יש גם תכונה דומה לזו של פעולות החיבור החיצוני השמאלי והימני. רק בשל האופי ההדדי המקורי של פעולת ההצטרפות החיצונית המלאה (אחרי הכל, היא הוגדרה כאיחוד של פעולות ההצטרפות החיצונית השמאלית והימנית), היא מבצעת נכס קומוטטיביות: r1(S1) ↔x P r2(S2)=ר2(S2) ↔ x P r1(S1); וכדי להשלים את בחינת האפשרויות לפעולות הצטרפות, נתבונן בדוגמה הממחישה את פעולתה של פעולת הצטרפות חיצונית מלאה. אנו מציגים שני יחסים r1(S1) ור2(S2) ותנאי ההצטרפות. לתת r1(S1)
r2(S2):
ותן התנאי של חיבור יחסים ר1(S1) ור2(S2) יהיה: P = (b1 = b2), כמו בדוגמאות הקודמות. ואז התוצאה של פעולת ההצטרפות החיצונית המלאה של יחסי r1(S1) ור2(S2) לפי התנאי P = (b1 = b2) תהיה הטבלה הבאה: r1(S1) ↔x P r2(S2):
אז, אנו רואים שפעולת ההצטרפות החיצונית המלאה מצדיקה בבירור את הגדרתו כאיחוד התוצאות של פעולות ההצטרפות החיצונית של שמאל וימין. היחס המתקבל של פעולת ההצטרפות הפנימית משלימים על ידי tuples בלתי ניתנים לחיבור בו-זמנית כמו שמאל (ראשון, r1(S1)), וימין (שני, ר2(S2)) של היחס-אופרנד המקורי. 5. פעולות נגזרות לכן, שקלנו גרסאות שונות של פעולות צירוף, כלומר פעולות של צירוף פנימי, שמאלי, ימין וחיבור חיצוני מלא, שהן נגזרות של שמונה הפעולות המקוריות של האלגברה ההתייחסותית: פעולות אונאריות של בחירה, השלכה, שינוי שם ופעולות בינאריות של איחוד, צומת, הבדל, מוצר קרטזיאני וחיבור טבעי. אבל גם בין הפעולות המקוריות הללו יש דוגמאות לפעולות נגזרות. 1. למשל, מבצע צמתים שני יחסים היא נגזרת של פעולת ההפרש של אותם שני יחסים. בואו נראה את זה. ניתן לבטא את פעולת הצומת בנוסחה הבאה: r1(S)∩r2(S) = r1 \r1 \r2 או, שנותן את אותה תוצאה: r1(S)∩r2(S) = r2 \r2 \r1; 2. דוגמה נוספת, הנגזרת של הפעולה הבסיסית משמונה הפעולות המקוריות היא הפעולה חיבור טבעי. בצורתה הכללית ביותר, פעולה זו נגזרת מהפעולה הבינארית של התוצר הקרטזיאני ומהפעולות האנרריות של בחירה, השלכה ושינוי שמות של תכונות. אולם, בתורו, פעולת ההצטרפות הפנימית היא פעולה נגזרת של אותה פעולה של תוצר היחסים הקרטזיאני. לכן, כדי להראות שפעולת הצטרפות טבעית היא פעולה נגזרת, שקול את הדוגמה הבאה. נשווה את הדוגמאות הקודמות לפעולות חיבור טבעי ופנימי. תנו לנו שני יחסים r1(S1) ור2(S2) שיפעלו כאופרנדים. הם שווים: r1(S1):
r2(S2):
כפי שכבר קיבלנו קודם לכן, התוצאה של פעולת ההצטרפות הטבעית של יחסים אלה תהיה טבלה בצורה הבאה: r3(S3) ≔ r1(S1)xr2(S2):
והתוצאה של החיבור הפנימי של אותם יחסים r1(S1) ור2(S2) לפי התנאי P = (b1 = b2) תהיה הטבלה הבאה: r4(S4) ≔ r1(S1) איקס P r2(S2):
הבה נשווה את שתי התוצאות הללו, היחסים החדשים שנוצרו r3(S3) ור4(S4). ברור שפעולת ההצטרפות הטבעית מתבטאת באמצעות פעולת ההצטרפות הפנימית, אבל, הכי חשוב, עם תנאי הצטרפות של צורה מיוחדת. נכתוב נוסחה מתמטית המתארת את פעולת פעולת ההצטרפות הטבעית כנגזרת של פעולת ההצטרפות הפנימית. r1(S1)xr2(S2) = { ρ<ϕ1>ר1 x E ρ< ϕ2>r2[ס1 ∪ ס2], איפה E - מצב קישוריות tuples; E= ∀a ∈S1 ∩ ס2 [IsNull(b1) & IsNull(2) ∪b1 = b2]; b1 = ϕ1 (שם(א)), ב2 = ϕ2 (תן שם ל)); הנה אחד מהם שינוי שמות של פונקציות ϕ1 זהה, ועוד פונקציית שינוי שם (כלומר, ϕ2) משנה את שמות התכונות שבהן הסכמות שלנו מצטלבות. תנאי הקישוריות E עבור tuples כתוב בצורה כללית, תוך התחשבות בהתרחשות אפשרית של ערכי Null, מכיוון שפעולת החיבור הפנימי (כפי שהוזכר לעיל) היא פעולה נגזרת מפעולת המכפלה הקרטזית של שני יחסים ו- פעולת בחירה לא נורית. 6. ביטויים של אלגברה יחסית הבה נראה כיצד ניתן להשתמש בביטויים ובפעולות שנחשבו בעבר של אלגברה רלציונית בפעולה המעשית של מסדי נתונים שונים. תנו, למשל, לרשותנו קטע ממאגר מידע מסחרי כלשהו: ספקים (קוד ספק, שם הספק, עיר הספק); כלים (קוד כלי, שם הכלי,...); משלוחים (קוד ספק, קוד חלק); שמות התכונות המסומנים בקו תחתון[1] הם תכונות מפתח (כלומר, מזהות), כל אחת ביחס שלה. נניח שאנו, כמפתחי מאגר מידע זה ושומרי המידע בנושא זה, מצווים לקבל את שמות הספקים (שם הספק) ומיקומם (עיר הספקים) במקרה בו ספקים אלו אינם מספקים כלים שם כללי "צבת". על מנת לקבוע את כל הספקים שעומדים בדרישה זו במסד הנתונים הגדול ביותר שלנו, אנו כותבים כמה ביטויים של אלגברה יחסית. 1. אנו יוצרים חיבור טבעי של יחסי "ספקים" ו"אספקה" על מנת להתאים לכל ספק את הקודים של החלקים המסופקים על ידו. הקשר החדש - תוצאה של יישום פעולת ההצטרפות הטבעית - לנוחות יישום נוסף, יסומן ב-r1. ספקים x אספקה ≔ r1 (קוד ספק, שם ספק, עיר ספק, בסוגריים, רשמנו את כל התכונות של היחסים המעורבים בפעולת הצטרפות טבעית זו. אנו יכולים לראות שהתכונה "מזהה ספק" משוכפלת, אך ברשומת סיכום העסקאות, כל שם תכונה צריך להופיע פעם אחת בלבד, כלומר: ספקים x אספקה ≔ r1 (קוד ספק, שם ספק, עיר ספק, קוד מכשיר); 2. שוב נוצר קשר טבעי, רק שהפעם הקשר המתקבל בפסקה א' והקשר מכשירים. אנו עושים זאת על מנת להתאים את שם הכלי הזה לכל קוד כלי שהתקבל בפסקה הקודמת. r1 x כלים [קוד כלי, שם כלי] ≔ r2 (קוד ספק, שם ספק, עיר ספק, התוצאה המתקבלת תסומן ב-r2, מאפיינים כפולים אינם נכללים: r1 x כלים [קוד כלי, שם כלי] ≔ r2 (קוד ספק, שם ספק, עיר ספק, קוד מכשיר, שם מכשיר); שים לב שאנו לוקחים רק שתי תכונות מהקשר הכלים: "קוד כלי" ו"שם הכלי". לשם כך, אנו, כפי שניתן לראות מהסימון של היחס r2, החיל את פעולת ההקרנה האנוארית: כלים [קוד כלי, שם כלי], כלומר, אם היחס הכלים הוצג כטבלה, התוצאה של פעולת הקרנה זו תהיה שתי העמודות הראשונות עם הכותרות "קוד כלי" ו"כלי שם" בהתאמה". מעניין לציין ששני השלבים הראשונים שכבר שקלנו הם כלליים למדי, כלומר, ניתן להשתמש בהם כדי ליישם כל בקשה אחרת. אבל שתי הנקודות הבאות, בתורן, מייצגות צעדים קונקרטיים להשגת המשימה הספציפית שהוצבה לפנינו. 3. כתוב פעולת בחירה חד-משמעית לפי התנאי <"שם הכלי" = "צבת"> ביחס ליחס r2שהושג בפסקה הקודמת. ואנחנו, בתורם, מיישמים את פעולת ההשלכה האנוארית [קוד ספק, שם ספק, עיר ספק] על התוצאה של פעולה זו כדי לקבל את כל הערכים של התכונות הללו, מכיוון שאנו צריכים לקבל מידע זה על סמך להזמין. אז: (σ<שם הכלי = "צבת"> r2) [קוד ספק, שם ספק, עיר ספק] ≔ r3 (קוד ספק, שם ספק, עיר ספק, קוד כלי, שם כלי). ביחס המתקבל, מסומן על ידי r3, התברר כי רק אותם ספקים (עם כל נתוני הזיהוי שלהם) מספקים כלים בעלי השם הגנרי "צבת". אבל מכוח הצו צריך לייחד את אותם ספקים שלהפך, לא מספקים כלים כאלה. לכן, בואו נעבור לשלב הבא באלגוריתם שלנו ונכתוב את הביטוי האחרון של האלגברה ההתייחסותית, שייתן לנו את המידע שאנו מחפשים. 4. ראשית, בואו נעשה את ההבדל בין היחס "ספקים" ליחס r3, ולאחר החלת פעולה בינארית זו, אנו מיישמים את פעולת ההשלכה האנוארית על התכונות "שם הספק" ו"עיר הספק". (ספקים\r3) [שם הספק, עיר הספק] ≔ r4 (קוד ספק, שם ספק, עיר ספק); התוצאה מסומנת r4, יחס זה כלל רק את אותם tuples של יחס "ספקים" המקורי התואמים את מצב ההזמנה שלנו. אז, הראינו איך, באמצעות ביטויים ופעולות של אלגברה רלציונית, אתה יכול לבצע כל מיני פעולות עם מסדי נתונים שרירותיים, לבצע הזמנות שונות וכו '. הרצאה מס' 6. שפת SQL תחילה נתן מעט רקע היסטורי. שפת SQL, שנועדה לקיים אינטראקציה עם מסדי נתונים, הופיעה באמצע שנות ה-1970. (פרסומים ראשונים מתוארכים לשנת 1974) והוא פותח על ידי IBM כחלק מפרויקט ניסיוני של מערכת ניהול מסדי נתונים יחסיים. השם המקורי של השפה הוא SEQUEL (Structured English שפת שאילתה) - שיקף רק חלקית את המהות של שפה זו. בתחילה, מיד לאחר המצאתה ובתקופת הפעילות העיקרית של שפת ה-SQL, שמה היה קיצור של הביטוי Structured Query Language, המתורגם כ"שפת שאילתות מובנית". כמובן שהשפה התמקדה בעיקר בניסוח שאילתות למאגרי מידע יחסיים נוחים ומובנים למשתמשים. אבל, למעשה, כמעט מההתחלה, זו הייתה שפת מסד נתונים שלמה, שסיפקה, בנוסף לאמצעי ניסוח שאילתות ותפעול מסדי נתונים, את התכונות הבאות: 1) אמצעים להגדרה ולתפעל את סכימת מסד הנתונים; 2) אמצעים להגדרת אילוצי יושרה וטריגרים (שיוזכר בהמשך); 3) אמצעים להגדרת תצוגות מסד נתונים; 4) אמצעים להגדרת מבני שכבה פיזית התומכים בביצוע יעיל של בקשות; 5) אמצעים להרשאת גישה לקשרים ושדותיהם. השפה חסרה את האמצעים לסנכרון מפורש של גישה לאובייקטי מסד נתונים מהצד של טרנזקציות מקבילות: כבר מההתחלה הייתה ההנחה שהסנכרון הדרוש מבוצע באופן מרומז על ידי מערכת ניהול מסד הנתונים. נכון לעכשיו, SQL אינו עוד קיצור, אלא שם של שפה עצמאית. כמו כן, כיום, שפת השאילתות המובנית מיושמת בכל מערכות ניהול מסדי נתונים יחסיים מסחריים וכמעט בכל DBMS שלא התבססו במקור על גישה יחסית. כל החברות היצרניות טוענות שהטמעתן תואמת את תקן SQL, ולמעשה הדיאלקטים המיושמים של שפת השאילתות המובנית קרובים מאוד. זה לא הושג מיד. תכונה של רוב מערכות ניהול מסדי הנתונים המסחריות המודרניות המקשה על השוואה בין ניבים קיימים של SQL היא היעדר תיאור אחיד של השפה. בדרך כלל, התיאור מפוזר במדריכים שונים ומעורב עם תיאור של תכונות שפה ספציפיות למערכת שאינן קשורות ישירות לשפת השאילתה המובנית. עם זאת, ניתן לומר כי הסט הבסיסי של הצהרות SQL, לרבות הצהרות לקביעת סכימת מסד הנתונים, אחזור ותפעול נתונים, הרשאת גישה לנתונים, תמיכה בהטמעת SQL בשפות תכנות והצהרות SQL דינמיות, מבוססת היטב בתחום המסחרי. יישומים ופחות או יותר תואם את התקן. עם הזמן והעבודה על שפת השאילתות המובנית, ניתן היה להשיג סטנדרט לסטנדרטיזציה ברורה של התחביר והסמנטיקה של הצהרות אחזור נתונים, מניפולציה של נתונים ותיקון אילוצי שלמות מסד נתונים. צוינו אמצעים להגדרת המפתחות הראשיים והזרים של קשרים ומה שנקרא אילוצי בדיקת תקינות, שהם תת-קבוצה של אילוצי תקינות SQL שנבדקו מיד. הכלים להגדרת מפתחות זרים מקלים על ניסוח הדרישות של מה שנקרא השלמות ההתייחסותית של מסדי נתונים (עליהם נדבר בהמשך). דרישה זו, הנפוצה במסדי נתונים יחסיים, יכולה להתגבש גם על בסיס המנגנון הכללי של אילוצי שלמות SQL, אך הניסוח המבוסס על הרעיון של מפתח זר הוא פשוט ומובן יותר. אז, בהתחשב בכל זה, נכון לעכשיו, שפת השאילתה המובנית היא לא רק שם של שפה אחת, אלא שם של מחלקה שלמה של שפות, שכן, למרות הסטנדרטים הקיימים, ניבים שונים של שפת השאילתה המובנית מיושמים במערכות שונות לניהול מסדי נתונים, שכמובן יש להן בסיס אחד משותף. 1. ההצהרה Select היא ההצהרה הבסיסית של שפת השאילתה המובנית את המקום המרכזי בשפת השאילתות המובנית ב-SQL תופסת הצהרת Select, המיישמת את הפעולה המבוקשת ביותר בעבודה עם מסדי נתונים - שאילתות. הצהרת Select מעריכה הן ביטויי אלגברה יחסיים והן פסאודו-יחסים. בקורס זה נשקול את היישום רק של הפעולות האנריות והבינאריות של אלגברה רלציונית שכבר כיסינו, כמו גם יישום של שאילתות באמצעות מה שנקרא תת-שאילתות. אגב, יש לציין שבמקרה של עבודה עם פעולות אלגברה רלציונליות, עשויות להופיע כפולות כפולות ביחסים המתקבלים. אין איסור מוחלט על נוכחות של שורות כפולות ביחסים בכללי שפת השאילתה המובנית (בניגוד לאלגברה רלציונית רגילה), ולכן אין צורך להוציא כפילויות מהתוצאה. אז בואו נסתכל על המבנה הבסיסי של הצהרת Select. זה די פשוט וכולל את ביטויי החובה הסטנדרטיים הבאים: בחר ... מ... איפה... ; במקום האליפסיס בכל שורה צריכים להיות יחסים, תכונות ותנאים של מסד נתונים מסוים ומשימות עבורו. במקרה הכללי ביותר, מבנה ה-Select הבסיסי צריך להיראות כך: בחר בחר כמה תכונות מ ממערכת יחסים כזו איפה עם תנאים כאלה ואחרים לדגימת tuples לפיכך, אנו בוחרים תכונות מסכימת היחסים (כותרות של עמודות מסוימות), תוך ציון מאילו מערכות יחסים (וכנראה, עשויות להיות כמה) אנו מבצעים את הבחירה שלנו ולבסוף, על סמך אילו תנאים אנו מפסיקים את הבחירה שלנו. טופלים מסוימים. חשוב לציין שהפניות לתכונות נעשות באמצעות שמותיהן. כך מתקבל הדברים הבאים אלגוריתם עבודה הצהרת Select הבסיסית הזו: 1) זכורים התנאים לבחירת tuples מהיחס; 2) נבדק אילו tuples עומדים במאפיינים שצוינו. טופלים כאלה זכורים; 3) התכונות המפורטות בשורה הראשונה של המבנה הבסיסי של הצהרת Select עם הערכים שלהן הן פלט. (אם נדבר על הצורה הטבלאית של הקשר, יוצגו אותן עמודות של הטבלה, שכותרותיהן היו רשומות כתכונות הכרחיות; כמובן שהעמודות לא יוצגו במלואן, בכל אחת מהן רק אותם tuples שעומד בתנאים הנקובים יישארו.) שקול דוגמה. הבה ניתן לנו את היחס הבא r1, כקטע ממסד נתונים כלשהו של חנות ספרים:
נניח שניתן לנו גם את הביטוי הבא עם המשפט Select: בחר שם הספר, מחבר הספר מ r1 איפה מחיר ספר > 200; התוצאה של אופרטור זה תהיה שבר הטפול הבא: (טלפון נייד, ש' קינג). (בהמשך, נשקול דוגמאות רבות של יישומי שאילתות באמצעות מבנה בסיסי זה ונלמד את היישום שלו בפירוט רב.) 2. פעולות Unary בשפת השאילתה המובנית בסעיף זה, נשקול כיצד הפעולות האנריות המוכרות כבר של בחירה, הקרנה ושינוי שמות מיושמות בשפת השאילתה המובנית באמצעות האופרטור Select. חשוב לציין שאם קודם לכן יכולנו לעבוד רק עם פעולות בודדות, אז אפילו אופרטור Select בודד במקרה הכללי מאפשר לנו להגדיר ביטוי אלגברה יחסי שלם, ולא רק פעולה אחת בודדת. אז, הבה נמשיך ישירות לניתוח הייצוג של פעולות אוניאריות בשפה של שאילתות מובנות. 1. פעולת דגימה. פעולת הבחירה ב-SQL מיושמת על ידי הצהרת Select בצורה הבאה: בחר כל התכונות מ שם הקשר איפה תנאי בחירה; כאן, במקום לכתוב "כל התכונות", אתה יכול להשתמש בסימן "*". בתיאוריית שפת שאילתות מובנית, סמל זה אומר בחירת כל התכונות מסכימת היחסים. תנאי הבחירה כאן (ובכל ההטמעות האחרות של פעולות) כתוב כביטוי לוגי עם חיבורים סטנדרטיים לא (לא), ו-(ו), או (או). תכונות מערכת יחסים נקראות בשמות שלהן. שקול דוגמה. הבה נגדיר את ערכת היחסים הבאה: ביצועים אקדמיים (מספר ספר ציונים, סמסטר, קוד נושא, דירוג, תאריך); כאן, כפי שהוזכר קודם לכן, התכונות המסומנות בקו תחתון יוצרות את מפתח היחס. הבה נרכיב הצהרת בחירה מהצורה הבאה, המיישמת את פעולת הבחירה האנורית: בחר* מתוך ביצועים אקדמיים כאשר ספר ציונים מס' = 100 וסמסטר = 6; ברור שכתוצאה מהצהרה זו, המכונה תציג את ההתקדמות של סטודנט עם מספר שיא מאה עבור הסמסטר השישי. 2. פעולת הקרנה. פעולת ההקרנה ב-Structured Query Language קלה אפילו יותר ליישום מאשר פעולת האחזור. נזכיר כי בעת החלת פעולת ההקרנה, לא נבחרות שורות (כמו בעת החלת פעולת הבחירה), אלא עמודות. לכן, מספיק לרשום את הכותרות של העמודות הרצויות (כלומר, שמות תכונות), מבלי לציין תנאים זרים. בסך הכל, אנו מקבלים אופרטור מהטופס הבא: בחר רשימה של שמות תכונות מ שם הקשר; לאחר החלת משפט זה, המכונה תחזיר את העמודות של טבלת היחסים ששמותיהן צוינו בשורה הראשונה של משפט Select זה. כפי שהזכרנו קודם לכן, אין צורך להוציא שורות ועמודות כפולות מהקשר המתקבל. אבל אם בהזמנה או במשימה נדרש לבטל כפילויות, עליך להשתמש באפשרות מיוחדת של שפת השאילתה המובנית - מובהק. אפשרות זו מגדירה את הביטול האוטומטי של tuples כפולים מהקשר. כאשר אפשרות זו מיושמת, הצהרת הבחירה תיראה כך: בחר רשימה ברורה של שמות תכונות מ שם הקשר; ב-SQL ישנו סימון מיוחד לאלמנטים אופציונליים של ביטויים - סוגריים מרובעים [...]. לכן, בצורתה הכללית ביותר, פעולת ההקרנה תיראה כך: בחר רשימה [מובחנת] של שמות תכונות מ שם הקשר; עם זאת, אם התוצאה של יישום הפעולה מובטחת שלא תכיל כפילויות, או שכפולים עדיין קבילים, אז האפשרות מובהק עדיף לא לפרט כדי לא לבלבל את הרשומה, כלומר מסיבות של ביצועי המפעיל. הבה נבחן דוגמה הממחישה את האפשרות של XNUMX% אמון בהיעדר כפילויות. תינתן תכנית היחסים שכבר ידועה לנו: ביצועים אקדמיים (מספר ספר ציונים, סמסטר, קוד נושא, דירוג, תאריך). תנו להצהרת הבחירה הבאה להינתן: בחר מספר ספר ציונים, סמסטר, קוד נושא מ ביצועים אקדמיים; כאן, קל לראות ששלושת התכונות המוחזרות על ידי האופרטור יוצרות את המפתח של היחס. לכן האופציה מובהק הופך למיותר, כי מובטח שלא יהיו כפילויות. הדבר נובע מדרישה על מפתחות הנקראת אילוץ ייחודי. אנו נשקול את המאפיין הזה בפירוט רב יותר מאוחר יותר, אבל אם התכונה היא מפתח, אז אין בו כפילויות. 3. שינוי שם הפעולה. הפעולה של שינוי שמות של תכונות בשפת השאילתה המובנית היא פשוטה למדי. כלומר, הוא מגולם במציאות על ידי האלגוריתם הבא: 1) ברשימת שמות המאפיינים של הביטוי Select, מופיעות התכונות שיש לשנות את שמותיהם; 2) מילת המפתח המיוחדת כפי שמתווספת לכל תכונה שצוינה; 3) לאחר כל הופעה של המילה as, מצוין שם התכונה המתאימה, אליה יש צורך לשנות את השם המקורי. לפיכך, בהתחשב בכל האמור לעיל, ההצהרה התואמת לפעולת שינוי שמות התכונות תיראה כך: בחר שם תכונה 1 כשם תכונה חדשה 1,... מ שם הקשר; בואו נראה איך האופרטור הזה עובד עם דוגמה. תן לערכת היחסים שכבר מוכרת לנו: ביצועים אקדמיים (מספר ספר ציונים, סמסטר, קוד נושא,דירוג, תאריך); תן לנו סדר לשנות את השמות של כמה תכונות, כלומר, במקום "מספר ספר חשבון" צריך להיות "מספר חשבון" ובמקום "ציון" - "ציון". בוא נרשום איך תיראה הצהרת Select המיישמת את פעולת שינוי השם הזו: בחר ספר רישום כמספר רשומה, סמסטר, קוד נושא, ציון כציון, תאריך מ ביצועים אקדמיים; לפיכך, התוצאה של יישום אופרטור זה תהיה סכימת קשרים חדשה השונה מסכימת הקשר "הישג" המקורית בשמות של שתי תכונות. 3. פעולות בינאריות בשפת שאילתות מובנות בדומה לפעולות אונאריות, גם לפעולות בינאריות יש יישום משלהן בשפת השאילתה המובנית או ב-SQL. אז, בואו נשקול את היישום בשפה זו של הפעולות הבינאריות שכבר עברנו, כלומר, הפעולות של איחוד, צומת, הבדל, תוצר קרטזי, חיבור טבעי, חיבור פנימי ושמאלי, ימין, חיבור חיצוני מלא. 1. פעולת האיגוד. על מנת ליישם את פעולת השילוב של שני קשרים, יש צורך להשתמש בשני אופרטורים Select בו-זמנית, שכל אחד מהם מתאים לאחד מה-relations-אופרנדים המקוריים. וצריך להחיל פעולה מיוחדת על שתי הצהרות Select הבסיסיות הללו התאחדות. בהתחשב בכל האמור לעיל, הבה נכתוב כיצד תיראה פעולת האיחוד תוך שימוש בסמנטיקה של שפת השאילתה המובנית: בחר רשום את שמות התכונות של קשר 1 מ שם קשר 1 התאחדות בחר רשום את שמות התכונות של קשר 2 מ שם יחס 2; חשוב לציין שרשימות שמות המאפיינים של שני מערכות היחסים המצטרפות חייבות להתייחס לתכונות מסוגים תואמים ולהופיע בסדר עקבי. אם דרישה זו לא מתקיימת, לא ניתן למלא את בקשתך והמחשב יציג הודעת שגיאה. אבל מה שמעניין לציין הוא ששמות התכונות עצמם ביחסים האלה יכולים להיות שונים. במקרה זה, היחס המתקבל מקבל את שמות המאפיינים שצוינו במשפט ה-Select הראשון. אתה גם צריך לדעת ששימוש בפעולת האיחוד מונע אוטומטית את כל ה-tuples הכפולים מהקשר המתקבל. לכן, אם אתה צריך שכל השורות הכפולות יישמרו בתוצאה הסופית, במקום פעולת האיחוד, עליך להשתמש בשינוי של הפעולה הזו - הפעולה האיחוד כולו. במקרה זה, הפעולה של שילוב שני יחסים תיראה כך: בחר רשום את שמות התכונות של קשר 1 מ שם קשר 1 האיחוד כולו בחר רשום את שמות התכונות של קשר 2 מ שם יחס 2; במקרה זה, tuples כפולים לא יוסרו מהקשר שנוצר. באמצעות הסימון שהוזכר לעיל עבור אלמנטים ואפשרויות אופציונליות בהצהרות Select, אנו כותבים את הצורה הכללית ביותר של הפעולה של צירוף שני יחסים בשפת השאילתה המובנית: בחר רשום את שמות התכונות של קשר 1 מ שם קשר 1 איחוד [הכל] בחר רשום את שמות התכונות של קשר 2 מ שם יחס 2; 2. פעולת צומת. פעולת ההצטלבות ותפעול ההפרש של שני יחסים בשפת השאילתה המובנית מיושמות באופן דומה (אנו רואים את שיטת הייצוג הפשוטה ביותר, שכן ככל שהשיטה פשוטה יותר, כך היא חסכונית יותר, רלוונטית יותר, ולכן, הכי הרבה בביקוש). אז, ננתח את הדרך ליישם את פעולת הצומת באמצעות של מפתחות. שיטה זו כוללת השתתפות של שני מבני Select, אך הם אינם שווים (כמו בייצוג פעולת האיחוד), אחד מהם הוא, כביכול, "תת-קונסטרוקציה", "תת-מחזור". מפעיל כזה נקרא בדרך כלל שאילתת משנה. אז נניח שיש לנו שתי מערכות יחסים (R1 ור2), מוגדר בערך כך: R1 (מפתח,...) ו R2 (מַפְתֵחַ,...); בעת הקלטת הפעולה הזו, נשתמש גם באפשרות המיוחדת in, שפירושו המילולי "ב" או (כמו במקרה הספציפי הזה) "כלול ב". אז, בהתחשב בכל האמור לעיל, פעולת ההצטלבות של שני יחסים באמצעות שפת השאילתה המובנית תיכתב באופן הבא: בחר * מ R1 איפה מפתח ב (בחר ключ מאת ר2); לפיכך, אנו רואים ששאילתת המשנה במקרה זה תהיה האופרטור בסוגריים. שאילתת משנה זו במקרה שלנו מחזירה רשימה של ערכי מפתח של הקשר R2. וכפועל יוצא מסימון האופרטורים שלנו, מניתוח תנאי הבחירה, רק הטפולות של היחס R ייפלו ליחס המתקבל1, שהמפתח שלו כלול ברשימת המפתחות של היחס R2. כלומר, ביחס הסופי, אם נזכור את הגדרת ההצטלבות של שני יחסים, יישארו רק אותם tuples השייכים לשני היחסים. 3. פעולת הבדל. כפי שהוזכר קודם לכן, הפעולה האנורית של ההבדל בין שני יחסים מיושמת בדומה לפעולת הצומת. כאן, בנוסף לשאילתה הראשית עם האופרטור Select, נעשה שימוש בשאילתת עזר שנייה - מה שנקרא תת-שאילתה. אבל בניגוד ליישום הפעולה הקודמת, בעת יישום פעולת ההבדל, יש צורך להשתמש במילת מפתח אחרת, כלומר לא ב, שפירושו בתרגום מילולי "לא ב" או (כפי שראוי לתרגם בענייננו הנדון) - "אינו כלול ב". אז בואו, כמו בדוגמה הקודמת, יש לנו שתי סכימות יחסים (R1 ור2), נתון בערך על ידי: R1 (מפתח,...) ו R2 (מַפְתֵחַ,...); כפי שאתה יכול לראות, תכונות מפתח שוב נקבעות בין התכונות של יחסים אלה. לפיכך, אנו מקבלים את הטופס הבא לייצוג פעולת ההבדל בשפת השאילתה המובנית: בחר* מ R1 איפה ключ לא ב (בחר ключ מ R2); לפיכך, רק אותם tuples של היחס R1, שהמפתח שלו אינו כלול ברשימת המפתחות של היחס R2. אם ניקח בחשבון את הסימון פשוטו כמשמעו, אז באמת מסתבר שמהיחס R1 "הפחית" את היחס R2. מכאן אנו מסיקים שתנאי הבחירה באופרטור זה כתוב נכון (הרי הגדרת ההפרש של שני יחסים מתבצעת) והשימוש במפתחות, כמו במקרה של יישום פעולת הצומת, מוצדק במלואו . שני השימושים ב"שיטת המפתח" שראינו הם הנפוצים ביותר. בכך מסתיים מחקר השימוש במפתחות בבניית אופרטורים המייצגים יחסים. כל הפעולות הבינאריות הנותרות של האלגברה ההתייחסותית נכתבות בדרכים אחרות. 4. תפעול מוצר קרטזיאני כפי שאנו זוכרים מההרצאות הקודמות, התוצר הקרטזיאני של שני יחסי-אופרנדים מורכב כקבוצה של כל הזוגות האפשריים של ערכים בעלי שם של tuples על תכונות. לכן, בשפת השאילתה המובנית, פעולת המוצר הקרטזיאני מיושמת באמצעות צירוף צולב, המסומן במילת המפתח לחצות להצטרף, שתרגום מילולי הוא "הצטרפות צולבת" או "הצטרפות צולבת". יש רק אופרטור Select אחד במבנה המייצג את פעולת המוצר הקרטזיאני בשפת השאילתה המובנית ויש לו את הצורה הבאה: בחר* מ R1 לחצות להצטרף R2 כאן ר1 ור2 - שמות של יחסי-אופרנדים ראשוניים. אוֹפְּצִיָה לחצות להצטרף מבטיח שהקשר המתקבל יכיל את כל התכונות (כולן, מכיוון שהשורה הראשונה של האופרטור מכילה את הסימן "*") המקבילות לכל זוגות הטפולות של היחסים R1 ור2. חשוב מאוד לזכור תכונה אחת של יישום פעולת המוצר הקרטזיאני. תכונה זו היא תוצאה של הגדרת הפעולה הבינארית של התוצר הקרטזיאני. תזכור את זה: r4(S4) = ר1(S1)xr2(S2) = {t(S1 ∪ ס2) | t[S1] ∈ ר1 &t(S2) ∈ ר2}, ס1 ∩ ס2= ∅; כפי שניתן לראות מההגדרה לעיל, זוגות של tuples נוצרים עם סכימות יחסים שאינן מצטלבות בהכרח. לכן, כאשר עובדים בשפת השאילתה המובנית של SQL, נקבע תמיד שליחסי האופרנד הראשוניים לא יהיו שמות מאפיינים תואמים. אבל אם לקשרים האלה עדיין יש את אותם שמות, ניתן לפתור את המצב הנוכחי בקלות באמצעות פעולת שינוי השם של התכונה, כלומר במקרים כאלה, אתה רק צריך להשתמש באפשרות as, שהוזכרה קודם לכן. הבה נבחן דוגמה שבה עלינו למצוא את המכפלה הקרטזיאנית של שני יחסים שיש להם כמה מאותם שמות תכונות. אז בהינתן היחסים הבאים: R1 (א, ב), R2 (לִפנֵי הַסְפִירָה); אנו רואים שתכונות R1.ב ור2.B בעלי אותם שמות. עם זאת בחשבון, הצהרת Select המיישמת את פעולת המוצר הקרטזיאנית בשפת השאילתה המובנית תיראה כך: בחר א, ר1.B as B1, R2.B as B2,C מ R1 לחצות להצטרף R2; לפיכך, באמצעות האפשרות שינוי שם כ, לא יהיו למכונה "שאלות" לגבי השמות התואמים של שני יחסי האופרנד המקוריים. 5. פעולות הצטרפות פנימיות במבט ראשון זה אולי נראה מוזר שאנחנו מחשיבים את פעולת ההצטרפות הפנימית לפני פעולת ההצטרפות הטבעית, כי כשעברנו פעולות בינאריות, הכל היה הפוך. אבל על ידי ניתוח הביטוי של פעולות בשפת השאילתה המובנית, ניתן להגיע למסקנה שפעולת הצטרפות הטבעית היא מקרה מיוחד של פעולת ההצטרפות הפנימית. לכן זה רציונלי לשקול את הפעולות האלה בסדר הזה. אז, ראשית, נזכיר את ההגדרה של פעולת ההצטרפות הפנימית שעברנו קודם לכן: r1(S1) איקס P r2(S2) = σ (ר1 xr2), ש1 ∩ S2 = ∅. עבורנו, בהגדרה זו, חשוב במיוחד שהסכמות הנחשבות של יחסי-אופרנדים ס1 ו-S2 אסור להצטלב. כדי ליישם את פעולת ההצטרפות הפנימית בשפת השאילתה המובנית, ישנה אפשרות מיוחדת הצטרפות פנימית, שמתורגם מילולית מאנגלית כ-"inner join" או "inner join". הצהרת Select במקרה של פעולת הצטרפות פנימית תיראה כך: בחר* מ R1 הצטרפות פנימית R2; כאן, כמו קודם, ר1 ור2 - שמות של יחסי-אופרנדים ראשוניים. בעת יישום פעולה זו, אסור לאפשר לסכימות של אופרנדים-יחס. 6. פעולת הצטרפות טבעית כפי שכבר אמרנו, פעולת ההצטרפות הטבעית היא מקרה מיוחד של פעולת ההצטרפות הפנימית. למה? כן, כי בזמן פעולת הצטרפות טבעית מצטרפים הטפולים של יחסי האופרנד המקוריים לפי תנאי מיוחד. כלומר, לפי התנאי של שוויון טפולים בצומת יחסי-אופרנדים, בעוד שבפעולת פעולת ההצטרפות הפנימית, לא ניתן היה לאפשר מצב כזה. מכיוון שפעולת ההצטרפות הטבעית שאנו שוקלים היא מקרה מיוחד של פעולת ההצטרפות הפנימית, אותה אפשרות משמשת ליישום אותה כמו עבור הפעולה הקודמת שנחשבת, כלומר, האפשרות הצטרפות פנימית. אך מכיוון שכאשר מרכיבים את האופרטור Select עבור פעולת הצטרפות הטבעית, יש צורך לקחת בחשבון גם את מצב השוויון של הטפולים של יחסי האופרנד המקוריים בצומת הסכמות שלהם, אז בנוסף לאפשרות המצוינת, מילת המפתח מוחל on. בתרגום מאנגלית פירושו המילולי "על", וביחס למשמעות שלנו, ניתן לתרגם אותו כ"כפוף ל". הצורה הכללית של הצהרת Select לביצוע פעולת צירוף טבעי היא כדלקמן: בחר* מ שם קשר 1 הצטרפות פנימית שם קשר 2 on תנאי שוויון טופל; שקול דוגמה. תנו שני יחסים: R1 (א ב ג), R2 (ב, ג, ד); ניתן ליישם את פעולת ההצטרפות הטבעית של יחסים אלה באמצעות האופרטור הבא: בחר א, ר1.ב, ר1.CD מ R1 הצטרפות פנימית R2 on R1.B=R2.ב ור1.C=R2.C כתוצאה מפעולה זו, התכונות המצוינות בשורה הראשונה של האופרטור Select, המתאימות ל-tuples שווים בצומת שצוין, יוצגו בתוצאה. יש לציין שכאן אנו מתייחסים לתכונות הנפוצות B ו-C, לא רק בשם. זה חייב להיעשות לא מאותה סיבה כמו במקרה של יישום פעולת המוצר הקרטזיאני, אלא כי אחרת לא יהיה ברור לאיזה יחס הם מתייחסים. מעניין לציין שהנוסח המשומש של תנאי ההצטרפות (R1.B=R2.ב ור1.C=R2.C) מניח שהתכונות המשותפות של קשרי ה-Null-value שהצטרפו אינן מותרות. זה מובנה במערכת Structured Query Language מההתחלה. 7. פעולת החיבור החיצוני השמאלי ביטוי שפת השאילתה המובנית ב-SQL של פעולת הצירוף השמאלי החיצוני מתקבל מהטמעת פעולת ההצטרפות הטבעית על ידי החלפת מילת המפתח פְּנִימִי לכל מילת מפתח שמאל חיצוני. לפיכך, בשפה של שאילתות מובנות, פעולה זו תיכתב באופן הבא: בחר* מ שם קשר 1 שמאל החיצוני להצטרף שם קשר 2 on תנאי שוויון טופל; 8. פעולת החיבור החיצוני הימני הביטוי עבור פעולת צירוף חיצוני ימני בשפת שאילתה מובנית מתקבל מביצוע פעולת צירוף טבעית על ידי החלפת מילת המפתח פְּנִימִי לכל מילת מפתח ימין חיצוני. אז, אנו מבינים שבשפת השאילתה המובנית של SQL, הפעולה של החיבור החיצוני הימני תיכתב באופן הבא: בחר* מ שם קשר 1 צירוף חיצוני ימני שם קשר 2 on תנאי שוויון טופל; 9. פעולת הצטרפות חיצונית מלאה הביטוי Structured Query Language עבור פעולת צירוף חיצוני מלא מתקבל, כמו בשני המקרים הקודמים, מהביטוי עבור פעולת הצטרפות טבעית על ידי החלפת מילת המפתח פְּנִימִי לכל מילת מפתח חיצוני מלא. לפיכך, בשפה של שאילתות מובנות, פעולה זו תיכתב באופן הבא: בחר* מ שם קשר 1 חיבור חיצוני מלא שם קשר 2 on תנאי שוויון טופל; זה מאוד נוח שהאפשרויות הללו מובנות בסמנטיקה של שפת השאילתות המובנית ב-SQL, כי אחרת כל מתכנת יצטרך להוציא אותן באופן עצמאי ולהזין אותן בכל מסד נתונים חדש. 4. שימוש בשאילתות משנה כפי שניתן היה להבין מהחומר הנסקר, המושג "תת-שאילתה" בשפת השאילתה המובנית הוא מושג בסיסי וישים אותו באופן די נרחב (לעיתים, אגב, הם נקראים גם שאילתות SQL. אכן, התרגול של תכנות ו עבודה עם מסדי נתונים מראה שהרכבת מערכת של שאילתות משנה לפתרון משימות קשורות שונות - פעילות שמתגמלת הרבה יותר בהשוואה לכמה שיטות אחרות לעבודה עם מידע מובנה. לכן, הבה נשקול דוגמה כדי להבין טוב יותר את הפעולות עם שאילתות המשנה, הקומפילציה שלהן. ולהשתמש. שיהיה הפרגמנט הבא של מסד נתונים מסוים, שניתן להשתמש בו בכל מוסד חינוכי: פריטים (קוד פריט, שם הפריט); תלמידים (מספר ספר רישום, שם מלא); מושב (קוד נושא, מספר ספר ציונים, כיתה); בואו ננסח שאילתת SQL שמחזירה משפט המציין את מספר ספר הציונים של התלמיד, שם משפחה וראשי תיבות וציון לנושא בשם "מאגרי מידע". אוניברסיטאות צריכות לקבל מידע כזה תמיד ובזמן, כך שהשאילתה הבאה היא אולי יחידת התכנות הפופולרית ביותר המשתמשת בבסיסי נתונים כאלה. מטעמי נוחות, נניח בנוסף שהתכונות "שם משפחה", "שם פרטי" ו"פטרונימי" אינן מאפשרות ערכי Null ואינן ריקות. דרישה זו מובנת והגיונית למדי, מכיוון שהראשון מבין הנתונים של תלמיד חדש מוכנס למאגר המידע של כל מוסד חינוכי הוא הנתונים על שם משפחתו, שמו הפרטי ומשפחתו. ומובן מאליו שלא יכול להיות במאגר כזה ערך שמכיל נתונים על תלמיד, אך יחד עם זאת שמו אינו ידוע. שימו לב שהתכונה "שם פריט" של סכימת היחסים "פריטים" היא מפתח, כך שכולה מההגדרה (עוד על כך בהמשך), כל שמות הפריטים הם ייחודיים. זה מובן גם בלי להסביר את ייצוג המפתח, כי כל המקצועות הנלמדים במוסד חינוכי חייבים להיות בעלי שמות שונים. כעת, לפני שנתחיל להרכיב את הטקסט של האופרטור עצמו, נציג שתי פונקציות שיהיו שימושיות לנו בהמשך הדרך. ראשית, נצטרך את הפונקציה מְטוּפָּח, נכתב Trim ("מחרוזת"), כלומר, הארגומנט לפונקציה זו הוא מחרוזת. מה עושה הפונקציה הזו? הם מחזירים את הארגומנט עצמו ללא רווחים בתחילת ובסוף שורה זו, כלומר, פונקציה זו משמשת, למשל, במקרים: Trim ("Bogucharnikov") או Trim ("Maksimenko"), כאשר לאחר או לפני ארגומנטים הם שווה כמה מקומות נוספים. ושנית, יש צורך להתייחס גם לפונקציה Left, שנכתבת Left (מחרוזת, מספר), כלומר, פונקציה של כבר שני ארגומנטים, שאחד מהם הוא, כמו קודם, מחרוזת. הארגומנט השני שלו הוא מספר, הוא מציין כמה תווים מהצד השמאלי של המחרוזת צריך להיות פלט בתוצאה. לדוגמה, תוצאת הפעולה: שמאל ("מיכאיל, 1") + "." + שמאל ("זינוביץ', 1") יהיו ראשי התיבות "M. Z." כדי להציג את ראשי התיבות של התלמידים נשתמש בפונקציה הזו בשאילתה שלנו. אז בואו נתחיל להרכיב את השאילתה הרצויה. ראשית, בואו נעשה שאילתת עזר קטנה, שבה אנו משתמשים בשאילתה הראשית הראשית: בחר מספר ספר ציונים, ציון מ מושב איפה קוד פריט = (בחר קוד פריט מ אובייקטים איפה שם פריט = "מאגרי מידע") as "אומדנים" מאגרי מידע "; שימוש באפשרות as כאן פירושו שכינוי שאילתה זו "הערכות מסד נתונים". עשינו זאת לנוחות של עבודה נוספת עם בקשה זו. לאחר מכן, בשאילתה זו, שאילתת משנה: בחר קוד פריט מ אובייקטים איפה שם פריט = "מאגרי מידע"; מאפשר לך לבחור מתוך היחס "Session" את אותם tuples המתייחסים לנושא הנדון, כלומר למאגרי מידע. מעניין, שאילתת משנה פנימית זו יכולה להחזיר רק ערך אחד, שכן התכונה "שם פריט" היא המפתח של הקשר "פריטים", כלומר כל הערכים שלה הם ייחודיים. והשאילתה כולה "ציונים "מסד נתונים" מאפשרת לך לבחור מתוך קשרי "מפגש" נתונים על אותם תלמידים (מספרי ספר הציונים והציונים שלהם) העומדים בתנאי המצוין בשאילתת המשנה, כלומר מידע על הנושא הנקרא "מסד נתונים" . כעת נגיש את הבקשה העיקרית, תוך שימוש בתוצאות שכבר התקבלו. בחר סטודנטים. מספר ספר רישום, מְטוּפָּח (שם משפחה) + " " + שמאל (שם, 1) + "." + שמאל (פטרונימי, 1) + "."as שם מלא, אומדנים "מאגרי מידע". כיתה מ סטודנטים הצטרפות פנימית ( בחר מספר ספר ציונים, ציון מ מושב איפה קוד פריט = (בחר קוד פריט מ אובייקטים איפה שם פריט = "מאגרי מידע") ) כפי ש מאגרי מידע "אומדנים". on סטודנטים. ספר ציונים # = ציוני "מסד נתונים". מספר ספר שיא. לכן, תחילה נפרט את התכונות שיצטרכו להיות מוצגות לאחר השלמת השאילתה. יש להזכיר שהתכונה "מספר ספר ציונים" היא מיחס הסטודנטים, משם - התכונות "שם משפחה", "שם פרטי" ו"פטרונימי". נכון, שתי התכונות האחרונות אינן נגזרות במלואן, אלא רק האותיות הראשונות. אנו מזכירים גם את התכונה 'ציון' מהשאילתה 'ציון מסד נתונים' שהזנו קודם לכן. אנו בוחרים את כל התכונות הללו מהחיבור הפנימי של היחס "סטודנטים" והשאילתה "ציוני מסד נתונים". הצטרפות פנימית זו, כפי שאנו יכולים לראות, נלקחת על ידינו בתנאי של שוויון מספרי ספר השיאים. כתוצאה מפעולת הצטרפות פנימית זו, ציונים מתווספים ליחס התלמידים. יש לציין שמכיוון שהתכונות "שם משפחה", "שם פרטי" ו"פטרונימי" לפי תנאי אינן מאפשרות ערכי Null ואינן ריקות, נוסחת החישוב שמחזירה את התכונה "שם" (מְטוּפָּח (שם משפחה) + " " + שמאל (שם, 1) + "." + שמאל (פטרונימי, 1) + "."as השם המלא, בהתאמה, אינו דורש בדיקות נוספות, מפושט. הרצאה מספר 7. יחסים בסיסיים כפי שאנו כבר יודעים, מסדי נתונים הם כמו סוג של קונטיינר, שמטרתו העיקרית היא לאחסן נתונים המוצגים בצורה של קשרים. אתה צריך לדעת שבהתאם לאופי ולמבנה שלהם, מערכות היחסים מחולקות ל: 1) יחסים בסיסיים; 2) מערכות יחסים וירטואליות. קשרי תצוגת בסיס מכילים נתונים עצמאיים בלבד ואינם ניתנים לביטוי במונחים של קשרי מסד נתונים אחרים. במערכות ניהול מסדי נתונים מסחריות, מערכות יחסים בסיסיות מכונות בדרך כלל בפשטות טבלאות בניגוד לייצוגים המקבילים למושג יחסים וירטואליים. בקורס זה נשקול בפירוט מסוים רק את מערכות היחסים הבסיסיות, הטכניקות העיקריות ועקרונות העבודה איתם. 1. סוגי נתונים בסיסיים סוגי נתונים, כמו קשרים, מחולקים ל בסיסי и וירטואלי. (על סוגי נתונים וירטואליים נדבר מעט מאוחר יותר; נקדיש פרק נפרד לנושא זה.) סוגי נתונים בסיסיים - אלו הם כל סוגי הנתונים המוגדרים בתחילה במערכות ניהול מסד נתונים, כלומר, נמצאים שם כברירת מחדל (בניגוד לסוג נתונים מוגדר על ידי משתמש, אותו ננתח מיד לאחר מעבר דרך סוג הנתונים הבסיסי). לפני שנמשיך לבחון את סוגי הנתונים הבסיסיים בפועל, אנו מפרטים אילו סוגי נתונים קיימים באופן כללי: 1) נתונים מספריים; 2) נתונים לוגיים; 3) נתוני מחרוזת; 4) נתונים המגדירים את התאריך והשעה; 5) נתוני זיהוי. כברירת מחדל, מערכות ניהול מסדי נתונים הציגו כמה מסוגי הנתונים הנפוצים ביותר, שכל אחד מהם שייך לאחד מסוגי הנתונים המפורטים. בואו נתקשר אליהם. 1. בתוך מִספָּרִי סוג הנתונים מובחן: 1) מספר שלם. מילת מפתח זו מציינת בדרך כלל סוג נתונים של מספר שלם; 2) אמיתי, המתאים לסוג הנתונים האמיתי; 3) עשרוני (n, m). זהו סוג נתונים עשרוני. יתרה מכך, בסימון n נמצא מספר המקבע את מספר הספרות הכולל של המספר, ו-m מראה כמה תווים מהם נמצאים אחרי הנקודה העשרונית; 4) כסף או מטבע, שהוצגו במיוחד עבור ייצוג נתונים נוח של סוג הנתונים הכספיים. 2. בתוך הגיוני סוג נתונים בדרך כלל להקצות רק סוג אחד בסיסי, זה לוגי. 3. חוּט לסוג הנתונים יש ארבעה סוגים בסיסיים (כלומר, כמובן, הנפוצים ביותר): 1) Bit(n). אלה מחרוזות סיביות באורך קבוע n; 2) Varbit(n). אלו גם מחרוזות של ביטים, אך עם אורך משתנה שאינו עולה על n ביטים; 3) Char(n). אלו הן מחרוזות תווים באורך קבוע n; 4) Varchar(n). אלו הן מחרוזות תווים, עם אורך משתנה שאינו עולה על n תווים. 4. הקלד תאריך ושעה כולל את סוגי הנתונים הבסיסיים הבאים: 1) תאריך - סוג נתוני תאריך; 2) זמן - סוג נתונים המבטא את השעה ביום; 3) תאריך-שעה הוא סוג נתונים המבטא גם תאריך וגם שעה. 5. הזדהות סוג הנתונים מכיל רק סוג אחד הנכלל כברירת מחדל במערכת ניהול מסד הנתונים, והוא GUID (מזהה ייחודי גלובלי). יש לציין שלכל סוגי הנתונים הבסיסיים יכולים להיות גרסאות של טווחי ייצוג נתונים שונים. כדי לתת דוגמה, גרסאות של סוג הנתונים במספרים שלמים של ארבעה בתים יכולים להיות סוגי נתונים של שמונה בתים (ביגינט) ושני בתים (סמולינט). בואו נדבר בנפרד על סוג הנתונים הבסיסי של GUID. סוג זה נועד לאחסן ערכי שישה עשר בתים של המזהה המכונה ייחודי גלובלי. כל הערכים השונים של מזהה זה נוצרים באופן אוטומטי כאשר נקראת פונקציה מובנית מיוחדת NewId(). ייעוד זה מגיע מהביטוי האנגלי המלא New Identification, שפירושו המילולי הוא "ערך מזהה חדש". כל ערך מזהה שנוצר במחשב מסוים הוא ייחודי בכל המחשבים המיוצרים. מזהה GUID משמש, במיוחד, לארגון שכפול מסד נתונים, כלומר, בעת יצירת עותקים של כמה מסדי נתונים קיימים. GUIDs כאלה יכולים לשמש מפתחי מסדי נתונים יחד עם סוגים בסיסיים אחרים. מיקום ביניים בין סוג GUID לסוגי בסיס אחרים תופס על ידי סוג בסיס מיוחד אחר - הטיפוס דֶלְפֵּק. מילת מפתח מיוחדת משמשת לייעוד נתונים מסוג זה. מונה(x0, ∆x), שפשוטו כמשמעו מתרגם מאנגלית ופירושו "נגד". פרמטר x0 קובע את הערך ההתחלתי, ו ∆x - שלב הגדלה. ערכים מסוג מונה זה הם בהכרח מספרים שלמים. יש לציין שעבודה עם סוג נתונים בסיסי זה כוללת מספר תכונות מעניינות מאוד. לדוגמה, ערכים מסוג Counter זה אינם מוגדרים, כפי שאנו רגילים לעבוד עם כל סוגי הנתונים האחרים, הם נוצרים לפי דרישה, בדומה לערכים מסוג המזהה הייחודי העולמי. זה גם יוצא דופן שניתן לציין את סוג המונה רק בעת הגדרת הטבלה, ורק אז! לא ניתן להשתמש בסוג זה בקוד. אתה גם צריך לזכור שכאשר מגדירים טבלה, ניתן לציין את סוג המונה רק עבור עמודה אחת. ערכי נתוני מונים נוצרים אוטומטית כאשר שורות מוכנסות. יתרה מכך, דור זה מתבצע ללא חזרה, כך שהמונה תמיד יזהה כל שורה באופן ייחודי. אבל זה יוצר אי נוחות מסוימת כאשר עובדים עם טבלאות המכילות נתוני מונה. אם, למשל, הנתונים ביחס שניתן על ידי הטבלה משתנים ויש למחוק אותם או להחליף אותם, ערכי המונה יכולים בקלות "לבלבל את הקלפים", במיוחד אם מתכנת לא מנוסה עובד. הבה ניתן דוגמה הממחישה מצב כזה. תן את הטבלה הבאה המייצגת קשר כלשהו, שבה מוכנסות ארבע שורות:
המונה נתן אוטומטית לכל שורה חדשה שם ייחודי. ועכשיו נסיר את השורה השנייה והרביעית מהטבלה, ולאחר מכן נוסיף שורה אחת נוספת. פעולות אלו יגרמו לשינוי הבא של טבלת המקור:
לפיכך, המונה הסיר את השורות השנייה והרביעית יחד עם שמם הייחודי, ולא "הקצה" אותן מחדש לשורות חדשות, כפי שניתן היה לצפות. יתרה מכך, מערכת ניהול מסד הנתונים לעולם לא תאפשר לכם לשנות את ערך המונה באופן ידני, כפי שהיא לא תאפשר לכם להכריז על מספר מונים בטבלה אחת בו זמנית. בדרך כלל, המונה משמש כסרוגייט, כלומר מפתח מלאכותי בטבלה. מעניין לדעת שהערכים הייחודיים של מונה של ארבעה בתים בקצב ייצור של ערך אחד לשניה יחזיקו מעמד יותר מ-100 שנים. בואו נראה איך זה מחושב: שנה אחת = 1 ימים * 365 שעות * 24 שניות * 60 שניות < 60 ימים * 366 שעות * 24 שניות * 60 שניות < 6025 s. שנייה אחת > 1-25 שנה. 24*8 ערכים / ערך 1/שנייה = 232 ג > 27 שנה > 100 שנים. 2. סוג נתונים מותאם אישית סוג נתונים מותאם אישית שונה מכל סוגי הבסיס בכך שהוא לא היה מובנה במקור במערכת ניהול מסד הנתונים, הוא לא הוכרז כסוג נתונים ברירת מחדל. סוג זה יכול להיווצר על ידי כל משתמש ומתכנת מסדי נתונים בהתאם לבקשות ולדרישות שלו. לפיכך, סוג נתונים המוגדר על ידי משתמש הוא תת-סוג של סוג בסיס כלשהו, כלומר, זהו סוג בסיס עם הגבלות מסוימות על קבוצת הערכים המותרים. בסימון פסאודו-קוד, סוג נתונים מותאם אישית נוצר באמצעות ההצהרה הסטנדרטית הבאה: צור תת סוג שם משנה סוּג שם סוג הבסיס As אילוץ משנה; לכן, בשורה הראשונה, עלינו לציין את השם של סוג הנתונים החדש המוגדר על ידי המשתמש, בשורה השנייה - איזה מבין סוגי הנתונים הבסיסיים הקיימים לקחנו כמודל, ויצרנו את שלנו, ולבסוף, בשלישי. - ההגבלות שאנו צריכים להוסיף להגבלות הקיימות על סט הערכים של סוג הנתונים הבסיסי - מדגם. אילוצי תת-סוג נכתבים כתנאי התלוי בשם של תת-הסוג המוגדר. כדי להבין טוב יותר כיצד פועלת הצהרת Create, שקול את הדוגמה הבאה. נניח שאנחנו צריכים ליצור סוג נתונים מיוחד משלנו, למשל, כדי לעבוד בדואר. זה יהיה הסוג שיעבוד עם נתונים כמו מספרי מיקוד. המספרים שלנו יהיו שונים ממספרים עשרוניים רגילים בני שש ספרות בכך שהם יכולים להיות חיוביים בלבד. בוא נכתוב אופרטור כדי ליצור את תת-הסוג שאנחנו צריכים: צור תת סוג מיקוד סוּג decimal(6, 0) As מיקוד > 0. מדוע בחרנו עשרוני (6, 0)? נזכור את הצורה הרגילה של האינדקס, אנו רואים שמספרים כאלה חייבים להיות מורכבים משישה מספרים שלמים מאפס עד תשע. לכן לקחנו את הסוג העשרוני כסוג הנתונים הבסיסי. מעניין לציין שבאופן כללי, התנאי המוטל על סוג הנתונים הבסיסי, כלומר אילוץ המשנה, עשוי להכיל את החיבורים הלוגיים לא, או, ובאופן כללי להיות ביטוי לכל מורכבות שרירותית. ניתן להשתמש בתתי-סוגי נתונים מותאמים אישית המוגדרים בדרך זו בחופשיות יחד עם סוגי נתונים בסיסיים אחרים הן בקוד התוכנית והן בעת הגדרת סוגי נתונים בעמודות טבלה, כלומר סוגי נתונים בסיסיים וסוגי נתוני משתמש שווים לחלוטין בעבודה איתם. בסביבת הפיתוח החזותי, הם מופיעים ברשימות של טיפוסים חוקיים יחד עם סוגי נתוני בסיס אחרים. הסבירות שאולי נזדקק לסוג נתונים לא מתועד (מוגדר על ידי משתמש) בעת תכנון מסד נתונים חדש משלנו היא די גבוהה. אכן, כברירת מחדל, רק סוגי הנתונים הנפוצים ביותר נתפרים במערכת ניהול מסד הנתונים, המתאימים, בהתאמה, לפתרון המשימות הנפוצות ביותר. בעת הידור מסדי נתונים בנושא, זה כמעט בלתי אפשרי לעשות בלי לעצב סוגי נתונים משלך. אבל, באופן מוזר, בהסתברות שווה, ייתכן שנצטרך להסיר את תת-הסוג שיצרנו, כדי לא לבלבל ולסבך את הקוד. לשם כך, למערכות ניהול מסדי נתונים יש בדרך כלל אופרטור מיוחד מובנה. ירידה, שפירושו "הסר". הצורה הכללית של אופרטור זה להסרת סוגים מותאמים אישית מיותרים היא כדלקמן: שחרר תת-סוג שם הסוג המותאם אישית; סוגי נתונים מותאמים אישית מומלצים בדרך כלל עבור תת-סוגים כלליים מספיק. 3. ערכי ברירת מחדל למערכות ניהול מסדי נתונים עשויה להיות היכולת ליצור ערכי ברירת מחדל שרירותיים או, כפי שהם נקראים גם, ברירת מחדל. לפעולה זו בכל סביבת תכנות יש משקל די גדול, מכיוון שכמעט בכל משימה ייתכן שיהיה צורך להציג קבועים, ערכי ברירת מחדל בלתי ניתנים לשינוי. כדי ליצור ברירת מחדל במערכות ניהול מסדי נתונים, נעשה שימוש בפונקציה המוכרת לנו כבר ממעבר של סוג נתונים מוגדר על ידי המשתמש צור. רק במקרה של יצירת ערך ברירת מחדל, נעשה שימוש גם במילת מפתח נוספת ברירת מחדל, שפירושו "ברירת מחדל". במילים אחרות, כדי ליצור ערך ברירת מחדל במסד נתונים קיים, עליך להשתמש במשפט הבא: צור ברירת מחדל שם ברירת מחדל As ביטוי קבוע; ברור שבמקום ערך קבוע בעת החלת אופרטור זה, עליך לכתוב את הערך או הביטוי שאנו רוצים שיהפכו לערך או ביטוי ברירת המחדל. וכמובן, עלינו להחליט באיזה שם יהיה לנו נוח להשתמש בו במסד הנתונים שלנו, ולכתוב את השם הזה בשורה הראשונה של האופרטור. שים לב שבמקרה הספציפי הזה, משפט Create זה עוקב אחר תחביר Transact-SQL המובנה במערכת Microsoft SQL Server. אז מה יש לנו? הסקנו שברירת המחדל היא קבוע בשם המאוחסן בבסיסי נתונים, בדיוק כמו האובייקט שלו. בסביבת הפיתוח החזותי, ברירות המחדל מופיעות ברשימת ברירות המחדל המודגשות. הנה דוגמה ליצירת ברירת מחדל. נניח שכדי לפעולה נכונה של מסד הנתונים שלנו יש צורך שערך יפעל בו עם משמעות של חיים בלתי מוגבלים של משהו. אז אתה צריך להזין ברשימת הערכים של מסד נתונים זה את ערך ברירת המחדל העונה על הדרישה הזו. זה עשוי להיות נחוץ, ולו רק בגלל שבכל פעם שאתה נתקל בביטוי המסורבל הזה בטקסט הקוד, זה יהיה מאוד לא נוח לכתוב אותו שוב. לכן נשתמש בהצהרה Create למעלה כדי ליצור ברירת מחדל, עם המשמעות של חיים בלתי מוגבלים של משהו. צור ברירת מחדל "ללא הגבלת זמן" As ‘9999-12-31 23: 59:59’ גם כאן נעשה שימוש בתחביר Transact-SQL, לפיו ערכי קבועי תאריך-זמן (במקרה זה, '9999-12-31 23:59:59') נכתבים כמחרוזות תווים של כיוון מסוים. הפרשנות של מחרוזות תווים כערכי תאריך ושעה נקבעת על פי ההקשר שבו נעשה שימוש במחרוזות. לדוגמה, במקרה הספציפי שלנו, תחילה נכתב ערך הגבול של השנה בשורה הקבועה, ולאחר מכן השעה. עם זאת, עם כל התועלת שלהן, ברירות מחדל, כמו סוג נתונים המוגדר על ידי משתמש, עשויות לפעמים גם לדרוש את הסרתן. למערכות ניהול מסדי נתונים יש בדרך כלל פרדיקט מובנה מיוחד, בדומה לאופרטור שמסיר סוג נתונים מוגדר יותר על ידי המשתמש שאין בו עוד צורך. זהו פרדיקט ירידה והמפעיל עצמו נראה כך: שחרר את ברירת המחדל שם ברירת מחדל; 4. תכונות וירטואליות כל התכונות במערכות ניהול מסדי נתונים מחולקות (באנלוגיה מוחלטת עם מערכות יחסים) לבסיסי ווירטואליים. כך נקרא תכונות בסיס הן תכונות מאוחסנות שיש להשתמש בהן יותר מפעם אחת, ולכן, רצוי לשמור. ובתמורה, תכונות וירטואליות אינן מאוחסנות, אלא תכונות מחושבות. מה זה אומר? משמעות הדבר היא שהערכים של מה שנקרא תכונות וירטואליות אינם מאוחסנים בפועל, אלא מחושבים באמצעות תכונות הבסיס תוך כדי תנועה באמצעות נוסחאות נתונות. במקרה זה, התחומים של תכונות וירטואליות מחושבות נקבעים באופן אוטומטי. בוא ניתן דוגמה לטבלה המגדירה יחס, שבה שתי תכונות הן רגילות, בסיסיות, והתכונה השלישית היא וירטואלית. זה יחושב לפי נוסחה שהוזנה במיוחד.
אז, אנו רואים שהתכונות "משקל ק"ג" ו"מחיר לשפשף לק"ג הן תכונות בסיסיות, מכיוון שיש להן ערכים רגילים והן מאוחסנות במסד הנתונים שלנו. אבל התכונה "עלות" היא תכונה וירטואלית, מכיוון שהיא נקבעת על ידי נוסחת החישוב שלה ולא תישמר בפועל במסד הנתונים. מעניין לציין שבשל טבען, תכונות וירטואליות אינן יכולות לקבל ערכי ברירת מחדל, ובאופן כללי, עצם הרעיון של ערך ברירת מחדל עבור תכונה וירטואלית הוא חסר משמעות, ולכן אינו ישים. ואתה גם צריך להיות מודע לכך שלמרות שהתחומים של תכונות וירטואליות נקבעים באופן אוטומטי, לפעמים צריך לשנות את סוג הערכים המחושבים מהקיים לאחד אחר. לשם כך, לשפת מערכות ניהול מסדי הנתונים יש פרדיקט מיוחד Convert, בעזרתו ניתן להגדיר מחדש את סוג הביטוי המחושב. Convert היא מה שנקרא פונקציית המרה מסוג מפורש. זה כתוב כך: המרת (סוג נתונים, ביטוי); הביטוי שהוא הארגומנט השני של הפונקציה Convert יחושב וייצא כנתונים כאלה, שסוגם מצוין על ידי הארגומנט הראשון של הפונקציה. שקול דוגמה. נניח שאנחנו צריכים לחשב את הערך של הביטוי "2 * 2", אבל אנחנו צריכים להוציא את זה לא כמספר שלם "4", אלא כמחרוזת של תווים. כדי לבצע משימה זו, אנו כותבים את פונקציית ההמרה הבאה: המרת (Char(1), 2*2). לפיכך, אנו יכולים לראות שהסימון הזה של הפונקציה Convert ייתן בדיוק את התוצאה שאנו צריכים. 5. מושג המפתחות כאשר מכריזים על הסכימה של יחס בסיס, ניתן לתת הצהרות של מספר מפתחות. נתקלנו בזה הרבה פעמים בעבר. לבסוף, הגיע הזמן לדבר ביתר פירוט על מה הם מפתחות יחסים, ולא להיות מוגבל לביטויים כלליים והגדרות משוערות. אז בואו ניתן הגדרה קפדנית של מפתח יחס. מפתח סכימת יחסים היא תת-סכימה של הסכימה המקורית, המורכבת מתכונה אחת או יותר שעבורה היא מוצהרת מצב ייחודיות ערכים בזוגיות זוגית. על מנת להבין מהו תנאי הייחודיות, או כפי שהוא נקרא גם, אילוץ ייחודי, נתחיל בהגדרה של tuple והפעולה האנורית של הקרנת tuple על תת-מעגל. בואו נביא אותם: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - הגדרה של tuple, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S היא ההגדרה של פעולת ההשלכה האנורית; ברור שההשלכה של ה-tuple על תת הסכימה מתאימה למחרוזת משנה של שורת הטבלה. אז, מהו בעצם אילוץ ייחודיות של תכונה מרכזית? ההכרזה על המפתח K עבור ערכת היחס S מובילה לניסוח התנאי הבלתי משתנה הבא, הנקרא, כפי שכבר אמרנו, אילוץ ייחודיות ומסומן כ: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1t,2 ∈ r(t 1[K]=ת2 [K] → t 1(S) = t2(S)), K ⊆ S; אז, אילוץ הייחודיות הזה Inv < K → S > r(S) של המפתח K פירושו שאם יש שני tuples t1 ו t2, השייכים ליחס r(S), שווים בהשלכה על המפתח K, אז זה כרוך בהכרח בשוויון של שני הטפולים הללו ובהשלכה על כל הסכימה של היחס S. במילים אחרות, כל הערכים מבין הטפולים השייכים לתכונות המפתח הם ייחודיים, ייחודיים ביחס ביניהם. והדרישה החשובה השנייה למפתח יחס היא דרישת יתירות. מה זה אומר? דרישה זו פירושה שאין צורך בקבוצת משנה קפדנית של המפתח להיות ייחודי. ברמה האינטואיטיבית, ברור שתכונת המפתח היא תכונת היחס שמזהה באופן ייחודי ומדויק כל טופלה של היחס. לדוגמה, ביחס הבא שניתן על ידי טבלה:
תכונת המפתח היא התכונה "ספר ציונים #", מכיוון שלתלמידים שונים לא יכול להיות אותו מספר ספר ציונים, כלומר, תכונה זו כפופה לאילוץ ייחודי. מעניין שבסכימה של כל קשר, יכולים להופיע מגוון מפתחות. אנו מציגים את סוגי המפתחות העיקריים: 1) מפתח פשוט הוא מפתח המורכב מתכונה אחת ולא יותר. לדוגמה, בגיליון בחינה למקצוע מסוים, מפתח פשוט הוא מספר כרטיס האשראי, מכיוון שהוא יכול לזהות באופן ייחודי כל תלמיד; 2) מפתח מורכב הוא מפתח המורכב משתי תכונות או יותר. לדוגמה, מפתח מורכב ברשימת הכיתות הוא מספר הבניין ומספר הכיתה. הרי לא ניתן לזהות באופן ייחודי כל קהל עם אחת מהתכונות הללו, ודי קל לעשות זאת במכלול שלהם, כלומר עם מפתח מורכב; 3) מפתח סופר הוא כל קבוצה של כל מפתח. לכן, הסכימה של היחס עצמו היא בהחלט מפתח-על. מכאן נוכל להסיק שלכל קשר יש תיאורטית לפחות מפתח אחד, ויכול להיות שיש כמה מהם. עם זאת, הכרזה על מפתח-על במקום מפתח רגיל אינה חוקית מבחינה לוגית, מכיוון שהיא כרוכה בהרגעת מגבלת הייחודיות הנאכפת באופן אוטומטי. הרי למפתח העל, למרות שיש לו תכונה של ייחוד, אין לו תכונה של אי-יתירות; 4) מפתח ראשי הוא פשוט המפתח שהוכרז ראשון כאשר הוגדר יחס הבסיס. חשוב שיוכרז מפתח ראשוני אחד ויחיד. בנוסף, תכונות מפתח ראשיות לעולם לא יכולות לקבל ערכי null. בעת יצירת יחס בסיס בערך פסאודוקוד, המפתח הראשי מסומן המפתח הראשי ובסוגריים מופיע שם התכונה, שהיא המפתח הזה; 5) מפתחות מועמדים הם כל שאר המפתחות שהוכרזו אחרי המפתח הראשי. מהם ההבדלים העיקריים בין מפתחות מועמדים למפתחות ראשיים? ראשית, יכולים להיות מספר מפתחות מועמדים, בעוד המפתח הראשי, כפי שהוזכר לעיל, יכול להיות רק אחד. ושנית, אם התכונות של המפתח הראשי אינן יכולות לקבל ערכי Null, אז תנאי זה אינו מוטל על התכונות של המפתחות המועמדים. בפסאודוקוד, בעת הגדרת יחס בסיס, מפתחות מועמדים מוכרזים באמצעות המילים מפתח המועמד ובסוגריים לאחר מכן, כמו במקרה של הכרזה על מפתח ראשי, מצוין שם התכונה, שהוא מפתח המועמד הנתון; 6) מפתח חיצוני הוא מפתח המוצהר ביחס בסיס המתייחס גם למפתח ראשוני או מועמד של אותו יחס בסיס אחר. במקרה זה, הקשר אליו מתייחס המפתח הזר נקרא הפניה (או הוֹרֶה) יַחַס. יחס המכיל מפתח זר נקרא יֶלֶד. בפסאודוקוד, המפתח הזר מסומן כ - מפתח זר, בסוגריים מיד אחרי מילים אלו, מצוין שם התכונה של יחס זה, שהוא מפתח זר, ולאחר מכן נכתבת מילת המפתח אזכור ("מתייחס") וציין את שם יחס הבסיס ואת שם התכונה שאליה מתייחס מפתח זר מסוים זה. כמו כן, בעת יצירת יחס בסיס, עבור כל מפתח זר, נכתב תנאי, שנקרא אילוץ יושרה התייחסותי, אבל נדבר על זה בפירוט מאוחר יותר. הרצאה מס' 8 הנושא של הרצאה זו יהיה דיון מפורט למדי באופרטור יצירת יחסי הבסיס. ננתח את המפעיל עצמו ברשומה פסאודו-קוד, ננתח את כל מרכיביו ועבודתם, וננתח את שיטות השינוי, כלומר, שינוי היחסים הבסיסיים. 1. סמלים מתכת לשוניים כאשר מתארים את המבנים התחביריים המשמשים בכתיבת אופרטור יצירת יחס הבסיס בפסאודוקוד, נעשה שימוש בשיטות שונות. סמלים מתכת לשוניים. אלו כל מיני סוגים של סוגריים פתיחה וסגירה, שילובים שונים של נקודות ופסיקים, במילה אחת, סמלים שכל אחד מהם נושא משמעות משלו ומקל על המתכנת לכתוב קוד. הבה נציג ונסביר את המשמעות של הסמלים המתכת-לשוניים העיקריים המשמשים לרוב בעיצוב יחסים בסיסיים. כך: 1) תו מתכת-לשוני "{}". מבנים תחביריים בסוגרים מתולתלים הם חובה יחידות תחביריות. בעת הגדרת יחס בסיס, האלמנטים הנדרשים הם, למשל, תכונות בסיס; בלי להצהיר על תכונות בסיס, לא ניתן לעצב קשר. לכן, בעת כתיבת אופרטור יצירת קשר הבסיס בפסאודוקוד, תכונות הבסיס רשומות בסוגריים מסולסלים; 2) הסמל המתכת-לשוני "[]". במקרה זה, ההפך הוא הנכון: מבני התחביר בסוגריים מרובעים מייצגים אופציונאלי אלמנטים תחביריים. היחידות התחביריות האופציונליות באופרטור יצירת קשרי הבסיס, בתורן, הן התכונות הווירטואליות של המפתח הראשי, המועמד והמפתח הזר. כאן, כמובן, יש גם דקויות, אבל נדבר עליהן מאוחר יותר, כשנמשיך ישירות לעיצוב האופרטור ליצירת יחס הבסיס; 3) סמל מתכת-לשוני "|". סמל זה פירושו המילולי "אוֹ", כמו הסמל המקביל במתמטיקה. השימוש בסמל מתכת-לשוני זה אומר שצריך לבחור בין שני מבנים או יותר המופרדים, בהתאמה, על ידי סמל זה; 4) סמל מתכת-לשוני "...". אליפסה הממוקמת מיד אחרי כל יחידות תחביריות פירושה אפשרות חזרות אלמנטים תחביריים אלה הקודמים לסמל המתכת-לשוני; 5) סמל מתכת-לשוני ",..". סמל זה אומר כמעט אותו דבר כמו הקודם. רק כאשר משתמשים בסמל המטאלשוני ",..", הִשָׁנוּת מתרחשות מבנים תחביריים מופרד בפסיקיםוזה לרוב הרבה יותר נוח. בהתחשב בכך, אנו יכולים לדבר על השקילות של שני המבנים התחביריים הבאים: יחידה [, יחידה]... и יחידה,.. ; 2. דוגמה ליצירת קשר בסיסי בערך פסאודוקוד כעת, לאחר שהבהרנו את המשמעויות של הסמלים המתכת-לשוניים העיקריים המשמשים בעת כתיבת אופרטור יצירת יחס הבסיס בפסאודוקוד, אנו יכולים להמשיך לבחינה בפועל של האופרטור הזה עצמו. כפי שניתן להבין מההפניות לעיל, האופרטור ליצירת יחס בסיס בערך הפסאודו-קוד כולל הצהרות על תכונות בסיס ווירטואליות, מפתחות ראשיים, מועמדים ומפתחות זרים. בנוסף, כפי שיוצג ויוסבר לעיל, אופרטור זה מכסה גם אילוצי ערך תכונה ואילוצי tuple, כמו גם אילוצי שלמות התייחסותית. שני האילוצים הראשונים, כלומר אילוץ ערך התכונה והאילוץ של tuple, מוכרזים אחרי המילה השמורה המיוחדת לבדוק. אילוצי שלמות התייחסות יכולים להיות משני סוגים: בעדכון, שפירושו "בעת עדכון", ו על מחיקה, שפירושו "במחיקה". מה זה אומר? המשמעות היא שבעת עדכון או מחיקה של תכונות של מערכות יחסים שאליהם מתייחס מפתח זר, יש לשמור על שלמות המדינה. (נדבר על זה יותר מאוחר). אופרטור יצירת יחס הבסיס עצמו משמש אותנו שכבר למדנו - האופרטור צור, רק כדי ליצור קשר בסיסי, מילת המפתח מתווספת שולחן ("יַחַס"). וכמובן, מכיוון שהקשר עצמו גדול יותר וכולל את כל המבנים שנדונו קודם לכן, כמו גם מבנים נוספים חדשים, אופרטור היצירה יהיה מרשים למדי. אז בואו נכתוב בפסאודוקוד את הצורה הכללית של האופרטור המשמש ליצירת יחסים בסיסיים: צור טבלה שם יחס בסיס { שם מאפיין בסיס סוג ערך תכונת בסיס לבדוק (מגבלת ערך תכונה) {אפס | לא ריק} ברירת מחדל (ערך ברירת מחדל) },.. [שם תכונה וירטואלית as (נוסחת חישוב) ],.. [,לבדוק (אילוץ טופל)] [,המפתח הראשי (שם מאפיין,..)] [,מפתח המועמד (שם מאפיין,..)]... [,- מפתח זר (שם מאפיין,..) אזכור שם קשר התייחסות (שם תכונה,..) בעדכון { הגבל | אשד | הגדר Null} במחיקה { הגבל | אשד | הגדר Null} ] ... אז, אנו רואים שניתן להכריז על מספר תכונות בסיסיות ווירטואליות, מפתחות מועמדים ומפתחות זרים, שכן לאחר הקונסטרוקציות התחביריות המתאימות יש סמל מתכתי ",.." לאחר ההכרזה על המפתח הראשוני, סמל זה אינו קיים, מכיוון שיחסי הבסיס, כאמור, מאפשרים רק מפתח ראשי אחד. לאחר מכן, בואו נסתכל מקרוב על מנגנון ההצהרה. תכונות בסיסיות. כאשר מתארים תכונה כלשהי באופרטור יצירת יחס הבסיס, במקרה הכללי, מצוין השם, הסוג, ההגבלות על הערכים שלה, דגל התוקף של Null-values וערכי ברירת המחדל. קל לראות שהסוג של תכונה ומגבלות הערך שלה קובעות את התחום שלה, כלומר, ממש את קבוצת הערכים התקפים עבור התכונה הספציפית הזו. הגבלת ערך תכונה נכתב כתנאי התלוי בשם התכונה. הנה דוגמה קטנה כדי להקל על הבנת החומר הזה: צור טבלה שם יחס בסיס קורס מספר שלם לבדוק (1 <= קורס וקורס <= 5; כאן, התנאי "1 <= כותרת וכותרת <= 5" יחד עם ההגדרה של סוג נתונים שלמים באמת מתנים לחלוטין את קבוצת הערכים המותרים של התכונה, כלומר ממש התחום שלה. דגל הקצבה של ערכי Null (Null | לא Null) אוסר (לא Null) או, להיפך, מאפשר (Null) הופעה של ערכי Null בין ערכי תכונה. אם ניקח את הדוגמה שנדונה זה עתה, המנגנון להחלת דגלים של תוקף אפס הוא כדלקמן: צור טבלה שם יחס בסיס קורס מספר שלם לבדוק (1 <= קורס וקורס <= 5); לא ריק; לכן, מספר הקורס של סטודנט לעולם לא יכול להיות ריק, לא יכול להיות לא ידוע למהדרים של מסדי נתונים, ואינו יכול לא להתקיים. ערכי ברירת מחדל (ברירת מחדל (ערך ברירת מחדל)) משמשים בעת הוספת tuple לקשר אם ערכי התכונה אינם מוגדרים במפורש בהצהרת ה-insert. מעניין לציין שערכי ברירת המחדל יכולים להיות גם ערכי Null, כל עוד ערכי Null עבור התכונה הספציפית הזו מוכרזים כתקפים. עכשיו שקול את ההגדרה תכונה וירטואלית באופרטור יצירת קשרי בסיס. כפי שאמרנו קודם, הגדרת תכונה וירטואלית מורכבת מהגדרת נוסחאות לחישוב שלה באמצעות תכונות בסיס אחרות. הבה נשקול דוגמה להכרזה על תכונה וירטואלית "Cost Rub". בצורה של נוסחה בהתאם לתכונות הבסיסיות "משקל ק"ג" ו"מחיר שפשוף לק"ג". צור טבלה שם יחס בסיס משקל (ק"ג תכונת בסיס ערך סוג משקל ק"ג לבדוק (הגבלת ערך התכונה Weight Kg) לא ריק ברירת מחדל (ערך ברירת מחדל) מחיר, לשפשף. לק"ג סוג הערך של תכונת הבסיס Price Rub. לק"ג לבדוק (הגבלת ערך התכונה Price Rub. לק"ג) לא ריק ברירת מחדל (ערך ברירת מחדל) ... עלות, לשפשף. as (משקל ק"ג * מחיר רובל לק"ג) קצת קודם לכן, הסתכלנו על אילוצי תכונות, שנכתבו כתנאים התלויים בשמות התכונות. כעת שקול את הסוג השני של אילוצים שהוכרזו בעת יצירת יחס בסיס, כלומר אילוצי tuple. מהו אילוץ טופל, במה הוא שונה מאילוץ תכונה? אילוץ tuple נכתב גם כתנאי התלוי בשם תכונת הבסיס, אבל רק במקרה של אילוץ tuple, התנאי יכול להיות תלוי במספר שמות של תכונות בו-זמנית. שקול דוגמה הממחישה את מנגנון העבודה עם אילוצי tuple: צור טבלה שם יחס בסיס דקות משקל ק"ג סוג ערך של תכונת בסיס מינימום משקל ק"ג לבדוק (הגבלת ערך התכונה מינימום משקל ק"ג) לא ריק ברירת מחדל (ערך ברירת מחדל) משקל מקסימלי ק"ג סוג ערך של תכונת בסיס מקסימום משקל ק"ג לבדוק (הגבלה של ערך התכונה המקסימלי משקל ק"ג) לא ריק ברירת מחדל (ערך ברירת מחדל) לבדוק (0 < דקה משקל ק"ג ו min Weight Kg < max Weight Kg); לפיכך, החלת אילוץ על tuple מסתכמת בהחלפת ערכי ה tuple בשמות תכונות. הבה נעבור לשקול את האופרטור ליצירת קשרי בסיס. לאחר ההכרזה, תכונות בסיס ווירטואליות עשויות להיות מוצהרות או לא. מפתחות: ראשוני, מועמד וחיצוני. כפי שאמרנו קודם, תת-סכימה של יחס בסיס שביחס בסיס אחר (או אותו) תואם למפתח ראשוני או מועמד בהקשר של היחס הראשון נקראת מפתח זר. מפתחות זרים מייצגים מנגנון קישור טפולים של כמה יחסים על tuples של יחסים אחרים, כלומר ישנן הצהרות מפתח זר הקשורות להטלת מה שנקרא כבר. אילוצי יושרה התייחסותיים. (אילוץ זה יהיה המוקד של ההרצאה הבאה, שכן שלמות המדינה (כלומר, היושרה הנאכפת על ידי אילוצי יושרה) היא קריטית להצלחת הקשר הבסיסי ומסד הנתונים כולו.) הכרזה על מפתחות ראשיים ומועמדים, בתורה, כופה את אילוצי הייחודיות המתאימים על סכימת יחסי הבסיס, עליה דנו קודם לכן. ולבסוף, יש לומר על האפשרות למחוק את יחס הבסיס. לעתים קרובות בפרקטיקה של עיצוב מסד נתונים, יש צורך להסיר קשר מיותר ישן כדי לא לבלבל את קוד התוכנית. ניתן לעשות זאת באמצעות האופרטור המוכר כבר ירידה. בצורתו הכללית המלאה, אופרטור המחיקה של יחס הבסיס נראה כך: זרוק שולחן שם יחס הבסיס; 3. מגבלת יושרה לפי מדינה אילוץ יושרה אובייקט נתונים יחסי החל מ הוא מה שנקרא אינוריאנט נתונים. יחד עם זאת, יש להבחין ביושרה מאבטחה, אשר, בתורה, מרמזת על הגנה על נתונים מפני גישה בלתי מורשית אליהם כדי לחשוף, לשנות או להרוס נתונים. באופן כללי, מגבלות שלמות על אובייקטי נתונים יחסיים מסווגים לפי רמות היררכיה אותם אובייקטי נתונים יחסיים (ההיררכיה של אובייקטי נתונים יחסיים היא רצף של מושגים מקוננים: "תכונה - tuple - קשר - מסד נתונים"). מה זה אומר? משמעות הדבר היא שמגבלות היושרה תלויות ב: 1) ברמת התכונה - מערכי תכונה; 2) ברמת הטפול - מערכי הטפול, כלומר מערכי מספר תכונות; 3) ברמת היחסים - מיחס, כלומר מכמה טפולים; 4) ברמת מסד הנתונים - ממספר קשרים. אז, עכשיו רק נשאר לנו לשקול ביתר פירוט את מגבלות היושרה על מצב כל אחד מהמושגים לעיל. אבל ראשית, בואו ניתן את המושגים של תמיכה פרוצדורלית והצהרתית לאילוצי יושרה של המדינה. אז, תמיכה במגבלות יושרה יכולה להיות משני סוגים: 1) נוֹהָלִי, כלומר, נוצר על ידי כתיבת קוד תוכנית; 2) הַצהָרָתִי, כלומר, נוצר על ידי הכרזה על הגבלות מסוימות עבור כל אחד מהמושגים המקוננים לעיל. תמיכה הצהרתית לאילוצי יושרה מיושמת בהקשר של הצהרת Create ליצירת קשר הבסיס. בואו נדבר על זה ביתר פירוט. בואו נתחיל לשקול את קבוצת ההגבלות מתחתית הסולם ההיררכי של אובייקטי נתונים יחסיים, כלומר מהמושג של תכונה. אילוץ רמת תכונה כולל: 1) הגבלות על סוג ערכי התכונה. לדוגמה, תנאי מספר שלם לערכים, כלומר תנאי מספר שלם לתכונת "קורס" מאחד מיחסי הבסיס שנדונו קודם לכן; 2) אילוץ ערך תכונה, שנכתב כתנאי התלוי בשם התכונה. לדוגמה, בניתוח אותו יחס בסיסי כמו בפסקה הקודמת, אנו רואים שביחס זה יש גם מגבלה על ערכי תכונה באמצעות האפשרות לבדוק, כלומר: לבדוק (1 <= קורס וקורס <= 5); 3) אילוץ ברמת התכונה כולל אילוצי ערך Nul המוגדרים על ידי דגל התוקף הידוע (Null) או, להיפך, אי קבילות (לא Null) של ערכי Null. כפי שהזכרנו קודם לכן, שני האילוצים הראשונים מגדירים את אילוץ התחום של התכונה, כלומר את הערך של ערכת ההגדרות שלה. יתרה מכך, על פי הסולם ההיררכי של אובייקטי נתונים יחסיים, עלינו לדבר על tuples. כך, אילוץ רמת tuple מצטמצם לאילוץ טופל ונכתב כתנאי שתלוי בשמות של מספר תכונות בסיסיות של סכימת היחסים, כלומר אילוץ שלמות המצב הזה הוא הרבה יותר קטן ופשוט מהדומה, רק מתאים לתכונה. ושוב, יהיה זה שימושי להיזכר בדוגמה של הקשר הבסיסי שעברנו קודם לכן, שיש לו את אילוץ הטפול שאנו צריכים כעת, כלומר: לבדוק (0 < דקה משקל ק"ג ו min Weight Kg < max Weight Kg); ולבסוף, המושג המשמעותי האחרון בהקשר של מגבלת היושרה על המדינה הוא מושג רמת היחסים. כפי שאמרנו בעבר, מגבלה ברמת מערכת היחסים כולל הגבלת הערכים של הבסיסי (המפתח הראשי) והמועמד (מפתח המועמד) מפתחות. זה מוזר שההגבלות המוטלות על מאגרי מידע אינן עוד אילוצי יושרה של המדינה, אלא אילוצי יושרה התייחסותיים. 4. אילוצי יושרה התייחסותיים אז, האילוץ ברמת מסד הנתונים כולל את אילוץ השלמות ההתייחסותי של מפתח זר (- מפתח זר). כבר הזכרנו זאת בקצרה כשדיברנו על אילוצי יושרה התייחסותיים בעת יצירת קשר בסיס ומפתחות זרים. עכשיו הגיע הזמן לדבר על הרעיון הזה ביתר פירוט. כפי שאמרנו קודם, המפתח הזר של יחס הבסיס המוצהר מתייחס למפתח הראשוני או המועמד של יחס בסיס אחר (לרוב). נזכיר שבמקרה זה, היחס אליו מתייחס המפתח הזר נקרא התייחסות או שֶׁל הַהוֹרִים, מכיוון שהוא סוג של "מוליץ" תכונה אחת או תכונות מרובות ביחס הבסיס המתייחס. ובתמורה, יחס המכיל מפתח זר נקרא יֶלֶד, גם מסיבות ברורות. מה ה אילוץ יושרה התייחסותי? וזה מורכב מהעובדה שכל ערך של המפתח הזר של מערכת היחסים הבת חייב בהכרח להתאים לערך של כל מפתח של קשרי האב, אלא אם הערך של המפתח הזר מכיל ערכי Null בתכונות כלשהן. טפולים של יחסי ילד שמפרים תנאי זה נקראים תְלִיָה. ואכן, אם המפתח הזר של קשר הילד מתייחס לתכונה שאינה קיימת בפועל ביחסי האב, אז הוא אינו מתייחס לכלום. בדיוק מהמצבים האלה יש להימנע בכל דרך אפשרית, ומשמעות הדבר היא שמירה על שלמות התייחסותית. אבל, מתוך ידיעה ששום מסד נתונים לא יאפשר לעולם יצירת טאפל משתלשל, מפתחים מוודאים שאין טופלים משתלשלים בתחילה במסד הנתונים ושכל המפתחות הזמינים מתייחסים לתכונה אמיתית מאוד של מערכת היחסים ההורה. עם זאת, ישנם מצבים שבהם נוצרים tuples משתלשלים כבר במהלך פעולת בסיס הנתונים. מהם המצבים האלה? זה ידוע שכאשר מוסרים tuples מיחס האב או כאשר ערך המפתח של tuple של יחס ההורה מתעדכן, ניתן להפר את השלמות ההתייחסותית, כלומר, tuples משתלשלים יכולים להתרחש. כדי לא לכלול את האפשרות של התרחשותם בעת הצהרת ערך מפתח זר, מצוין אחד מהבאים: שלוש זמין תקנות שמירה על שלמות התייחסות, המיושמת בהתאם בעת עדכון ערך המפתח ביחסי האב (כלומר, כפי שהזכרנו קודם לכן, בעדכון) או בעת הסרת tuple מקשר האב (על מחיקה). יש לציין כי הוספת טופלה חדשה ליחסי ההורים אינה יכולה לשבור את היושרה ההתייחסותית, מסיבות ברורות. אחרי הכל, אם הטפול הזה רק היה נוסף ליחס הבסיס, שום תכונה לא הייתה יכולה להתייחס אליו קודם לכן בגלל היעדרו! אז מה הם שלושת הכללים האלה המשמשים לשמירה על שלמות התייחסות במאגרי מידע? בואו נרשום אותם. 1. להגבילאו כלל ההגבלה. אם, בעת הגדרת יחס הבסיס שלנו, בעת הכרזה על מפתחות זרים באילוץ שלמות התייחסות, יישם כלל זה של שמירה עליו, אז עדכון מפתח ביחס האב או מחיקת tuple מקשר האב פשוט לא יכול להתבצע אם tuple זה הוא התייחסות על ידי טופלה אחת לפחות של יחס הילד, כלומר מבצע להגביל אוסר באופן מוחלט על ביצוע כל פעולות שעלולות להוביל להופעת טפלים תלויים. אנו מדגים את היישום של כלל זה בדוגמה הבאה. תנו שני יחסים: יחס של ההורים
יחסי ילדים
אנו רואים שהטופלים של יחסי הילד (2,...) ו-(2,...) מתייחסים לטופל יחסי ההורה (..., 2), והטופלת יחסי הילד (3,...) מתייחסת ל הגישה ההורית (..., 3). הטפול (100,...) של יחס הילד משתלשל ואינו תקף. כאן, רק הטפולים של קשרי האב (..., 1) ו- (..., 4) מאפשרים לעדכן ערכי מפתח ולמחוק את הטפולים מכיוון שהם אינם מופנים על ידי אף אחד מהמפתחות הזרים של קשר הילד. בואו נרכיב את האופרטור ליצירת יחס בסיסי, הכולל את ההצהרה של כל המפתחות לעיל: צור טבלה יחס של ההורים מפתח ראשי מספר שלם לא ריק המפתח הראשי (מפתח ראשי) צור טבלה יחסי ילדים מפתח_זר מספר שלם Null - מפתח זר (מפתח_זר) אזכור יחסי הורים (מפתח_ראשי) בעדכון הגבל מחק הגבל 2. אשדאו כלל שינוי מפל. אם, כשהכרזנו מפתחות זרים ביחסי הבסיס שלנו, השתמשנו בכלל של שמירה על שלמות התייחסות אשד, ואז עדכון מפתח ביחס האב או מחיקת tuple מקשר האב גורם לעדכון או מחיקה אוטומטית של המפתחות והטופלים המתאימים של הקשר הבן. הבה נסתכל על דוגמה כדי להבין טוב יותר כיצד פועל כלל השינויים במפל. תנו ליחסים הבסיסיים שכבר מוכרים לנו מהדוגמה הקודמת: יחס של ההורים
и יחסי ילדים
נניח שאנו מעדכנים כמה tuples בטבלה המגדירה את הקשר "יחס הורה", כלומר, נחליף את tuple (..., 2) עם tuple (..., 20), כלומר נקבל יחס חדש: יחס של ההורים
ובמקביל בהצהרה על יצירת הקשר הבסיסי שלנו "יחסי ילדים" בהכרזת מפתחות זרים, השתמשנו בכלל של שמירה על שלמות התייחסות אשד, כלומר האופרטור ליצירת קשר הבסיס שלנו נראה כך: צור טבלה יחס של ההורים מפתח ראשי מספר שלם לא ריק המפתח הראשי (מפתח ראשי) צור טבלה יחסי ילדים מפתח_זר מספר שלם Null - מפתח זר (מפתח_זר) אזכור יחסי הורים (מפתח_ראשי) על עדכון Cascade על מחיקת Cascade אז מה קורה לקשר הילד כאשר קשר ההורה מתעדכן באופן שתואר לעיל? זה יקבל את הטופס הבא: יחסי ילדים
כך, אכן, הכלל אשד מספק עדכון מדורג של כל הטפולים ביחסי הילד בתגובה לעדכונים ביחסי האב. 3. הגדר Nullאו כלל הקצאה אפס. אם, בהצהרה על יצירת הקשר הבסיסי שלנו, כאשר אנו מצהירים על מפתחות זרים, אנו מיישמים את הכלל של שמירה על שלמות התייחסות הגדר Null, אז עדכון המפתח של קשר אב או מחיקת tuple מקשר אב כרוך בהקצאה אוטומטית של ערכי Null לאותם תכונות מפתח זר של קשר הילד המאפשרים ערכי Null. לכן, הכלל ישים אם קיימות תכונות כאלה. בואו נסתכל על דוגמה שכבר השתמשנו בה בעבר. נניח שניתנו לנו שני יחסים בסיסיים: "הורות"
יחסי ילדים
כפי שאתה יכול לראות, תכונות של קשרי ילדים מאפשרות ערכי Null, ומכאן הכלל הגדר Null ישים במקרה הספציפי הזה. נניח כעת שהטופל (..., 1) הוסר מיחס האב והטופל (..., 2) עודכן, כמו בדוגמה הקודמת. לפיכך, קשר האב מקבל את הצורה הבאה: יחס של ההורים
לאחר מכן, תוך התחשבות בעובדה שכאשר הכרזנו על המפתחות הזרים של יחסי הילד, החלנו את הכלל של שמירה על שלמות התייחסות הגדר Null, קשר הילד ייראה כך: יחסי ילדים
ה-tuple (..., 1) לא הופנה על ידי מפתח יחס ילד, כך שלמחיקה שלו אין השלכות. אופרטור יצירת קשר הבסיס עצמו באמצעות הכלל הגדר Null כאשר מכריזים על מפתחות זרים, הקשר נראה כך: צור טבלה יחס של ההורים מפתח ראשי מספר שלם לא ריק המפתח הראשי (מפתח ראשי) צור טבלה יחסי ילדים מפתח_זר מספר שלם Null - מפתח זר (מפתח_זר) אזכור יחסי הורים (מפתח_ראשי) בעדכון הגדר Null במחיקה הגדר Null אז, אנו רואים שהנוכחות של שלושה כללים שונים לשמירה על שלמות התייחסות מבטיחה שבביטויים בעדכון и על מחיקה הפונקציות עשויות להשתנות. יש לזכור ולהבין שהכנסת טאפלים ליחסי ילדים או עדכון ערכי המפתח של יחסי ילדים לא יבוצעו אם הדבר יוביל לפגיעה בשלמות ההתייחסותית, כלומר להופעת טופלים תלויים כביכול. הסרת טופלים ממערכת יחסים עם ילדים בשום פנים ואופן לא יכולה להוביל להפרה של היושרה ההתייחסותית. מעניין שיחס ילד יכול לפעול בו-זמנית כהורה עם כללים משלו לשמירה על שלמות התייחסותית, אם המפתחות הזרים של יחסי בסיס אחרים מתייחסים לכמה מהתכונות שלו כמפתחות ראשוניים. אם מתכנתים רוצים להבטיח שהשלמות ההתייחסותית נאכפת על ידי כללים מסוימים מלבד הכללים הסטנדרטיים לעיל, אזי תמיכה פרוצדורלית לכללים לא סטנדרטיים כאלה לשמירה על שלמות התייחסות ניתנת בעזרת מה שנקרא טריגרים. למרבה הצער, התייחסות מפורטת של מושג זה לא יורדת לתוך מהלך ההרצאות שלנו. 5. מושג המדדים יצירת מפתחות בקשרי בסיס מקושרת אוטומטית ליצירת אינדקסים. הבה נגדיר את הרעיון של אינדקס. אינדקס - זהו מבנה נתוני מערכת המכיל רשימת ערכים מסודרת בהכרח של מפתח עם קישורים לאותם טפולים של היחס שבהם ערכים אלו מתרחשים. ישנם שני סוגים של אינדקסים במערכות ניהול מסדי נתונים: 1) פשוט. אינדקס פשוט נלקח עבור תת-סכימה סכימה של יחס הבסיס מתכונה אחת; 2) מרוכבים. בהתאם לכך, אינדקס מורכב הוא אינדקס עבור תת-סכימה המורכבת ממספר תכונות. אבל, בנוסף לחלוקה לאינדקסים פשוטים ומרוכבים, במערכות ניהול מסדי נתונים יש חלוקה של אינדקסים לאינדקסים ייחודיים ולא ייחודיים. כך: 1) ייחודי אינדקסים הם אינדקסים המתייחסים לכל היותר לתכונה אחת. אינדקסים ייחודיים תואמים בדרך כלל את המפתח הראשי של היחס; 2) לא ייחודי אינדקסים הם אינדקסים שיכולים להתאים למספר תכונות בו-זמנית. מפתחות לא ייחודיים, בתורם, מתאימים לרוב למפתחות הזרים של מערכת היחסים. שקול דוגמה הממחישה את חלוקת האינדקסים לייחודיים ולא-ייחודיים, כלומר שקול את הקשרים הבאים המוגדרים בטבלאות:
כאן, בהתאמה, מפתח ראשי הוא המפתח העיקרי של מערכת היחסים, מפתח זר הוא המפתח הזר. ברור שביחסים אלו, האינדקס של תכונת המפתח Primary הוא ייחודי, שכן הוא מתאים למפתח הראשי, כלומר תכונה אחת, והאינדקס של תכונת Foreign key אינו ייחודי, מכיוון שהוא מתאים למפתח זר. מפתחות. והערך שלו "20" מתאים גם לשורה הראשונה וגם לשורה השלישית של טבלת היחסים. אבל לפעמים ניתן ליצור אינדקסים ללא קשר למפתחות. זה נעשה במערכות ניהול מסדי נתונים כדי לתמוך בביצוע פעולות מיון וחיפוש. לדוגמה, חיפוש דיכוטומי של ערך אינדקס ב-tuples מיושם במערכות ניהול מסד נתונים בעשרים איטרציות. מאיפה הגיע המידע הזה? הם הושגו על ידי חישובים פשוטים, כלומר כדלקמן: 106 = (103)2 = 220; אינדקסים נוצרים במערכות ניהול מסדי נתונים באמצעות הצהרת Create המוכרת לנו כבר, אך רק בתוספת מילת המפתח אינדקס. מפעיל כזה נראה כך: צור אינדקס שם אינדקס On שם יחס בסיס (שם תכונה,..); כאן אנו רואים את הסמל המט-לשוני המוכר ",.." המציין את האפשרות לחזור על טיעון מופרד בפסיק, כלומר, ניתן ליצור אינדקס המתאים למספר תכונות באופרטור זה. אם אתה רוצה להכריז על אינדקס ייחודי, אתה מוסיף את מילת המפתח הייחודית לפני מילת האינדקס, ואז הצהרת היצירה כולה ביחס אינדקס הבסיס הופכת: צור אינדקס ייחודי שם אינדקס On שם יחס בסיס (שם תכונה); ואז, בצורה הכללית ביותר, אם נזכור את הכלל לייעוד אלמנטים אופציונליים (הסמל המתכתי []), אופרטור יצירת האינדקס ביחס הבסיסי ייראה כך: צור אינדקס [ייחודי] שם אינדקס On שם יחס בסיס (שם תכונה,..); אם ברצונך להסיר אינדקס שכבר קיים מיחס הבסיס, השתמש באופרטור Drop, המוכר לנו גם הוא: מדד ירידה {שם יחס בסיס. שם אינדקס},.. ; מדוע שם האינדקס המותאם "שם יחס בסיס. שם אינדקס" משמש כאן? אופרטור הורדת אינדקס משתמש תמיד בשם המותאם שלו מכיוון ששם האינדקס חייב להיות ייחודי בתוך אותו קשר, אך לא יותר. 6. שינוי יחסים בסיסיים כדי לעבוד בצורה מוצלחת ופרודוקטיבית עם קשרי בסיס שונים, לעתים קרובות מפתחים צריכים לשנות את מערכת היחסים הבסיסית הזו בדרך כלשהי. מהן אפשרויות השינוי הנדרשות העיקריות בהן נתקלים לרוב בפרקטיקה של עיצוב מסד נתונים? בואו נרשום אותם: 1) הכנסת tuples. לעתים קרובות מאוד אתה צריך להכניס tuples חדשים ליחס בסיס שכבר נוצר; 2) עדכון ערכי תכונות. והצורך בשינוי זה בתרגול התכנות נפוץ אפילו יותר מהקודם, מכיוון שכאשר יגיע מידע חדש על הטיעונים של מסד הנתונים שלך, תצטרך בהכרח לעדכן מידע ישן; 3) הסרת tuples. ובהסתברות שווה בערך, יש צורך להסיר מהיחס הבסיסי את אותם tuples שנוכחותם במסד הנתונים שלך כבר לא נדרשת עקב מידע חדש שהתקבל. אז, תיארנו את הנקודות העיקריות של שינוי היחסים הבסיסיים. כיצד ניתן להשיג כל אחת מהיעדים הללו? במערכות ניהול מסדי נתונים, לרוב ישנם אופרטורים מובנים ובסיסיים לשינוי מערכות יחסים. בואו נתאר אותם בערך פסאודו-קוד: 1) הכנס מפעיל לתוך יחס הבסיס של הטפולים החדשים. זה המפעיל הַבלָעָה. זה נראה כמו זה: הכנס לתוך שם יחס בסיס (שם תכונה,..) ערכים (ערך תכונה,..); הסמל המט-לשוני ",.." אחרי שם התכונה וערך התכונה אומר לנו שאופרטור זה מאפשר להוסיף מספר תכונות ליחס הבסיס בו-זמנית. במקרה זה, עליך לרשום את שמות המאפיינים וערכי המאפיינים, מופרדים בפסיקים, בסדר עקבי. מילת מפתח אל תוך בשילוב עם השם הכללי של המפעיל הַבלָעָה פירושו "הוסף לתוך" ומציין באיזה יחס יש להכניס את התכונות בסוגריים. מילת מפתח ערכים בהצהרה זו, ופירושו "ערכים", "ערכים", אשר מוקצים לתכונות אלה שהוכרזו לאחרונה; 2) עכשיו שקול מפעיל עדכון ערכי תכונה ביחס הבסיס. למפעיל הזה קוראים עדכון, שמתורגם מאנגלית ופירושו המילולי "עדכון". בואו ניתן את הצורה הכללית המלאה של אופרטור זה בסימון פסאודו-קוד ונפענח אותו: עדכון שם יחס בסיס לקבוע {שם תכונה - ערך תכונה},.. איפה מַצָב; אז, בשורה הראשונה של האופרטור אחרי מילת המפתח עדכון נכתב שם יחס הבסיס שבו יש לבצע עדכונים. מילת המפתח Set מתורגמת מאנגלית ל"set", ושורה זו של ההצהרה מציינת את שמות התכונות שיש לעדכן ואת ערכי התכונה החדשים המתאימים. ניתן לעדכן מספר תכונות בו-זמנית בהצהרה אחת, הנובעת מהשימוש בסמל המתכת-לשוני ",..". בשורה השלישית אחרי מילת המפתח איפה נכתב תנאי המראה בדיוק אילו תכונות של יחס בסיס זה צריכות להתעדכן; 3) מפעיל מחקמְאַפשֶׁר למחוק כל tuples מיחס הבסיס. בואו נכתוב את צורתו המלאה בפסאודוקוד ונסביר את המשמעות של כל היחידות התחביריות הבודדות: מחק מ שם יחס בסיס איפה מַצָב; מילת מפתח החל מ- בשילוב עם שם המפעיל מחק מתורגם כ"הסר מ". ואחרי מילות המפתח האלה בשורה הראשונה של האופרטור, מצוין שם יחס הבסיס, שממנו יש להסיר את כל הטפולים. ובשורה השנייה של האופרטור אחרי מילת המפתח איפה ("איפה") מציין את התנאי שבו נבחרים tuples שאינם נדרשים עוד ביחס הבסיס שלנו. הרצאה מספר 9. תלות פונקציונלית 1. הגבלת תלות תפקודית אילוץ הייחודיות שנכפה על ידי הצהרות המפתח העיקריות והמועמדות של קשר הוא מקרה מיוחד של האילוץ הקשור למושג תלות תפקודית. כדי להסביר את המושג תלות תפקודית, שקול את הדוגמה הבאה. תנו לנו יחס המכיל נתונים על התוצאות של מפגש מסוים. הסכימה של מערכת יחסים זו נראית כך: מושב (מספר ספר רישום, שם מלא, נושא, כיתה); התכונות "מספר ספר ציונים" ו"נושא" יוצרות מפתח ראשוני מורכב (מכיוון ששתי תכונות מוכרזות כמפתח) של יחס זה. ואכן, שתי התכונות הללו יכולות לקבוע באופן ייחודי את הערכים של כל התכונות האחרות. עם זאת, בנוסף לאילוץ הייחודיות הקשור למפתח זה, היחס חייב בהכרח להיות כפוף לתנאי שפנקס ציונים אחד יונפק לאדם מסוים, ולכן, מבחינה זו, טופלים בעלי אותו מספר ציונים חייבים להכיל את אותם ערכים של המאפיינים "שם משפחה", "שם פרטי ושם אמצעי".
אם יש לנו את הפרגמנט הבא של מסד נתונים מסוים של תלמידי מוסד חינוכי לאחר מפגש מסוים, אז בטופלים עם מספר ציונים של 100, התכונות "שם משפחה", "שם פרטי" ו"פטרונימי" זהות, והתכונות "נושא" ו"הערכה" - אינן תואמות (וזה מובן, כי הם מדברים על נושאים שונים וביצועים בהם). המשמעות היא שהתכונות "שם משפחה", "שם פרטי" ו"פטרונימי" תלוי תפקודית על התכונה "מספר ספר ציונים", בעוד שהתכונות "נושא" ו"הערכה" אינן תלויות מבחינה תפקודית. כך, תלות תפקודית היא תלות בעלת ערך יחיד המוצג בטבלה במערכות ניהול מסדי נתונים. כעת אנו נותנים הגדרה קפדנית של תלות תפקודית. הגדרה: תן X, Y להיות תת-סכמות של הסכימה של היחס S, המגדירים על פני הסכמה S דיאגרמת תלות תפקודית X → Y (קרא את "חץ X Y"). בואו נגדיר אילוצי תלות תפקודית inv<X → Y> כהצהרה שביחס לסכימה S, כל שני טופלים שמתואמים בהשלכה על תת-סכימה X חייבים להתאים גם בהשלכה לתת-סכימה Y. בוא נכתוב את אותה הגדרה בצורת נוסחה: Inv<X → Y> r(S) = t1t,2 ∈ r(t1[X] = t2[X] ⇒ t1[Y]=ת2 [Y]), X, Y ⊆ S; באופן מוזר, הגדרה זו משתמשת במושג של פעולת השלכה לא-נארית, שבה נתקלנו קודם לכן. ואכן, איך אחרת, אם אינך משתמש בפעולה זו, להראות את השוויון של שתי עמודות בטבלת היחסים, ולא שורות, זו לזו? לכן, כתבנו במונחים של פעולה זו שצירוף המקרים של tuples בהשלכה על תכונה כלשהי או כמה תכונות (תת-סכימה X) בהחלט יגרור את צירוף המקרים של אותן עמודות-טופלות על תת-סכימה Y במקרה ש-Y תלוי פונקציונלית בה. X . מעניין לציין שבמקרה של תלות תפקודית של Y ב-X, אומרים גם ש-X מגדירה פונקציונלית Y או מה Y תלוי תפקודית על X. בסכימת התלות הפונקציונלית X → Y, תת-מעגל X נקרא צד שמאל, ותת-מעגל Y נקרא צד ימין. בפרקטיקה של עיצוב מסד נתונים, סכימת תלות פונקציונלית מכונה בדרך כלל תלות פונקציונלית לקיצור. סוף ההגדרה. במקרה המיוחד כאשר הצד הימני של התלות הפונקציונלית, כלומר תת-סכימה Y, תואם את כל הסכימה של הקשר, אילוץ התלות הפונקציונלי הופך לאילוץ ייחוד מפתח ראשוני או מועמד. בֶּאֱמֶת: inv r(S) = ∀ t1t,2 ∈ r(t1[K] = t2 [K] → ט1(S) = t2(S)), K ⊆ S; רק שבהגדרת תלות פונקציונלית, במקום תת-סכימה X, אתה צריך לקחת את הייעוד של המפתח K, ובמקום הצד הימני של התלות הפונקציונלית, תת-סכמה Y, לקחת את כל סכמת היחסים S, כלומר, ואכן, ההגבלה על הייחודיות של מפתחות היחסים היא מקרה מיוחד של הגבלת תלות תפקודית כאשר הצד הימני הוא סכמות שוות של תלות תפקודית בכל תכנית היחסים. להלן דוגמאות לתמונה של תלות תפקודית: {מספר ספר חשבון} ← {שם משפחה, שם פרטי, פטרונימי}; {מספר ספר ציונים, נושא} ← {כיתה}; 2. כללי ההסקה של ארמסטרונג אם יחס בסיסי כלשהו עונה על תלות פונקציונלית המוגדרת וקטורית, אז בעזרת כללי היסק מיוחדים שונים ניתן להשיג תלות פונקציונלית אחרת שהיחס הבסיסי הזה בהחלט יספק. דוגמה טובה לכללים מיוחדים כאלה הם כללי ההסקה של ארמסטרונג. אבל לפני שנמשיך לניתוח של כללי ההיסק של ארמסטרונג עצמם, הבה נציג סמל מתכת-לשוני חדש "├", הנקרא סמל מטא-קביעה של נגישות. סמל זה, בעת ניסוח כללים, נכתב בין שני ביטויים תחביריים ומציין שהנוסחה מימין לו נגזרת מהנוסחה שמשמאל לו. הבה ננסח כעת את כללי ההסקה של ארמסטרונג בעצמם בצורה של המשפט הבא. מִשׁפָּט. הכללים הבאים תקפים, הנקראים כללי ההסקה של ארמסטרונג. כלל מסקנות 1. ├ X → X; כלל מסקנות 2. X → Y├ X ∪ Z → Y; כלל מסקנות 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; כאן X, Y, Z, W הן תת-סכמות שרירותיות של סכימת היחס S. סמל מטא-הצהרת הגזירה מפריד בין רשימות הנחות ורשימות של קביעות (מסקנות). 1. כלל ההסקה הראשון נקרא "רפלקסיביות" ונקרא כך: "הכלל נגזר:" X טומן בחובו X ". זהו החוק הפשוט ביותר מבין כללי הגזירה של ארמסטרונג. הוא נגזר ממש מאוויר דליל. מעניין לציין שתלות תפקודית שיש לה גם חלק שמאל וגם ימין נקראת רפלקסיבי. על פי כלל הרפלקסיביות, האילוץ של תלות רפלקסיבית מתבצע באופן אוטומטי. 2. כלל ההסקה השני נקרא "חידוש" ונקרא כך: "אם X קובע פונקציונלית Y, אז הכלל נגזר: "האיחוד של תת-מעגלים X ו-Z גורר פונקציונלית Y"". כלל ההשלמה מאפשר לך להרחיב את הצד השמאלי של אילוץ התלות הפונקציונלית. 3. כלל ההסקה השלישי נקרא "פסאודוטרנזיטיביות" ונקרא כך: "אם תת-מעגל X טומן בחובו תת-מעגל Y, והאיחוד של תת-מעגלים Y ו-W טומן בחובו Z, אזי הכלל נגזר: "האיחוד של תת-מעגלים X ו-W קובע באופן פונקציונלי את תת-מעגל Z"". כלל הפסאודו-טרנזיטיביות מכליל את כלל הטרנזיטיביות המתאים למקרה המיוחד W: = 0. הבה ניתן סימון פורמלי של כלל זה: X→Y, Y→Z ├X→Z. יש לציין כי הנחות היסוד והמסקנות שניתנו קודם לכן הוצגו בצורה מקוצרת על ידי כינויים של סכימות תלות פונקציונליות. בצורה מורחבת, הם תואמים לאילוצי התלות הפונקציונליים הבאים. כלל מסקנות 1. inv r(S); כלל מסקנות 2. inv r(S) ⇒ inv r(S); כלל מסקנות 3. inv r(S) & inv r(S) ⇒ inv r(S); לצייר ראיות חוקי ההסקה הללו. 1. הוכחת הכלל רפלקסיביות נובע ישירות מההגדרה של אילוץ התלות הפונקציונלית כאשר תת-סכימה X מוחלפת בתת-מעגל Y. אכן, קח את אילוץ התלות הפונקציונלית: inv r(S) והחלפת X במקום Y לתוכו, נקבל: inv r(S), וזהו כלל הרפלקסיביות. כלל הרפלקסיביות מוכח. 2. הוכחת הכלל חידוש בואו נמחיש על דיאגרמות של תלות תפקודית. התרשים הראשון הוא דיאגרמת החבילה: הנחת יסוד: X → Y
תרשים שני: מסקנה: X ∪ Z → Y
תנו לטופלים להיות שווים ב-X ∪ Z. ואז הם שווים ב-X. לפי הנחת היסוד, הם יהיו שווים גם ב-Y. כלל המילוי מוכח. 3. הוכחת הכלל פסאודו-טרנזיטיביות נמחיש גם על דיאגרמות, שבמקרה הספציפי הזה יהיו שלושה. התרשים הראשון הוא הנחת היסוד הראשונה: הנחת יסוד 1: X → Y
הנחת יסוד 2: Y ∪ W → Z
ולבסוף, התרשים השלישי הוא דיאגרמת המסקנה: מסקנה: X ∪ W → Z
תן לטופלים להיות שווים ב-X ∪ W. אז הם שווים גם ב-X וגם ב-W. לפי הנחה 1, הם יהיו שווים גם ב-Y. לפיכך, לפי הנחה 2, הם יהיו שווים גם ב-Z. כלל הפסאודוטרנזיטיביות מוכח. כל הכללים מוכחים. 3. כללי מסקנות נגזרות דוגמה נוספת לכללים שבאמצעותם ניתן, במידת הצורך, לגזור כללים חדשים של תלות תפקודית הם מה שנקרא כללי מסקנות נגזרות. מהם הכללים האלה, איך משיגים אותם? זה ידוע שאם אחרים נגזרו מכמה כללים שכבר קיימים על ידי שיטות לוגיות לגיטימיות, אזי הכללים החדשים הללו, הנקראים נגזרים, ניתן להשתמש יחד עם הכללים המקוריים. יש לציין במיוחד שהכללים המאוד שרירותיים הללו הם "נגזרים" בדיוק מכללי ההסקה של ארמסטרונג שעברנו קודם לכן. הבה ננסח את הכללים הנגזרים לגזירת תלות פונקציונלית בצורה של המשפט הבא. מִשׁפָּט. הכללים הבאים נגזרים מכללי ההסקה של ארמסטרונג. כלל מסקנות 1. ├ X ∪ Z → X; כלל מסקנות 2. X → Y, X → Z ├ X ∪ Y → Z; כלל מסקנות 3. X → Y ∪ Z ├ X → Y, X → Z; כאן X, Y, Z, W, כמו במקרה הקודם, הן תת-סכימות שרירותיות של ערכת היחס S. 1. הכלל הנגזר הראשון נקרא כלל הטריוויאליות ונקרא כך: "הכלל נגזר: 'האיחוד של תת-מעגלים X ו-Z כרוך פונקציונלית ב-X'". תלות תפקודית כאשר הצד השמאלי הוא תת-קבוצה של הצד הימני נקראת קַטנוּנִי. על פי כלל הטריוויאליות, אילוצי תלות טריוויאליים נאכפים אוטומטית. מעניין לציין שכלל הטריוויאליות הוא הכללה של כלל הרפלקסיביות, וכמו האחרון, ניתן היה לנבוע ישירות מההגדרה של אילוץ התלות הפונקציונלית. העובדה שהכלל הזה נגזר אינה מקרית וקשורה לשלמות מערכת הכללים של ארמסטרונג. נדבר יותר על שלמות מערכת הכללים של ארמסטרונג מעט מאוחר יותר. 2. הכלל הנגזר השני נקרא כלל התוספת ונקרא כך: "אם תת-מעגל X קובע באופן פונקציונלי את תת-מעגל Y, ו-X קובע בו-זמנית את Z באופן פונקציונלי, אזי הכלל הבא נגזר מהכללים הללו: "X קובע באופן פונקציונלי את האיחוד של תת-מעגלים Y ו-Z". 3. הכלל הנגזר השלישי נקרא כלל השלכתיות או הכללהיפוך תוספים". הוא כתוב כך: "אם תת-המעגל X קובע באופן פונקציונלי את האיחוד של תת-המעגלים Y ו-Z, אזי הכלל הבא נגזר מכלל זה: "X קובע באופן פונקציונלי את תת-המעגל Y ובמקביל X קובע באופן פונקציונלי את תת-המעגל. Z" ", כלומר, אכן, זה הכלל הנגזר הוא כלל התוספתיות ההפוכה. זה מוזר שכללי התוספתיות וההשלכה כפי שהם מיושמים על תלות פונקציונלית עם אותם חלקים שמאליים מאפשרים לשלב או, להיפך, לפצל את החלקים הימניים של התלות. בעת בניית שרשראות מסקנות, לאחר גיבוש כל הנחות היסוד, מיושם כלל הטרנזיטיביות על מנת לכלול תלות פונקציונלית עם הצד הימני במסקנה. לצייר ראיות רשומים כללי מסקנות שרירותיות. 1. הוכחת הכלל טריוויאליות. הבה נבצע את זה, כמו כל ההוכחות הבאות, צעד אחר צעד: 1) יש לנו: X → X (מכלל רפלקסיביות ההסקה של ארמסטרונג); 2) בהמשך יש לנו: X ∪ Z → X (שמושג על ידי יישום תחילה של כלל השלמת ההסקות של ארמסטרונג, ולאחר מכן כתוצאה מהשלב הראשון של ההוכחה). כלל הטריוויאליות הוכח. 2. אנו מבצעים הוכחה שלב אחר שלב של הכלל תוספתיות: 1) יש לנו: X → Y (זוהי הנחה 1); 2) יש לנו: X → Z (זוהי הנחה 2); 3) יש לנו: Y ∪ Z → Y ∪ Z (מכלל רפלקסיביות ההסקה של ארמסטרונג); 4) יש לנו: X ∪ Z → Y ∪ Z (שמושג על ידי יישום כלל הפסאודו-טרנזיטיביות של ההסקה של ארמסטרונג, ולאחר מכן כתוצאה מהשלב הראשון והשלישי של ההוכחה); 5) יש לנו: X ∪ X → Y ∪ Z (שמושג על ידי יישום הכלל של ארמסטרונג של פסאודו-טרנזיטיביות של מסקנות, ולאחר מכן נובע מהשלב השני והרביעי); 6) יש לנו X → Y ∪ Z (נובע מהשלב החמישי). כלל התוספת מוכח. 3. ולבסוף, נבנה הוכחה לכלל השלכה: 1) יש לנו: X → Y ∪ Z, X → Y ∪ Z (זו הנחת יסוד); 2) יש לנו: Y → Y, Z → Z (נגזרת באמצעות כלל רפלקסיביות ההסקה של ארמסטרונג); 3) יש לנו: Y ∪ z → y, Y ∪ z → Z (שמתקבל מכלל השלמת ההסקה של ארמסטרונג והתוצאה מהשלב השני של ההוכחה); 4) יש לנו: X → Y, X → Z (שהושג על ידי יישום כלל הפסאודו-טרנזיטיביות של ההסקה של ארמסטרונג, ולאחר מכן כתוצאה מהשלב הראשון והשלישי של ההוכחה). כלל ההשלכה מוכח. כל כללי ההסקה הנגזרת מוכחים. 4. שלמות מערכת חוקי ארמסטרונג תנו ל-F(S) להיות קבוצה נתונה של תלות פונקציונלית המוגדרת על פני סכימת היחסים S. סמן ב inv האילוץ המוטל על ידי מערכת תלות פונקציונלית זו. בוא נרשום את זה: inv r(S) = ∀X → Y ∈F(S) [inv r(S)]. לכן, קבוצת הגבלות זו המוטלת על ידי תלות פונקציונלית מפוענחת באופן הבא: עבור כל כלל ממערכת התלות הפונקציונלית X → Y השייך לקבוצת התלות הפונקציונלית F(S), הגבלת התלות הפונקציונלית inv r(S) מוגדר על קבוצת היחסים r(S). תנו ליחס כלשהו r(S) לענות על אילוץ זה. על ידי יישום כללי ההסקה של ארמסטרונג על התלות הפונקציונלית שהוגדרה לקבוצת F(S), ניתן להשיג תלות תפקודיות חדשות, כפי שכבר אמרנו והוכחנו קודם. וזה מעיד, היחס F(S) יספק אוטומטית את ההגבלות של התלות הפונקציונלית הללו, כפי שניתן לראות מהצורה המורחבת של כללי ההסקה של ארמסטרונג. זכור את הצורה הכללית של כללי ההסקה המורחבים הללו: כלל מסקנות 1. inv r(S); כלל מסקנות 2. inv r(S) ⇒ inv<X ∪ Z → Y> r(S); כלל מסקנות 3. inv r(S) & inv ∪ W → Z> r(S) ⇒ inv<X ∪ W→Z>; אם נחזור להגיון שלנו, הבה נמלא את הסט F(S) בתלותיות חדשות שנגזרות ממנו באמצעות הכללים של ארמסטרונג. אנו ניישם הליך חידוש זה עד שלא נקבל עוד תלות פונקציונלית חדשה. כתוצאה מבנייה זו, נקבל קבוצה חדשה של תלות פונקציונלית, הנקראת סגירת מעגל קבע F(S) ומסומן F+(S). אכן, שם כזה הוא די הגיוני, כי אנחנו באופן אישי, באמצעות בניה ארוכה, "סגרנו" על עצמו את מערך התלות הפונקציונלית הקיימת, והוספנו (ומכאן ה"+") את כל התלות הפונקציונלית החדשה הנובעת מהקיימות. יש לציין שתהליך זה של בניית סגירה הוא סופי, מכיוון שסכימת היחסים עצמה, שעליה מתבצעות כל הקונסטרוקציות הללו, היא סופית. מובן מאליו שסגירה היא סופרסט של הסט הנסגר (אכן, הוא גדול יותר!) ואינו משתנה בשום צורה כאשר הוא נסגר שוב. אם נכתוב את מה שנאמר זה עתה בצורה נוסחתית, נקבל: F(S) ⊆ F+(S), [F+(S)]+=F+(S); יתרה מכך, מהאמת המוכחת (כלומר, חוקיות, לגיטימיות) של כללי ההסקה של ארמסטרונג והגדרת הסגירה, נובע שכל קשר המקיים את האילוצים של מערכת נתונה של תלות פונקציונלית יעמוד באילוץ של התלות השייכת לסגר. . X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ inv r(S)]; אז, משפט השלמות של ארמסטרונג למערכת כללי ההסקה קובע כי השלכה חיצונית יכולה להיות מוחלפת באופן לגיטימי ומוצדק בהחלטות. (לא נשקול את ההוכחה של משפט זה, מכיוון שתהליך ההוכחה עצמו אינו כה חשוב במהלך ההרצאות המסוים שלנו.) הרצאה מספר 10. צורות רגילות 1. המשמעות של נורמליזציה של סכימת מסד נתונים המושג שנשקול בסעיף זה קשור למושג התלות הפונקציונלית, כלומר המשמעות של נרמול סכימות מסד נתונים קשורה קשר בל יינתק עם מושג ההגבלות המוטלות על ידי מערכת של תלות פונקציונלית, ונובעת במידה רבה ממושג זה. נקודת המוצא של כל עיצוב מסד נתונים היא לייצג את התחום כקשר אחד או יותר, ובכל שלב עיצוב מופקת קבוצה כלשהי של סכימות קשר שיש לה מאפיינים "משופרים". לפיכך, תהליך העיצוב הוא תהליך של נורמליזציה של דפוסי יחסים, כאשר לכל צורה נורמלית עוקבת יש תכונות שהן במובן מסוים טובות יותר מהקודמת. לכל צורה נורמלית יש קבוצה מסוימת של אילוצים, ויחס הוא בצורה נורמלית מסוימת אם הוא עונה על קבוצת האילוצים שלו. דוגמה לכך היא הגבלה של הצורה הנורמלית הראשונה - הערכים של כל תכונות היחס הם אטומיים. בתורת מסדי הנתונים ההתייחסותיים, בדרך כלל מובחן הרצף הבא של צורות נורמליות: 1) צורה נורמלית ראשונה (1 NF); 2) צורה נורמלית שנייה (2 NF); 3) צורה נורמלית שלישית (3 NF); 4) צורה נורמלית של בויס-קודד (BCNF); 5) צורה נורמלית רביעית (4 NF); 6) צורה נורמלית חמישית, או צורה נורמלית עם השלכה-מצטרפת (5 NF או PJ/NF). (קורס הרצאות זה כולל דיון מפורט בארבע הצורות הנורמליות הראשונות של יחסים בסיסיים, ולכן לא ננתח את הצורות הנורמליות הרביעית והחמישית בפירוט). המאפיינים העיקריים של צורות רגילות הם כדלקמן: 1) כל צורה נורמלית הבאה טובה במובן מסוים מהצורה הרגילה הקודמת; 2) כאשר עוברים לצורה הנורמלית הבאה, המאפיינים של הצורות הנורמליות הקודמות נשמרות. תהליך התכנון מבוסס על שיטת הנורמליזציה, כלומר פירוק של קשר שנמצא בצורה הנורמלית הקודמת לשני קשרים או יותר העונים על הדרישות של הצורה הנורמלית הבאה (נתקל בכך כאשר אנחנו בעצמנו צריכים לנרמל את זה כאשר אנו עוברים על החומר). או מערכת יחסים בסיסית אחרת). כפי שהוזכר בסעיף על יצירת קשרים בסיסיים, קבוצות התלות הפונקציונליות הנתונות מטילות הגבלות מתאימות על הסכמות של קשרים בסיסיים. הגבלות אלו מיושמות בדרך כלל בשתי דרכים: 1) באופן הצהרתי, כלומר, על ידי הכרזה על סוגים שונים של מפתחות ראשוניים, מועמדים ומפתחות זרים ביחס הבסיס (זו השיטה הנפוצה ביותר); 2) מבחינה פרוצדורלית, כלומר, כתיבת קוד תוכנית (באמצעות מה שנקרא טריגרים שהוזכרו לעיל). בעזרת לוגיקה פשוטה ניתן להבין מה הטעם בנרמול סכימות מסד נתונים. לנרמל מסדי נתונים או להביא מסדי נתונים לצורה נורמלית פירושו להגדיר סכימות כאלה של יחסים בסיסיים על מנת למזער את הצורך בכתיבת קוד תוכנית, להגביר את ביצועי מסד הנתונים ולהקל על תחזוקה של שלמות הנתונים על ידי מצב ושלמות התייחסות. כלומר, להפוך את הקוד והעבודה איתו לפשוטה ונוחה ככל האפשר למפתחים ולמשתמשים. על מנת להדגים חזותית בהשוואה את פעולתו של מסד נתונים לא מנורמל ומנורמל, שקול את הדוגמה הבאה. תן לנו יחס בסיס המכיל מידע על תוצאות מפגש הבחינה. כבר שקלנו מאגר כזה בעבר. לפיכך, 1 האפשרות סכימות של מסד נתונים. מושב (מספר ספר רישום, שם מלא, נושא, כיתה) ביחס זה, כפי שניתן לראות מתמונת סכימת יחס הבסיס, מוגדר מפתח ראשי מורכב: מפתח ראשי (מספר ספר כיתה, נושא); גם בהקשר זה, נקבעה מערכת של תלות פונקציונלית: {מספר ספר חשבון} ← {שם משפחה, שם פרטי, פטרונימי}; הנה תצוגה טבלה של קטע קטן של מסד נתונים עם סכימת יחס זו. כבר השתמשנו בפרגמנט זה בבחינת המגבלות של תלות פונקציונלית, כך שיהיה לנו די קל להבין את הנושא הזה באמצעות הדוגמה שלו.
כאן, על מנת לשמור על שלמות הנתונים לפי מדינה, כלומר, למלא את ההגבלה של מערכת התלות הפונקציונלית {מספר כיתה} ← {שם משפחה, שם פרטי, פטרונימי} בעת שינוי, למשל, שם המשפחה, זה הכרחי לעיין בכל הטפולים של הקשר הבסיסי הזה ולהזין ברצף את השינויים הדרושים. אולם מאחר ומדובר בתהליך מסורבל וגוזל זמן רב (במיוחד אם עסקינן במאגר מידע של מוסד חינוכי גדול), הגיעו מפתחי מערכות ניהול מסדי נתונים למסקנה שתהליך זה צריך להיות אוטומטי, כלומר , נעשה אוטומטי. כעת, השליטה על הגשמת התלות הפונקציונלית הזו (וכל תלות אחרת) יכולה להתארגן באופן אוטומטי באמצעות ההכרזה הנכונה של מפתחות שונים ביחסי הבסיס ומה שנקרא פירוק (כלומר, פירוק משהו למספר חלקים עצמאיים) של זה. יַחַס. אז, בואו נחלק את סכימת הקשר הקיימת שלנו ב"מפגש" לשתי סכמות: סכימת "סטודנטים", המכילה רק מידע על תלמידי מוסד חינוכי נתון, וסכימת "מפגש", המכילה מידע על המפגש האחרון שעבר. ואז נכריז על המפתחות בצורה כזו שנוכל לקבל בקלות כל מידע נחוץ. בואו נראה איך ייראו תוכניות היחסים החדשות האלה עם המפתחות שלהן. אפשרות 2 סכימות של מסד נתונים. תלמידים (מספר ספר רישום, שם מלא), מפתח ראשי (מספר ספר ציונים). מושב (מספר ספר שיא, נושא, כיתה), מפתח ראשי (מספר ספר ציונים, נושא), מפתח זר (מספר ספר ציונים) הפניות תלמידים (מספר ספר ציונים). מה יש לנו עכשיו? ביחס ל"סטודנטים", המפתח הראשי "מספר ספר ציונים" קובע פונקציונלית את שלוש התכונות האחרות: "שם משפחה", "שם פרטי" ו"פטרונימי". ובהתייחס ל"Session", המפתח הראשי המרוכב "מספר ציונים, נושא" גם הוא באופן חד משמעי, כלומר, ממש מגדיר באופן פונקציונלי את התכונה האחרונה של סכימת יחסים זו - "ניקוד". והקשר בין שני היחסים הללו נוצר: הוא מתבצע באמצעות המפתח החיצוני של יחסי "הישיבה" "ספר ציונים לא", המתייחס לתכונה של אותו שם ביחסי "סטודנטים" וכאשר מתבקש, מספק את כל המידע הדרוש. כעת נראה כיצד ייראו היחסים המיוצגים על ידי טבלאות התואמות לאפשרות השנייה של הגדרת סכימות מסד הנתונים המתאימות.
לפיכך, אנו רואים כי מטרת הנורמליזציה מבחינת ההגבלות המוטלות על ידי תלות פונקציונלית היא הצורך להטיל את התלות הפונקציונלית הנדרשת על כל מסד נתונים באמצעות הצהרות על סוגים שונים של מפתחות ראשוניים, מועמדים וזרים של יחסי הבסיס. 2. הצורה הרגילה הראשונה (1NF) בשלבים המוקדמים של עיצוב ופיתוח מסדי נתונים של סכימות ניהול מסדי נתונים, נעשה שימוש בתכונות פשוטות וחד משמעיות כיחידות הקוד היצרניות והרציונליות ביותר. אחר כך הם השתמשו יחד עם תכונות פשוטות ומורכבות, כמו גם יחד עם תכונות חד-ערך ורב-ערכיות. הבה נסביר את המשמעות של כל אחד מהמושגים הללו. תכונות מורכבות, בניגוד לפשוטים, הן תכונות המורכבות מכמה תכונות פשוטות. תכונות רב-ערכים, בניגוד לאלו בעלי ערך יחיד, הן תכונות המייצגות מספר ערכים. להלן דוגמאות לתכונות פשוטות, מורכבות, חד-ערך ורב-ערכיות. שקול את הטבלה הבאה המייצגת את הקשר:
כאן התכונה "טלפון" היא פשוטה, חד משמעית, והתכונה "כתובת" היא פשוטה, אך רבת ערכים. עכשיו שקול טבלה נוספת, עם תכונות שונות:
ביחס זה, המיוצג על ידי הטבלה, התכונה "טלפונים" היא פשוטה אך רבת ערכים, והתכונה "כתובות" היא מורכבת וגם רבת ערכים. באופן כללי, שילובים שונים של תכונות פשוטות או מורכבות אפשריים. במקרים שונים, טבלאות המייצגות קשרים עשויות להיראות כך באופן כללי:
כאשר מנרמל סכימות יחסים בסיסיות, מתכנתים יכולים להשתמש באחד מארבעת הסוגים הנפוצים ביותר של צורות נורמליות: צורה רגילה ראשונה (1NF), צורה נורמלית שנייה (2NF), צורה נורמלית שלישית (3NF), או צורה נורמלית של Boyce-Codd (NFBC) . לשם הבהרה: הקיצור NF הוא קיצור של הביטוי האנגלי Normal Form. פורמלית, בנוסף לאמור לעיל, ישנם סוגים אחרים של צורות רגילות, אך האמור לעיל הוא אחד הפופולריים ביותר. נכון לעכשיו, מפתחי מסדי נתונים מנסים להימנע מתכונות מורכבות ורב-ערכיות כדי לא לסבך את כתיבת הקוד, לא להעמיס על המבנה שלו ולא לבלבל משתמשים. משיקולים אלה, ההגדרה של הצורה הנורמלית הראשונה נובעת באופן הגיוני. הַגדָרָה. כל יחס בסיס נמצא ב צורה רגילה ראשונה אם ורק אם הסכימה של יחס זה מכילה רק תכונות פשוטות ויחידות ערך בלבד, ובהכרח עם אותה סמנטיקה. כדי להסביר חזותית את ההבדלים בין יחסים מנורמלים ללא מנורמלים, שקול דוגמה. תן, יש יחס לא מנורמל, עם הסכמה הבאה. לפיכך, 1 האפשרות סכימות יחסים עם מפתח ראשי פשוט שהוגדר עליהן: עובדים (מספר כוח אדם, שם משפחה, שם פרטי, פטרונימי, קוד תפקיד, טלפונים, תאריך קבלה או פיטורים); מפתח ראשי (מספר כוח אדם); הבה נרשום אילו שגיאות יש בסכימת קשרים זו, כלומר, נמנה את הסימנים ההופכים את הסכימה הזו ללא נורמליזציה: 1) התכונה "שם משפחה פטרונימי" מורכבת, כלומר מורכבת מאלמנטים הטרוגניים; 2) התכונה "טלפונים" היא מרובה ערכים, כלומר הערך שלה הוא קבוצת ערכים; 3) לתכונה "תאריך קבלה או פיטורים" אין סמנטיקה חד משמעית, כלומר במקרה האחרון לא ברור איזה תאריך הוזן. אם, למשל, תוכנס תכונה נוספת כדי להגדיר בצורה מדוייקת יותר את המשמעות של תאריך, אז הערך של תכונה זו יהיה ברור מבחינה סמנטית, אך עם זאת נותר לאחסן רק אחד מהתאריכים שצוינו עבור כל עובד. מה צריך לעשות כדי להביא את היחס הזה לצורה נורמלית? ראשית, יש צורך לפצל תכונות מורכבות לפשוטות כדי להוציא את התכונות המרוכבות הללו, כמו גם תכונות עם סמנטיקה מורכבת. ושנית, יש צורך לפרק את הקשר הזה, כלומר, יש צורך לפרק אותו למספר יחסים עצמאיים חדשים כדי להוציא תכונות רב-ערכים. לפיכך, בהתחשב בכל האמור לעיל, לאחר צמצום היחס "עובדים" לצורה הרגילה הראשונה או 1NF על ידי פירוקו, נקבל מערכת של היחסים הבאים עם מפתחות ראשיים וזרים המוגדרים עליהם. לפיכך, 2 האפשרות יחסים: עובדים (מספר כוח אדם, שם משפחה, שם פרטי, פטרונימי, קוד תפקיד, תאריך קבלה, תאריך פיטורים); מפתח ראשי (מספר כוח אדם); טלפונים (מספר כוח אדם, טלפון); מפתח ראשי (מספר כוח אדם, טלפון); אסמכתאות מפתח זר (מספר כוח אדם) עובדים (מספר כוח אדם); אז מה אנחנו רואים? התכונה המורכבת "שם משפחה שם פרטי פטרונימי" כבר אינה בקשר שלנו, במקום זה יש שלוש תכונות פשוטות "שם משפחה", "שם פרטי" ו"פטרונימי", ולכן הסיבה הזו ל"חריגות" של הקשר לא נכללה . בנוסף, במקום התכונה עם סמנטיקה לא ברורה "תאריך עבודה או פיטורים", יש לנו כעת שתי תכונות "תאריך קבלה" ו"תאריך פיטורים", שלכל אחת מהן סמנטיקה חד משמעית. לכן, הסיבה השנייה לכך שמערכת היחסים שלנו "עובדים" אינה תקינה, נמחקת גם היא בבטחה. ולבסוף, הסיבה האחרונה לכך שיחסי "עובדים" לא נורמלו היא הנוכחות של התכונה מרובת הערכים "טלפונים". כדי להיפטר מהתכונה הזו, היה צורך לפרק את מערכת היחסים כולה. כתוצאה מפירוק זה, התכונה "טלפונים" לא נכללה מהיחס המקורי "עובדים" באופן כללי, אך נוצר קשר שני - "טלפונים", שבו ישנן שתי תכונות: "מספר כוח אדם של עובד" ו"טלפון ", כלומר כל התכונות - שוב פשוט, מתקיים התנאי של השתייכות לצורה הנורמלית הראשונה. תכונות אלה "מספר עובד" ו"טלפון" יוצרות מפתח ראשי מורכב של מערכת היחסים "טלפונים", והתכונה "מספר עובד", בתורה, היא מפתח זר המתייחס לתכונה בעלת אותו שם ב"עובדים". "קשר, כלומר ביחס "טלפונים" של המפתח הראשי "מספר כוח אדם" הוא גם מפתח זר המתייחס למפתח הראשי של מערכת היחסים "עובדים". לפיכך, ניתן קישור בין שני מערכות היחסים. באמצעות קישור זה, אתה יכול להציג את כל רשימת הטלפונים שלו לפי מספר כוח אדם של כל עובד בלי הרבה מאמץ וזמן מבלי להזדקק לשימוש בתכונות מורכבות. שימו לב שאם היו תלות פונקציונלית ביחס למערכת, לאחר כל הטרנספורמציות לעיל, הנורמליזציה לא תושלם. עם זאת, בדוגמה הספציפית הזו, אין אילוצי תלות פונקציונליים, ולכן אין צורך בנורמליזציה נוספת של קשר זה. 3. צורה נורמלית שנייה (2NF) דרישות חזקות יותר מוטלות על יחסים על ידי הצורה הרגילה השנייה, או 2NF. הסיבה לכך היא שההגדרה של צורת היחסים הנורמלית השנייה מרמזת, בניגוד לצורה הנורמלית הראשונה, על קיומה של מערכת הגבלות על תלות פונקציונלית. הַגדָרָה. יחס הבסיס נמצא ב צורה רגילה שניה ביחס לקבוצה נתונה של תלות פונקציונלית אם ורק אם היא בצורה נורמלית ראשונה, ובנוסף, כל תכונה שאינה מפתח תלויה באופן תפקודי לחלוטין בכל מפתח. בהגדרה זו תכונה לא מפתח הוא כל תכונת יחס שאינה כלולה במפתח ראשי או מועמד כלשהו של היחס. תלות תפקודית מלאה במפתח אינה מרמזת על תלות תפקודית באף חלק של מפתח זה. לפיכך, כעת, בעת נורמליזציה של יחס, עלינו לעקוב גם אחר מילוי התנאים לכך שהיחס יהיה בצורה הרגילה הראשונה, כלומר לוודא שהתכונות שלו פשוטות וחד משמעיות, וכן את קיום התנאי השני בנוגע ההגבלות של תלות תפקודית. ברור שיחסים עם מפתחות פשוטים (ראשוני ומועמד) הם בהחלט בצורה נורמלית שניה. ואכן, במקרה זה, תלות בחלק מהמפתח פשוט לא נראית אפשרית, כי למפתח פשוט אין חלקים נפרדים. כעת, כמו בקטע של הנושא הקודם, שקול דוגמה של סכימת יחסים לא מנורמלת ותהליך הנורמליזציה עצמו. לפיכך, 1 האפשרות סכימות יחסים: קהלים (בניין מס', אודיטוריום מס'., שטח מ"ר מ, מס' מפקד שירות של החיל); מפתח ראשי (מספר קורפוס, מספר קהל); בנוסף, המערכת הבאה של תלות תפקודית מוגדרת: {מס' החיל} ← {מס' מפקד השירות של החיל}; מה אנחנו רואים? מתקיימים כל התנאים לכך שהיחס הזה "קהל" יישאר בצורה הרגילה הראשונה מתקיימים, כי כל תכונה בודדת של היחס הזה היא חד משמעית ופשוטה. אבל התנאי שכל אלמנט שאינו מפתח חייב להיות תלוי פונקציונלי לחלוטין במפתח אינו מתקיים. למה? כן, מכיוון שהתכונה "מספר כוח אדם של מפקד החיל" תלויה מבחינה תפקודית לא במפתח המורכב "מספר חיל, מספר קהל", אלא בחלק מהמפתח הזה, כלומר בתכונת "מספר חיל". אכן, הרי מספר החיל הוא זה שקובע לחלוטין איזה מפקד משולב לו, ומנגד, מספר השירות של מפקד החיל אינו יכול להיות תלוי במספר אודיטוריום כלשהו. לפיכך, המשימה העיקרית של הנורמליזציה שלנו הופכת למשימה להבטיח שהמפתחות יחולקו באופן שבו, במיוחד, התכונה "לא. כדי להשיג זאת, נצטרך ליישם שוב, כמו בפסקה הקודמת, את פירוק היחס. אז, מערכת היחסים הבאה, כלומר 2 האפשרות מערכת היחסים "קהל" התקבלה זה עתה ממערכת היחסים המקורית על ידי פירוקו למספר מערכות יחסים עצמאיות חדשות: חיל (תיק מס., מספר מפקד כוח האדם של החיל); מפתח ראשי (מספר מקרה); קהלים (בניין מס', אודיטוריום מס'., שטח מ"ר M); מפתח ראשי (מספר קורפוס, מספר קהל); מפתח זר (מספר תיק) אסמכתאות תיקים (מספר תיק); מה אנחנו רואים עכשיו? ביחס לתכונה הלא-מפתחת של "חיל" "מספר כוח האדם של מפקד החיל" תלוי באופן מלא במפתח הראשי "מספר החיל". כאן מתקיים במלואו התנאי למציאת היחס בצורה הנורמלית השנייה. כעת נעבור לשיקול היחס השני – "קהל". ביחס ל"קהל", תכונת המפתח הראשי "Case #" היא גם מפתח זר המתייחס למפתח הראשי של הקשר "Case". בהקשר זה, התכונה הלא-מפתחית "שטח מ"ר" תלויה לחלוטין במפתח הראשוני המורכב כולו "בניין #, אודיטוריום #" ואינה, אפילו לא יכולה להיות תלויה באף אחד מחלקיו. לפיכך, על ידי פירוק היחס המקורי, הגענו למסקנה שכל התנאים מהגדרת הצורה הנורמלית השנייה מתקיימים במלואם. בדוגמה זו, כל דרישות התלות הפונקציונלית מוטלות על ידי הצהרת מפתחות ראשיים (אין מפתחות מועמדים כאן) ומפתחות זרים. לכן, אין צורך בנורמליזציה נוספת. 4. צורה רגילה שלישית (3NF) הצורה הנורמלית הבאה שנסתכל עליה היא הצורה הנורמלית השלישית (או 3NF). בניגוד לצורה הנורמלית הראשונה, כמו גם מהצורה הנורמלית השנייה, השלישית מרמזת על הקצאה של מערכת של תלות פונקציונלית יחד עם היחס. הבה ננסח אילו תכונות חייבות להיות ליחס כדי שיצטמצם לצורה נורמלית שלישית. הַגדָרָה. יחס הבסיס נמצא ב צורה נורמלית שלישית ביחס לקבוצה נתונה של תלות פונקציונלית אם ורק אם היא בצורה נורמלית שניה וכל תכונה שאינה מפתח תלויה באופן תפקודי מלא רק במפתחות. לפיכך, הדרישות של הצורה הנורמלית השלישית חזקות יותר מהדרישות של הצורה הנורמלית הראשונה והשנייה, אפילו בשילוב. למעשה, בצורה נורמלית שלישית, כל תכונה שאינה מפתח תלויה במפתח, ובמפתח כולו, ולא בשום דבר אחר מלבד המפתח. הבה נמחיש את התהליך של הבאת יחס לא מנורמל לצורה הנורמלית השלישית. לשם כך, שקול דוגמה: יחס שאינו בצורה נורמלית שלישית. לפיכך, 1 האפשרות תוכניות של מערכת היחסים "עובדים": עובדים (מספר כוח אדם, שם משפחה, שם פרטי, פטרונימי, קוד תפקיד, שכר); מפתח ראשי (מספר כוח אדם); בנוסף, מערכת התלות הפונקציונלית הבאה מוגדרת מעל מערכת היחסים "עובדים" זו: {קוד עמדה} ← {משכורת}; ואכן, ככלל, גובה השכר, כלומר גובה השכר, תלוי ישירות בתפקיד, ולכן, בקוד שלו במאגר המתאים. לכן הקשר הזה "עובדים" אינו בצורת רגילה שלישית, כי מסתבר שהתכונה הלא-מפתחית "שכר" תלויה פונקציונלית לחלוטין בתכונה "קוד עמדה", אם כי תכונה זו אינה מפתח. באופן מוזר, כל קשר מצטמצם לצורה הנורמלית השלישית בדיוק באותו אופן כמו לשתי הצורות שלפני זו, כלומר על ידי פירוק. לאחר פירוק הקשר "עובדים", אנו מקבלים את המערכת הבאה של יחסים עצמאיים חדשים: לפיכך, 2 האפשרות תוכניות של מערכת היחסים "עובדים": עמדות (קוד מיקום, שכר); מפתח ראשי (קוד מיקום); עובדים (מספר כוח אדם, שם משפחה, שם פרטי, פטרונימי, קוד עמדה); מפתח ראשי (קוד מיקום); מפתח זר (קוד מיקום) הפניות עמדות (קוד מיקום); כעת, כפי שאנו יכולים לראות, ביחס ל"עמדה", התכונה הלא-מפתחית "שכר" תלויה פונקציונלית לחלוטין במפתח הראשי הפשוט "קוד עמדה" ורק במפתח זה. שים לב שביחס ל"עובדים" כל ארבעת התכונות הלא-מפתחות "שם משפחה", "שם פרטי", "פטרונימי" ו"קוד תפקיד" תלויות באופן תפקודי לחלוטין במפתח הראשי הפשוט "מספר תעסוקה". מבחינה זו, התכונה "מזהה מיקום" היא מפתח זר המתייחס למפתח הראשי של היחסים "תפקידים". בדוגמה זו, כל הדרישות מוטלות על ידי הכרזה על מפתחות ראשיים וזרים פשוטים, כך שאין צורך בנורמליזציה נוספת. מעניין ושימושי לדעת שבפועל מתמצים בדרך כלל בהבאת מאגרי מידע לצורה הנורמלית השלישית. יחד עם זאת, ייתכן שלא ייכפו כמה תלות תפקודיות של תכונות מפתח בתכונות אחרות של אותו קשר. תמיכה בתלות פונקציונלית לא סטנדרטית כזו מיושמת באמצעות הטריגרים שהוזכרו לעיל (כלומר, מבחינה פרוצדורלית, על ידי כתיבת קוד התוכנית המתאים). יתר על כן, טריגרים חייבים לפעול עם tuples של יחס זה. 5. בויס-קודד צורה רגילה (NFBC) הצורה הנורמלית של בויס-קוד באה ב"מורכבות" רק אחרי הצורה הנורמלית השלישית. לכן, הצורה הנורמלית של בויס-קוד נקראת לפעמים גם בפשטות צורה נורמלית שלישית חזקה (או מחוזק 3 NF). למה היא מחוזקת? אנו מנסחים את ההגדרה של הצורה הנורמלית של בויס-קודד: הַגדָרָה. יחס הבסיס נמצא ב בויס צורה נורמלית - קוד אם ורק אם היא בצורה נורמלית שלישית, ולא רק שכל תכונה שאינה מפתח תלויה באופן פונקציונלי לחלוטין בכל מפתח, אלא כל תכונת מפתח חייבת להיות תלויה תפקודית מלאה בכל מפתח. לפיכך, הדרישה שתכונות שאינן מפתח תלויות למעשה במפתח כולו ולא בשום דבר מלבד המפתח חלה גם על תכונות מפתח. ביחס שהוא בצורה נורמלית של Boyce-Codd, כל התלות הפונקציונלית בתוך הקשר נכפות על ידי הצהרת המפתחות. עם זאת, כאשר מצמצמים את יחסי מסד הנתונים לצורת Boyce-Codd, יתכנו מצבים שבהם תלות בין התכונות של יחסים שונים מתבררות כלא תלויות פונקציונליות כפויות. תמיכה בתלות תפקודית כזו עם טריגרים הפועלים על tuples של יחסים שונים היא קשה יותר מאשר במקרה של צורה נורמלית שלישית, כאשר טריגרים פועלים tuples של יחס יחיד. בין היתר, הפרקטיקה של עיצוב מערכות ניהול מסדי נתונים הראתה שלא תמיד ניתן להביא את היחס הבסיסי לצורה הרגילה של בויס-קוד. הסיבה לאנומליות שצוינו היא שהדרישות של הצורה הנורמלית השנייה ושל הצורה הנורמלית השלישית לא דרשו תלות תפקודית מינימלית במפתח הראשי של תכונות שהן מרכיבים של מפתחות אפשריים אחרים. בעיה זו נפתרת על ידי הצורה הנורמלית, הנקראת היסטורית הצורה הנורמלית של Boyce-Codd ושמהווה חידוד של הצורה הנורמלית השלישית במקרה של נוכחות של מספר מפתחות אפשריים חופפים. באופן כללי, נורמליזציה של סכימת מסד הנתונים הופכת את עדכוני מסד הנתונים ליעילים יותר עבור מערכת ניהול מסד הנתונים, מכיוון שהיא מפחיתה את מספר הבדיקות והגיבויים השומרים על שלמות מסד הנתונים. כאשר מעצבים מסד נתונים יחסי, כמעט תמיד משיגים את הצורה הרגילה השנייה של כל הקשרים במסד הנתונים. במסדי נתונים שמתעדכנים לעתים קרובות, הם בדרך כלל מנסים לספק את הצורה השלישית הרגילה של הקשר. הצורה הרגילה של בויס-קוד זוכה להרבה פחות תשומת לב מכיוון שבפועל, מצבים שבהם לקשר יש כמה מפתחות מועמדים חופפים מורכבים הם נדירים. כל האמור לעיל הופך את הצורה הרגילה של Boyce-Codd לא נוחה במיוחד לשימוש בעת פיתוח קוד תוכנית, לכן, כפי שהוזכר קודם לכן, בפועל, מפתחים בדרך כלל מגבילים את עצמם להבאת מסדי הנתונים שלהם לצורה הרגילה השלישית. עם זאת, יש לו גם תכונה די מוזרה משלו. הנקודה היא שמצבים שבהם הקשר הוא בצורה נורמלית שלישית אך לא בצורה נורמלית בויס-קודד הם נדירים ביותר בפועל, כלומר, לאחר הפחתה לצורה נורמלית שלישית, בדרך כלל כל התלות התפקודית מוטלת על ידי הצהרות של ראשוני, מועמד, ו מפתחות זרים, כך שאין צורך בטריגרים לתמיכה בתלות פונקציונלית. עם זאת, הצורך בטריגרים נותר כדי לתמוך באילוצי שלמות שאינם מקושרים על ידי תלות פונקציונלית. 6. קינון של צורות רגילות מה המשמעות של קינון של צורות רגילות? קינון של צורות רגילות - זהו היחס בין המושגים של צורות מוחלשות ומחוזקות ביחס זה לזה. הקינון של צורות נורמליות נובע לחלוטין מההגדרות שלהם. בואו נדמיין תרשים הממחיש את יחסי הקינון של הצורות הנורמליות המוכרות לנו:
הבה נסביר את המושגים של צורות נורמליות מוחלשות ומחוזקות זו בזו תוך שימוש בדוגמאות ספציפיות. הצורה הנורמלית הראשונה נחלשת ביחס לצורה הנורמלית השנייה (וגם ביחס לכל שאר הצורות הנורמליות). ואכן, כשנזכרים בהגדרות של כל הצורות הנורמליות שעברנו, ניתן לראות שהדרישות של כל צורה נורמלית כללו את הדרישה להשתייך לצורה הנורמלית הראשונה (הרי היא נכללה בכל הגדרה שלאחר מכן). הצורה הנורמלית השנייה חזקה יותר מהצורה הרגילה הראשונה, אך חלשה מהצורה הנורמלית השלישית ומהצורה הנורמלית של בויס-קודד. למעשה, השתייכות לצורה הנורמלית השנייה נכללת בהגדרה של השלישית, והצורה השנייה עצמה, בתורה, כוללת את הצורה הנורמלית הראשונה. הצורה הנורמלית של בויס-קוד מתחזקת לא רק ביחס לצורה הנורמלית השלישית, אלא גם ביחס לכל האחרות שקדמו לה. והצורה הנורמלית השלישית, בתורה, נחלשת רק ביחס לצורה הנורמלית של בויס-קודד. הרצאה מס' 11. עיצוב סכימות מסד נתונים האמצעי הנפוץ ביותר להפשטת סכימות מסד נתונים בעת תכנון ברמה הלוגית הוא מה שנקרא מודל ישות-יחסים. זה נקרא לפעמים גם דגם ER, כאשר ER הוא קיצור של הביטוי האנגלי Entity - Relationship, שמתורגם מילולית כ"ישות - קשר". המרכיבים של מודלים כאלה הם מחלקות ישויות, התכונות והיחסים שלהן. ניתן הסברים והגדרות של כל אחד מהמרכיבים הללו. כיתת ישות הוא כמו מחלקה חסרת מתודה של אובייקטים במובן של תכנות מונחה עצמים. בעת מעבר לשכבה הפיזית, מחלקות ישות מומרות לקשרי מסד נתונים יחסיים בסיסיים עבור מערכות ניהול מסד נתונים ספציפיות. להם, כמו ליחסים הבסיסיים עצמם, יש תכונות משלהם. הבה ניתן הגדרה מדויקת וקפדנית יותר של האובייקטים שניתנו זה עתה. מעמד נקרא תיאור בשם של אוסף של אובייקטים עם תכונות, פעולות, יחסים וסמנטיקה משותפים. מבחינה גרפית, מחלקה מתוארת בדרך כלל כמלבן. לכל מחלקה חייב להיות שם (מחרוזת טקסט) המבדיל אותה באופן ייחודי מכל המחלקות האחרות. תכונת כיתה הוא מאפיין בעל שם של מחלקה המתאר את קבוצת הערכים שמופעים של מאפיין זה יכולים לקחת. למחלקה יכולה להיות כל מספר של תכונות (בפרט, לא יכולות להיות לה תכונות). תכונה המבוטאת על ידי תכונה היא תכונה של הישות המודלית המשותף לכל האובייקטים של המחלקה הנתונה. אז תכונה היא הפשטה של מצבו של אובייקט. כל תכונה של כל אובייקט מחלקה חייבת להיות בעלת ערך כלשהו. מה שנקרא קשרים מיושמים באמצעות הצהרת מפתחות זרים (כבר פגשנו תופעות דומות בעבר), כלומר, ביחס, מפתחות זרים מוכרזים המתייחסים למפתחות ראשוניים או מועמדים של קשר אחר כלשהו. ודרך זה, מספר יחסים בסיסיים עצמאיים שונים "מקושרים" למערכת אחת הנקראת מסד נתונים. יתרה מכך, הדיאגרמה המהווה את הבסיס הגרפי של מודל הישות-יחסי מתואר באמצעות שפת הדוגמנות המאוחדת UML. הרבה מאוד ספרים מוקדשים לשפת הדוגמנות מונחה עצמים UML (או Unified Modeling Language), שרבים מהם תורגמו לרוסית (וחלקם נכתבו על ידי סופרים רוסים). באופן כללי, UML מאפשרת ליצור מודלים מסוגים שונים של מערכות: תוכנה בלבד, חומרה בלבד, תוכנה-חומרה, מעורבת, כולל פעילויות אנושיות באופן מפורש וכו'. אבל, בין היתר, כפי שכבר הזכרנו, שפת UML משמשת באופן פעיל לעיצוב מסדי נתונים יחסיים. לשם כך נעשה שימוש בחלק קטן מהשפה (דיאגרמות מחלקות), וגם אז לא במלואו. מנקודת מבט של עיצוב מסד נתונים יחסי, יכולות הדוגמנות אינן שונות מדי מאלו של דיאגרמות ER. כמו כן, רצינו להראות שבהקשר של עיצוב מסד נתונים יחסי, שיטות עיצוב מבני המבוססות על שימוש בדיאגרמות ER ושיטות מונחה עצמים המבוססות על שימוש בשפת UML נבדלות בעיקר רק בטרמינולוגיה. מודל ה-ER פשוט יותר מבחינה רעיונית מ-UML, יש לו פחות מושגים, מונחים ואפשרויות יישום. וזה מובן, שכן גרסאות שונות של מודלים של ER פותחו במיוחד כדי לתמוך בתכנון מסדי נתונים יחסיים, ומודלי ER אינם מכילים כמעט תכונות החורגות מהצרכים האמיתיים של מעצב מסדי נתונים יחסיים. ה-UML שייך לעולם האובייקטים. העולם הזה הרבה יותר מסובך (אם תרצה, יותר לא מובן, יותר מבלבל) מהעולם היחסי. מכיוון שניתן להשתמש ב-UML למידול מונחה עצמים מאוחד של כל דבר, השפה מכילה שפע של מושגים, מונחים ומקרי שימוש שהם מיותרים מנקודת מבט של עיצוב מסד נתונים יחסי. אם נחלץ מהמנגנון הכללי של דיאגרמות מחלקות את מה שבאמת נדרש לתכנון של מסדי נתונים יחסיים, אז נקבל בדיוק דיאגרמות ER עם סימון ומינוח שונה. זה מוזר שכאשר יוצרים שמות מחלקות ב-UML, מותר שילוב שרירותי של אותיות, מספרים ואפילו סימני פיסוק. עם זאת, בפועל, מומלץ להשתמש בשמות תואר ובשמות עצם קצרים ומשמעותיים כשמות כיתות, שכל אחד מהם מתחיל באות גדולה. (נשקול את הרעיון של דיאגרמה ביתר פירוט בפסקה הבאה של ההרצאה שלנו.) 1. סוגים וריבויים שונים של קשרים הקשר בין מערכות היחסים בתכנון של סכימות מסד נתונים מתואר כקווים המחברים בין מחלקות ישויות. יתרה מכך, כל אחד מקצוות החיבור יכול (ובאופן כללי צריך) להיות מאופיין בשם (כלומר, סוג החיבור) וריבוי התפקיד של המחלקה בחיבור. הבה נבחן ביתר פירוט את מושגי הריבוי וסוגי הקשרים. ריבוי (ריבוי) הוא מאפיין המציין כמה תכונות של מחלקת ישות עם תפקיד נתון יכולות או אמורות להשתתף בכל מופע של מערכת יחסים כלשהי. הדרך הנפוצה ביותר להגדיר את הקרדינליות של תפקיד מערכת יחסים היא לציין ישירות מספר או טווח ספציפיים. לדוגמה, ציון "1" אומר שכל מחלקה עם תפקיד נתון חייבת להשתתף במופע כלשהו של החיבור הזה, ואובייקט אחד בדיוק של המחלקה עם התפקיד הזה יכול להשתתף בכל מופע של החיבור. ציון הטווח "0..1" מציין שלא כל האובייקטים של המחלקה עם תפקיד נתון נדרשים להשתתף בכל מופע של קשר זה, אלא רק אובייקט אחד יכול להשתתף בכל מופע של הקשר. בואו נדבר על ריבוי ביתר פירוט. הקרדינליות האופייניות והנפוצות ביותר במערכות עיצוב מסד נתונים הן הקרדינליות הבאות: 1) 1 - ריבוי החיבור בקצה המתאים שלו שווה לאחד; 2) 0... 1 - צורת סימון זו פירושה שהריבוי של חיבור נתון בקצה המתאים לו אינו יכול לעלות על אחד; 3) 0... ∞ - ריבוי זה מפוענח פשוט כ"רבים". זה מוזר שככלל, "הרבה" פירושו "כלום"; 4) 1... ∞ - ייעוד זה ניתן לריבוי "אחד או יותר". הבה ניתן דוגמה לתרשים פשוט כדי להמחיש את העבודה עם ריבוי קישורים שונים.
לפי התרשים הזה, אפשר להבין בקלות שלכל משרד כרטיסים יש כרטיסים רבים, ובתמורה, כל כרטיס ממוקם במשרד כרטיסים אחד (ולא יותר מזה). כעת שקול את הסוגים או השמות הנפוצים ביותר של קישורים. בואו נרשום אותם: 1) 1:1 - ייעוד זה ניתן לחיבור "אחד לאחד"כלומר, מדובר, כביכול, בהתכתבות אחת לאחד של שתי קבוצות; 2) 1 : 0... ∞ - זהו ייעוד לחיבור כמו "אחד לרבים". לקיצור, קשר כזה נקרא "1: M". בתרשים שנחשב קודם לכן, כפי שאתה יכול לראות, יש קשר עם שם כזה; 3) 0... ∞ : 1 - זהו היפוך של החיבור הקודם או חיבור מהסוג "רבים לאחד"; 4) 0... ∞ : 0... ∞ הוא ייעוד לחיבור כמו "רבים לרבים", כלומר יש תכונות רבות בכל קצה של הקישור; 5) 0... 1 : 0... 1 - זהו חיבור דומה לחיבור מסוג "אחד לאחד" שהוצג קודם לכן, הוא, בתורו, נקרא "לא יותר מאחד עד לא יותר מאחד"; 6) 0... 1 : 0... ∞ - זהו חיבור דומה לחיבור של אחד לרבים, הוא נקרא "לא יותר מאחד לרבים"; 7) 0... ∞ : 0... 1 - זהו חיבור, בתורו, בדומה לחיבור מסוג רבים-לאחד, הוא נקרא "רבים עד לא יותר מאחד". כפי שניתן לראות, שלושת הקשרים האחרונים התקבלו מהקשרים המפורטים בהרצאתנו תחת המספרים אחת, שתיים ושלוש על ידי החלפת הריבוי של "אחד" בריבוי של "לא יותר מאחד". 2. דיאגרמות. סוגי תרשימים ועכשיו בואו סוף סוף נמשיך ישירות לשיקול של דיאגרמות וסוגיהם. באופן כללי, ישנן שלוש רמות של המודל הלוגי. רמות אלו נבדלות בעומק הייצוג של מידע על מבנה הנתונים. רמות אלו מתאימות לתרשימים הבאים: 1) דיאגרמת מצגת; 2) דיאגרמת מפתח; 3) דיאגרמת תכונות מלאה. הבה ננתח כל אחד מסוגי הדיאגרמות הללו ונסביר בפירוט את המשמעות של ההבדלים ביניהם בעומק הצגת המידע על מבנה הנתונים. 1. תרשים מצגת. דיאגרמות כאלה מתארות רק את המחלקות הבסיסיות ביותר של ישויות ואת היחסים ביניהן. ייתכן שהמפתחות בתרשימים כאלה לא יתוארו כלל, ובהתאם לכך, ייתכן שהחיבורים לא יהיו אינדיבידואליים בשום אופן. לכן, מערכות יחסים רבות לרבים מקובלות, למרות שבדרך כלל נמנעים מהן או, אם הן קיימות, מכוונות עדינות. גם תכונות מורכבות ורב-ערכיות תקפות לחלוטין, למרות שכתבנו קודם שיחסי בסיס עם תכונות כאלה אינם מופחתים לשום צורה נורמלית. מעניין שמבין שלושת סוגי הדיאגרמות שחשבנו, רק הסוג האחרון (דיאגרמת התכונות המלאה) מניח שהנתונים המוצגים איתו הם בצורה נורמלית כלשהי. בעוד שדיאגרמת המצגת שכבר נחשבה ותרשים המפתח הבא בתור אינם מרמזים על שום דבר מסוג זה. דיאגרמות כאלה משמשות בדרך כלל למצגות (מכאן שמם - פרזנטלי, כלומר, משמשים למצגות, הדגמות, כאשר אין צורך בפרטים מופרזים). לעיתים בעת עיצוב מאגרי מידע יש צורך להתייעץ עם מומחים בתחום שמאגר המידע הספציפי הזה עוסק במידע. לאחר מכן נעשה שימוש גם בדיאגרמות מצגות, מכיוון שכדי לקבל את המידע הדרוש ממומחים במקצוע רחוק מתכנות, אין צורך בבירור מוגזם של פרטים ספציפיים כלל. 2. דיאגרמת מפתח. שלא כמו דיאגרמות מצגת, דיאגרמות מפתח מתארות בהכרח את כל מחלקות הישויות והיחסים ביניהן, עם זאת, במונחים של מפתחות ראשיים בלבד. כאן, יחסים רבים-לרבים כבר בהכרח מפורטים (כלומר, יחסים מסוג זה בצורתם הטהורה פשוט לא ניתן לפרט כאן). תכונות מרובות ערכים עדיין מותרות באותו אופן כמו בתרשים מצגת, אך אם הן קיימות בתרשים מפתח, הן מומרות בדרך כלל למחלקות ישות עצמאיות. אבל, באופן מוזר, תכונות חד משמעיות עדיין יכולות להיות מיוצגות באופן חלקי או מתוארות כמרוכבות. ה"חירויות" הללו, שעדיין תקפות בתרשימים כמו מצגת ודיאגרמות מפתח, אינן מותרות בסוג הדיאגרמה הבאה, משום שהן קובעות שיחס הבסיס אינו מנורמל. לפיכך, אנו יכולים להסיק שדיאגרמות מפתח בעתיד מניחות רק תכונות "תלויות" על מחלקות ישויות שתוארו כבר, כלומר באמצעות דיאגרמת מצגת, די לתאר את מחלקות הישות הנחוצות ביותר, ולאחר מכן, באמצעות דיאגרמת מפתח, להוסיף הכל אליו תכונות הכרחיות וציין את כל הקישורים החשובים ביותר. 3. דיאגרמת תכונות מלאה. דיאגרמות תכונות מלאות מתארות בפירוט רב מכל האמור לעיל את כל מחלקות הישויות, את התכונות והיחסים שלהן בין מחלקות הישויות הללו. ככלל, תרשימים כאלה מייצגים נתונים שהם בצורה הנורמלית השלישית, ולכן טבעי שביחסים הבסיסיים המתוארים בתרשימים כאלה, תכונות מורכבות או מרובות ערכים אינן מותרות, בדיוק כפי שאין הרבה-ל-גרגירים לא-גרעיניים. מערכות יחסים רבות. עם זאת, לתרשימי תכונות שלמים עדיין יש חיסרון, כלומר, לא ניתן לקרוא להם במלואם השלם ביותר מבין התרשימים מבחינת הצגת הנתונים. לדוגמה, המוזרות של מערכות ניהול מסד נתונים ספציפיות בעת שימוש בדיאגרמות תכונות מלאות עדיין לא נלקחת בחשבון, ובמיוחד, סוג הנתונים מצוין רק במידה הדרושה לרמה הלוגית הנדרשת של מידול. 3. עמותות והגירת מפתח קצת קודם, כבר דיברנו על מה זה מערכות יחסים במאגרי מידע. בפרט, הקשר נוצר בעת ההכרזה על מפתחות הזרים של הקשר. אבל בחלק זה של הקורס שלנו כבר לא מדברים על יחסים בסיסיים, אלא על קופות של גופים. במובן זה, תהליך יצירת קשרים עדיין קשור להצהרות של מפתחות שונים, אבל עכשיו אנחנו מדברים על מפתחות של כיתות ישויות. כלומר, תהליך יצירת קשרים קשור להעברת מפתח ראשי פשוט או מורכב של מחלקת ישות אחת למחלקה אחרת. תהליך העברה כזה נקרא גם הגירת מפתח. במקרה זה, מחלקת הישות שהמפתחות הראשיים שלה מועברים נקראת כיתת הורים, ומחלקת הישויות אליה מועברים מפתחות זרים נקראת כיתת ילדים ישויות. במחלקה של ישות ילדה, תכונות מפתח מקבלות את הסטטוס של תכונות מפתח זר ועשויות להשתתף או לא להשתתף ביצירת המפתח הראשי שלה. לפיכך, כאשר מפתח ראשי מועבר מהורה למחלקת ישות צאצא, מופיע מפתח זר במחלקת הילד המתייחס למפתח הראשי של מחלקת האב. לנוחות הייצוג הנוסחאי של הגירת מפתח, אנו מציגים את סמני המפתח הבאים: 1) PK - כך נסמן כל תכונה של המפתח הראשוני (המפתח הראשי); 2) FK - בסמן זה נסמן את התכונות של מפתח זר (מפתח זר); 3) PFK - עם סמן כזה נסמן תכונה של מפתח ראשי / זר, כלומר כל תכונה כזו שהיא חלק מהמפתח הראשוני היחיד של מחלקת ישות כלשהי ובו זמנית היא חלק ממפתח זר כלשהו של אותה מחלקת ישות . לפיכך, תכונות של מחלקת ישות עם סמני PK ו-FK מהוות את המפתח העיקרי של מחלקה זו. ותכונות עם סמני FK ו PFK הם חלק מכמה מפתחות זרים של מחלקת הישות הזו. באופן כללי, מפתחות יכולים להגר בדרכים שונות, ובכל מקרה שונה כזה נוצר קשר כלשהו. אז בואו נבחן אילו סוגי קישורים קיימים בהתאם לתכנית ההגירה המרכזית. בסך הכל, ישנן שתי תוכניות הגירה מרכזיות. 1. תכנית הגירה ∀PK (PK |→PFק); בערך זה, הסמל "|→" פירושו המושג "נודד", כלומר הנוסחה לעיל תיקרא כך: כל (כל) תכונה של המפתח הראשי PK של מחלקת הישות האב מועברת (נודד) ל- מפתח ראשי PFK child entity class, שהוא, כמובן, גם מפתח זר עבור מחלקה זו. במקרה זה, אנו מדברים על העובדה שללא יוצא מן הכלל, כל תכונת מפתח של מחלקת הישות ההורה חייבת להיות מועברת למחלקת הישות הילדית. סוג זה של חיבור נקרא זיהוי, שכן המפתח של כיתת הישות ההורה מעורב כולו בזיהוי ישויות ילדות. בין הקישורים מהסוג המזהה, בתורם, ישנם שני סוגי קישורים אפשריים נוספים. אז, ישנם שני סוגים של קישורים מזהים: 1) זיהוי מלא. מערכת יחסים מזהה אמורה להיות מזהה באופן מלא אם ורק אם התכונות של המפתח הראשי הנודד של מחלקת הישות ההורה יוצרות לחלוטין את המפתח הראשי (והזר) של מחלקת הישות הבת. מערכת יחסים מזהה לחלוטין נקראת לפעמים גם קָטֵגוֹרִי, מכיוון שמערכת יחסים מזהה באופן מלא מזהה ישויות ילד בכל הקטגוריות; 2) לא מזהה לחלוטין. מערכת יחסים מזהה נקראת זיהוי חלקי אם ורק אם התכונות של המפתח הראשי הנודד של מחלקת הישות ההורה יוצרות רק באופן חלקי את המפתח הראשי (ובמקביל הזר) של מחלקת הישות הילדית. כך, בנוסף למפתח עם הסמן PFל-K יהיה גם מפתח מסומן PK. במקרה זה, המפתח הזר PFK של מחלקת הישות הילד ייקבע לחלוטין על ידי המפתח הראשי PK של מחלקת הישות ההורה, אך פשוט המפתח הראשי PK של מערכת היחסים הילדית לא ייקבע על ידי המפתח הראשי PK של ההורה מחלקת ישות, זה יהיה בפני עצמו. 2. תכנית הגירה ∃PK (PK |→ FK); יש לקרוא סכימת העברה כזו כדלקמן: ישנן תכונות מפתח ראשוניות כאלה של מחלקת הישות האב, שבמהלך ההגירה, מועברות לתכונות החובה שאינן מפתחות של מחלקת הישות הילד. לפיכך, במקרה זה, אנו מדברים על העובדה שחלק, ולא כולם, כמו במקרה הקודם, תכונות המפתח העיקריות של מחלקת הישות ההורה מועברות למחלקת הישות הילדית. בנוסף, אם סכימת ההגירה הקודמת הגדירה העברה למפתח הראשי של קשר הילד, שבמקביל גם הפך למפתח זר, אזי הסוג האחרון של ההעברה קובע שתכונות המפתח הראשי של מחלקת הישות האב עוברות למפתח רגיל. , בתחילה מאפיינים שאינם מפתח, אשר לאחר מכן מקבלים סטטוס מפתח זר. סוג זה של חיבור נקרא לא מזהה, מכיוון שאכן, מפתח האב אינו מעורב לחלוטין ביצירת ישויות ילדות, הוא פשוט לא מזהה אותן. בין מערכות יחסים לא מזהות, מבחינים גם בשני סוגים אפשריים של מערכות יחסים. לפיכך, קשרים לא מזהים הם משני הסוגים הבאים: 1) בהכרח לא מזהה. מערכות יחסים לא מזהות אמורות להיות בהכרח לא מזהות אם ורק אם ערכי Null עבור כל תכונות המפתח המעבירות של מחלקת ישות ילד אסורים; 2) אופציונלי לא מזהה. אומרים כי קשרים לא מזהים אינם בהכרח בלתי מזהים אם ורק אם מותרים ערכי null עבור כמה תכונות מפתח נודדות של מחלקת הישות הילדית. אנו מסכמים את כל האמור לעיל בצורה של הטבלה הבאה על מנת להקל על המשימה של שיטתיות והבנת החומר המוצג. כמו כן, בטבלה זו נכלול מידע לגבי סוגי קשרים ("לא יותר מאחד לאחד", "רבים לאחד", "רבים עד לא יותר מאחד") מתאימות לאילו סוגי קשרים (מזהה מלא, לא מלא מזהה, בהכרח לא מזהה, לא בהכרח לא מזהה). לכן, בין כיתות ההורה והילד, נוצר סוג הקשר הבא, בהתאם לסוג הקשר.
אז, אנו רואים שבכל המקרים מלבד האחרון, ההפניה אינה ריקה (לא ריק) → 1. שימו לב למגמה שבקצה האב של החיבור בכל המקרים מלבד האחרון, הריבוי מוגדר ל"אחד". הסיבה לכך היא שהערך של המפתח הזר במקרים של קשרים אלה (כלומר, זיהוי מלא, לא זיהוי מלא, ובהכרח לא מזהה סוגי קשרים) חייב בהכרח להתאים (ויתרה מכך, הערך היחיד) של המפתח הראשי של כיתת הישות ההורה. ובמקרה האחרון, בשל העובדה שהערך של המפתח הזר יכול להיות שווה לערך Null (הדגל של FK: null validity), הריבוי מוגדר ל"לא יותר מאחד" בקצה האב של מערכת יחסים. אנו מבצעים את הניתוח שלנו הלאה. בסוף הילד של הקשר, בכל המקרים, למעט הראשון, הריבוי מוגדר ל"רבים". הסיבה לכך היא שבגלל זיהוי לא שלם, כמו במקרה השני, (או ללא זיהוי כזה בכלל, במקרים השני והשלישי), הערך של המפתח הראשי של מחלקת הישות האב יכול להופיע שוב ושוב בין הערכים של מפתח הזר של כיתת הילד. ובמקרה הראשון, הקשר מזוהה באופן מלא, כך שהתכונות של המפתח הראשי של מחלקת הישות ההורה יכולות להופיע רק פעם אחת בין התכונות של המפתחות של מחלקת הישות הילד. הרצאה מס' 12. קשרי כיתות ישות אז, כל המושגים שעברנו, כלומר דיאגרמות וסוגיהם, ריבוי וסוגי מערכות יחסים, כמו גם סוגי הגירת מפתח, יעזרו לנו כעת לעבור על החומר על אותם מערכות יחסים, אבל כבר בין מחלקות ספציפיות של ישויות. ביניהם, כפי שנראה, יש גם קשרים מסוגים שונים. 1. קשר רקורסיבי היררכי הסוג הראשון של מערכת היחסים בין מחלקות ישויות, שאותו נשקול, הוא מה שנקרא מערכת יחסים רקורסיבית היררכית. באופן כללי רקורסיה (או קישור רקורסיבי) הוא היחס של מחלקת ישות לעצמה. לפעמים, באנלוגיה למצבי חיים, חיבור כזה נקרא גם "קרס דג". קשר רקורסיבי היררכי (או בפשטות רקורסיה היררכית) הוא כל קשר רקורסיבי מסוג "לכל היותר אחד לרבים". הרקורסיה היררכית משמשת לרוב לאחסון נתונים במבנה עץ. בעת ציון מערכת יחסים רקורסיבית היררכית, יש להעביר את המפתח הראשי של מחלקת הישות האב (שבמקרה הספציפי הזה פועלת גם כמחלקת ישות צאצאית) כמפתח זר לתכונות החובה שאינן מפתח של אותה מחלקת ישות. כל זה נחוץ כדי לשמור על השלמות הלוגית של עצם המושג "רקורסיה היררכית". לפיכך, בהתחשב בכל האמור לעיל, אנו יכולים להסיק שמערכת יחסים רקורסיבית היררכית יכולה להיות רק לא בהכרח לא מזהה ולא אחר, כי אם נעשה שימוש בכל סוג אחר של קשר, ערכי Null עבור המפתח הזר יהיו לא חוקיים והרקורסיה תהיה אינסופית. חשוב גם לזכור שתכונות אינן יכולות להופיע פעמיים באותה מחלקת ישות תחת אותו שם. לכן, יש לתת לתכונות של המפתח המועבר את מה שנקרא שם תפקיד. לפיכך, ביחסים רקורסיביים היררכיים, התכונות של צומת מורחבות עם מפתח זר המהווה התייחסות אופציונלית למפתח הראשי של הצומת שהוא האב הקדמון המיידי שלו. בואו נבנה מצגת ודיאגרמות מפתח המיישמות רקורסיה היררכית במודל נתונים רלציוני, וניתן דוגמה לטופס טבלאי. תחילה ניצור תרשים מצגת:
עכשיו בואו נבנה תרשים מפתח מפורט יותר:
שקול דוגמה הממחישה בבירור סוג כזה של מערכת יחסים כמו מערכת יחסים רקורסיבית היררכית. תן לנו את מחלקת הישות הבאה, אשר, כמו הדוגמה הקודמת, מורכבת מהתכונות "קוד קדמון" ו"קוד צומת". ראשית, הבה נציג ייצוג טבלאי של מחלקת הישות הזו:
כעת נבנה דיאגרמה המייצגת סוג זה של ישויות. לשם כך, אנו בוחרים מהטבלה את כל המידע הדרוש לכך: האב הקדמון של הצומת עם הקוד "אחד" אינו קיים או אינו מוגדר, מכאן אנו מסיקים שהצומת "אחד" הוא קודקוד. אותו צומת "אחד" הוא האב הקדמון של צמתים עם הקוד "שתיים" ו"שלוש". בתורו, לצומת עם הקוד "שתיים" יש שני ילדים: הצומת עם הקוד "ארבע" והצומת עם הקוד "חמש". ולצומת עם הקוד "שלוש" יש רק ילד אחד - הצומת עם הקוד "שש". אז, בהתחשב בכל האמור לעיל, בואו נבנה מבנה עץ המשקף את המידע על הנתונים הכלולים בטבלה הקודמת:
אז ראינו שזה באמת נוח לייצג מבני עצים באמצעות מערכת יחסים רקורסיבית היררכית. 2. תקשורת רקורסיבית ברשת החיבור הרקורסי של הרשת של מחלקות ישויות בינן לבין עצמן הוא, כביכול, אנלוגי רב ממדי לחיבור הרקורסי ההיררכי שכבר עברנו דרכו. רק אם רקורסיה היררכית הוגדרה כיחס רקורסיבי "לכל היותר אחד לרבים", אז רקורסיה ברשת מייצג את אותו קשר רקורסיבי, רק מסוג "רבים לרבים". בשל העובדה שקבוצות רבות של ישויות משתתפות בחיבור זה מכל צד, הוא נקרא חיבור רשת. כפי שאתה כבר יכול לנחש באנלוגיה לרקורסיה היררכית, קישורים מסוג רקורסיה רשת נועדו לייצג מבני נתונים גרפים (בעוד קישורים היררכיים משמשים, כזכור, אך ורק ליישום מבני עצים). אבל, מכיוון שבחיבור של סוג הרקורסיה של הרשת מצוינים החיבורים מסוג "רבים לרבים", אי אפשר בלי פירוט נוסף שלהם. לכן, על מנת לחדד את כל מערכות היחסים של רבים-לרבים בסכמה, יש צורך ליצור מחלקת ישות עצמאית חדשה המכילה את כל ההפניות להורה או צאצא של מערכת היחסים Ancestor-Descendant. מחלקה כזו נקראת בדרך כלל מחלקת ישות אסוציאטיבית. במקרה הספציפי שלנו (במאגרי המידע שיש לקחת בחשבון בקורס שלנו), לישות האסוציאטיבית אין תכונות נוספות משלה והיא נקראת יִעוּד, כי הוא נותן שמות ליחסי האב-צאצא על ידי הפניה אליהם. לפיכך, יש להעביר את המפתח הראשי של מחלקת הישות המייצגת את המארחים פעמיים למחלקות הישות האסוציאטיביות. במחלקה זו, המפתחות שהועברו יחד חייבים ליצור מפתח ראשי מורכב. מהאמור לעיל, אנו יכולים להסיק שיצירת קישורים בעת שימוש ברקורסיה ברשת לא צריכה להיות מזהה לחלוטין ותו לא. בדיוק כמו בעת שימוש בקשר רקורסיבי היררכי, כאשר משתמשים ברקורסית רשת כקשר, אף תכונה לא יכולה להופיע פעמיים באותה מחלקת ישות תחת אותו שם. לכן, כמו בפעם הקודמת, נקבע במפורש שכל התכונות של מפתח המעבר חייבות לקבל את שם התפקיד. כדי להמחיש את פעולתה של תקשורת רקורסיבית ברשת, בואו נבנה מצגת ודיאגרמות מפתח המיישמות רקורסיה של רשת במודל נתונים רלציוני. נתחיל בתרשים מצגת:
עכשיו בואו נבנה תרשים מפתח מפורט יותר:
מה אנחנו רואים כאן? ואנחנו רואים ששני החיבורים בתרשים מפתח זה הם חיבורים "רבים לאחד". יתרה מכך, הריבוי "0... ∞" או הריבוי "רבים" נמצא בסוף הקשר מול מחלקת השמות של הישויות. אכן, ישנם קישורים רבים, אך כולם מתייחסים לקוד צומת אחד, שהוא המפתח העיקרי של מחלקת הישות "Nodes". ולבסוף, בואו נשקול דוגמה הממחישה את הפעולה של סוג כזה של חיבור על ידי מחלקת ישות כמו רקורסיה ברשת. תנו לנו ייצוג טבלאי של מחלקת ישות כלשהי, כמו גם מחלקת שמות של ישות המכילה מידע על קישורים. בואו נסתכל על הטבלאות הללו. קשרים:
קישורים:
ואכן, הייצוג לעיל הוא ממצה: הוא נותן את כל המידע הדרוש על מנת לשחזר בקלות את מבנה הגרף המקודד כאן. לדוגמה, אנו יכולים לראות ללא מכשולים שלצומת עם הקוד "אחד" יש שלושה ילדים, בהתאמה, עם הקודים "שניים", "שלושה" ו"ארבע". אנו רואים גם שלצמתים עם הקודים "שתיים" ו"שלוש" אין צאצאים כלל, ולצומת עם קוד "ארבע" יש (כמו גם צומת "אחד") שלושה צאצאים עם הקודים "אחד", "שניים" ו שְׁלוֹשָׁה". בואו נצייר גרף שניתן על ידי מחלקות הישות המפורטות לעיל:
אז, הגרף שבנינו זה עתה הוא הנתונים שעבורם מחלקות הישות קושרו באמצעות חיבור מסוג רקורסיה ברשת. 3. עמותה מכל סוגי הקשרים הנכללים בבחינת מהלך ההרצאות המסוים שלנו, רק שניים הם קשרים רקורסיביים. כבר הספקנו לשקול אותם, אלו הם קישורים היררכיים ורקורסיביים ברשת, בהתאמה. כל סוגי היחסים האחרים שעלינו לשקול אינם רקורסיביים, אלא, ככלל, מייצגים מערכת יחסים של מספר הורים ומספר כיתות של ישות ילדים. יתרה מכך, כפי שניתן לנחש, כיתות ההורה והילד לעולם לא יתחברו (אכן, אנחנו כבר לא מדברים על רקורסיה). הקשר, עליו נדון בחלק זה של ההרצאה, נקרא אסוציאציה ומתייחס בדיוק לסוג הבלתי רקורסיבי של קשרים. אז הקשר התקשר אִרגוּן, מיושם כקשר בין מחלקות ישות הורה מרובות לכיתה אחת של ישות ילד. ויחד עם זאת, וזה מוזר, מערכת יחסים זו מתוארת על ידי מערכות יחסים מסוגים שונים. כמו כן, ראוי לציין שיכול להיות רק כיתת ישות אב אחת במהלך השיוך, כמו ברקורסיה ברשת, אך גם במצב כזה, מספר הקשרים המגיעים מכיתת הישות הילד חייב להיות לפחות שניים. מעניין שבאסוציאציה, כמו גם ברקורסיה ברשת, ישנם סוגים מיוחדים של כיתות ישויות. דוגמה לכיתה כזו היא כיתת ישות ילד. ואכן, במקרה הכללי, בעמותה, נקרא כיתת ישות ילד מחלקת ישות אסוציאטיבית. במקרה המיוחד כאשר למחלקה של ישות אסוציאטיבית אין תכונות נוספות משלה והיא מכילה רק תכונות הנודדות יחד עם מפתחות ראשיים ממחלקות ישות אב, מחלקה כזו נקראת מחלקה של שמות ישויות. כפי שניתן לראות, יש אנלוגיה כמעט מוחלטת למושג של ישויות אסוציאטיביות ושמות בחיבור רקורסיבי ברשת. לרוב, אסוציאציה משמשת לחידוד (לפתור) מערכות יחסים רבות לרבים. בואו נמחיש את ההצהרה הזו. הבה, למשל, ניתן לנו את דיאגרמת המצגת הבאה, המתארת את תכנית קבלת רופא מסוים בבית חולים מסוים:
תרשים זה אומר, מילולית, שיש הרבה רופאים ומטופלים רבים בבית החולים, ואין שום קשר והתכתבות אחרת בין רופאים לחולים. כך, כמובן, עם מאגר מידע כזה, לעולם לא יהיה ברור להנהלת בית החולים כיצד לתאם פגישות עם רופאים שונים למטופלים שונים. ברור שהקשרים הרבים לרבים המשמשים כאן פשוט צריכים להיות מפורטים כדי לממש את היחסים בין הרופאים והמטופלים השונים, במילים אחרות, לארגן באופן רציונלי את לוח הפגישות של כל הרופאים ומטופליהם ב בית החולים. ועכשיו בואו נבנה תרשים מפתח מפורט יותר, שבו כבר נפרט את כל מערכות היחסים הקיימות של רבים-לרבים. לשם כך, נכניס בהתאם מחלקה חדשה של ישות, נקרא לה "קבל", שתפעל כמחלקת ישות אסוציאטיבית (בהמשך נראה מדוע זו תהיה מחלקת ישות אסוציאטיבית, ולא רק מחלקה של שמות ישויות, שעליהן דיברנו קודם לכן). אז דיאגרמת המפתח שלנו תיראה כך:
אז עכשיו אתה יכול לראות בבירור מדוע המחלקה החדשה "מקבלת" אינה מחלקה של שמות ישויות. אחרי הכל, למחלקה הזו יש תכונה נוספת משלה "תאריך - זמן", ולכן, על פי ההגדרה, המחלקה החדשה שהוצגה "קבלה" היא מחלקה של ישויות אסוציאטיביות. מחלקה זו "מקשרת" את כיתות הישות "רופאים" ו"מטופלים" זה עם זה באמצעות הזמן בו מבוצעת פגישה כזו או אחרת, מה שהופך את העבודה עם מאגר כזה לנוחה הרבה יותר. לפיכך, על ידי הצגת התכונה "תאריך - שעה", ממש ארגנו את לוח הזמנים הנחוץ לעבודה עבור רופאים שונים. אנו רואים גם שהמפתח הראשי החיצוני "קוד הרופא" של מחלקת הישות "קבלה" מתייחס למפתח הראשי בעל אותו השם של מחלקת הישות "רופאים". ובאופן דומה, המפתח הראשי החיצוני "קוד מטופל" של מחלקת הישות "קבלה" מתייחס למפתח הראשי באותו שם במחלקת הישות "מטופל". במקרה זה, כמובן, כיתות הישות "רופאים" ו"מטופל" הן ההורה, ומחלקת הישות האסוציאטיבית "קבלה", בתורה, היא הילד היחיד. אנו יכולים לראות שהקשר של רבים-לרבים בתרשים המצגת הקודם מפורט כעת במלואו. במקום הקשר האחד של רבים-לרבים שאנו רואים בתרשים המצגת למעלה, יש לנו שני קשרים רבים-לרבים. לסוף הילד של מערכת היחסים הראשונה יש את הריבוי "רבים", שפירושו המילולי הוא שבמעמד הישות "קבלה" יש רופאים רבים (כולם בבית החולים). ובקצה ההורה של הקשר הזה נמצא הריבוי של "אחד", מה זה אומר? המשמעות היא שבמחלקת הישות "קבלה", כל אחד מהקודים הזמינים של כל רופא מסוים יכול להתרחש ללא הגבלה פעמים רבות. ואכן, בלוח הזמנים בבית החולים מופיע הקוד של אותו רופא פעמים רבות, בימים ובשעות שונות. והנה אותו קוד, אבל כבר במחלקת הישות "רופאים", הוא יכול להתרחש פעם אחת ורק פעם אחת. ואכן, ברשימת כל רופאי בית החולים (ומעמד הישות "רופאים" אינו אלא רשימה כזו), הקוד של כל רופא מסוים יכול להיות נוכח פעם אחת בלבד. דבר דומה קורה ביחסים בין כיתת ההורים "מטופל" לכיתת הילד "מטופל". ברשימת כל החולים בבית החולים (במחלקת הישות "מטופלים"), הקוד של כל חולה ספציפי יכול להופיע פעם אחת בלבד. אבל מצד שני, בלוח הזמנים של פגישות (במחלקת הישות "קבלה"), כל קוד של מטופל מסוים יכול להתרחש באופן שרירותי פעמים רבות. לכן הכפלים בקצות הקשר מסודרים כך. כדוגמה ליישום שיוך במודל נתונים רלציוני, בואו נבנה מודל המתאר את לוח הפגישות בין הלקוח לקבלן בהשתתפות אופציונלית של יועצים. לא נתעכב על דיאגרמת המצגת, כי עלינו לשקול את בניית התרשימים לכל הפרטים, ותרשים המצגת אינו יכול לספק הזדמנות כזו. לכן, בואו נבנה תרשים מפתח המשקף את מהות הקשר בין הלקוח, הקבלן והיועץ.
אז בואו נתחיל בניתוח מפורט של דיאגרמת המפתח לעיל. ראשית, המחלקה "גרף" היא מחלקה של ישויות אסוציאטיביות, אבל, כמו בדוגמה הקודמת, היא לא מחלקה של ישויות בשם, כי יש לה תכונה שאינה נודדת אליה יחד עם המפתחות, אלא היא שלה. תכונה משלו. זוהי התכונה "תאריך - שעה". שנית, אנו רואים שהתכונות של מחלקת הישות "תרשים" "קוד לקוח", "קוד מבצע" ו"תאריך - שעה" יוצרות מפתח ראשי מורכב של מחלקת ישות זו. התכונה "קוד יועץ" היא פשוט מפתח זר של מחלקת הישות "תרשים". שימו לב שתכונה זו מאפשרת ערכי Null בין ערכיה, מכיוון שעל פי התנאי אין צורך בנוכחות יועץ בפגישה. בנוסף, שלישית, נציין ששני הקישורים הראשונים (משלושת הקישורים הזמינים) אינם מזהים לחלוטין. כלומר, לא מזהה באופן מלא, מכיוון שהמפתח המעביר בשני המקרים (מפתחות ראשיים "קוד לקוח" ו"קוד מבצע") אינו מהווה לחלוטין את המפתח הראשי של מחלקת הישות "גרף". ואכן, תכונת "תאריך - זמן" נשארת, שהיא גם חלק מהמפתח הראשי המשולב. בקצות שתי הקשרים המזהים הלא-שלם הללו, מסומנים הכפלים "אחד" ו"רבים". זה נעשה על מנת להראות (כמו בדוגמה על רופאים ומטופלים) את ההבדל בין אזכור הקוד של הלקוח או המבצע במחלקות ישות שונות. ואכן, במחלקת הישות "גרף", כל קוד לקוח או קבלן יכול להתרחש כמה פעמים שתרצה. לכן, בקצה הקשר הזה, ילד, יש ריבוי של "רבים". ובמחלקת הישות "לקוחות" או "קבלנים", כל אחד מהקודים של הלקוח או הקבלן, בהתאמה, יכול להתרחש פעם אחת ויחידה, מכיוון שסוגי ישויות אלו הם כל אחד לא יותר מרשימה מלאה של כל הלקוחות והמבצעים. לכן, בזה, קצה האב של הקשר, יש ריבוי של "אחד". ולבסוף, שים לב שהקשר השלישי, כלומר הקשר של מחלקת הישות "גרף" עם מחלקת הישות "יועצים", אינו בהכרח בלתי מזהה. ואכן, במקרה זה, אנו מדברים על העברה של תכונת המפתח "קוד יועץ" של מחלקת הישות "יועצים" לתכונת הלא מפתח של מחלקת הישות "גרף" באותו שם, כלומר המפתח הראשי של מחלקת הישות "יועצים" במחלקת הישות "גרף" אינה מזהה מפתח ראשי כבר של מחלקה זו. וחוץ מזה, כפי שצוין קודם, התכונה "קוד יועץ" מאפשרת ערכי Null, כך שכאן משתמשים בדיוק בקשר הלא מזהה. לפיכך, התכונה "קוד יועץ" מקבלת מעמד של מפתח זר ותו לא. הבה נשים לב גם לריבוי הקישורים המוצבים בקצוות ההורה והילד של הקישור הבלתי-מזהה הזה. לקצה האב שלו יש ריבוי של "לא יותר מאחד". ואכן, אם נזכור את ההגדרה של מערכת יחסים שאינה בלתי מזוהה לחלוטין, אזי נבין שהתכונה "קוד יועץ" ממחלקת הישות "גרף" אינה יכולה להתאים ליותר מקוד יועץ אחד מרשימת כל היועצים. (שהיא מחלקת הישות "יועצים"). ובכלל, עלול להתברר שהוא לא יתאים לשום קוד יועץ (זכור את תיבת הסימון לקבילות ערכי Nullקוד יועץ: Null), כי לפי התנאי, נוכחות של יועץ ב- פגישה בין הלקוח לקבלן, באופן כללי, אינה הכרחית. 4. הכללות סוג נוסף של קשר בין מחלקות ישות, שאותו נשקול, הוא קשר של הטופס הַכלָלָה. זה גם סוג לא רקורסיבי של מערכת יחסים. אז מערכת יחסים כמו הַכלָלָה מיושם כקשר של כיתת ישות הורה אחת עם מספר כיתות ישות ילדות (בניגוד לקשר האגודה הקודם, שעסק במספר כיתות ישות אב ובכיתה אחת של ישות ילד). בעת ניסוח כללי ייצוג נתונים תוך שימוש בקשר ההכללה, יש לומר מיד שקשר זה של מחלקה אחת של ישות אב ומספר מחלקות של ישות ילד מתואר על ידי קשרים מזהים באופן מלא, כלומר קשרים קטגוריים. נזכור את ההגדרה של מערכות יחסים מזהות במלואן, אנו מסיקים כי בעת שימוש בהכללה, כל תכונה של המפתח הראשי של מחלקת הישות ההורה מועברת למפתח הראשי של מחלקות הישות הצאצא, כלומר, התכונות של מפתח ההגירה הראשי של האב. כיתת ישות מהווים לחלוטין את המפתחות העיקריים של כל כיתות הישות הילד, הם מזהים אותם. מעניין לציין שההכללה מיישמת את מה שנקרא היררכיית קטגוריות או היררכיית ירושה. במקרה זה, מחלקת ישות האב מגדירה מחלקת ישות גנרית, מאופיין בתכונות המשותפות לישויות של כל כיתות הילדים או מה שנקרא ישויות קטגוריות כלומר, כיתת ישות אב היא הכללה מילולית של כל מחלקות הישות הילדות שלה. כדוגמה ליישום הכללה במודל נתונים יחסי, נבנה את המודל הבא. מודל זה יתבסס על המושג הכללי של "סטודנטים" ויתאר את המושגים הקטגוריים הבאים (כלומר, הוא יכלל את כיתות הישות הבאות): "ילדי בית ספר", "סטודנטים" ו"סטודנטים לתארים מתקדמים". אז בואו נבנה דיאגרמת מפתח המשקפת את מהות הקשר בין מחלקת הישות ההורה למחלקות הישות הילדות, המתוארת על ידי חיבור מסוג Generalization.
אז מה אנחנו רואים? ראשית, כל אחד מהיחסים הבסיסיים (או מכיתות ישות, שזה אותו דבר) "תלמידי בית ספר", "סטודנטים" ו"סטודנטים לתארים מתקדמים" תואמים את התכונות שלו, כגון "כיתה", "קורס" ו"שנת לימוד ". כל אחת מהתכונות הללו מאפיינת חברים במחלקת הישות שלה. אנו רואים גם שהמפתח הראשי של מחלקת הישות ההורה "סטודנטים" נודד לכל כיתת ישות ילד ויוצר שם את המפתח הזר הראשי. בעזרת קשרים אלה, נוכל לקבוע לפי הקוד של כל תלמיד את שמו הפרטי, שם משפחתו ומשפחתו, מידע עליו לא נמצא בכיתות הישות המתאימות עצמם. שנית, מכיוון שאנו מדברים על קשר זיהוי מלא (או קטגורי) של כיתות ישויות, נשים לב לריבוי הקשרים בין כיתת הישות ההורה לכיתות הילד שלה. לקצה האב של כל אחד מהקישורים הללו יש ריבוי של "אחד", ולכל קצה צאצא של הקישורים יש ריבוי של "אחד לכל היותר". אם נזכור את ההגדרה של קשר זיהוי מלא של כיתות ישות, יתברר שקוד התלמיד הייחודי באמת, שהוא המפתח העיקרי של כיתת הישות "סטודנטים", מציין לכל היותר תכונה אחת עם קוד כזה בכל ישות צאצאית. כיתת "סטודנט", "סטודנטים". ותואר שני. לכן, לכל הקשרים יש רק ריבוי כזה. הבה נכתוב קטע של המפעילים ליצירת היחסים הבסיסיים "ילדי בית ספר" ו"סטודנטים" עם הגדרת כללים לשמירה על שלמות התייחסותית מסוג מפל. אז יש לנו: צור שולחן תלמידים ... מפתח ראשי (קוד תלמיד) הפניות מפתח זר (זיהוי סטודנט) תלמידים (זיהוי סטודנט) על מפל עדכונים על מחיקת אשד צור טבלה תלמידים ... מפתח ראשי (קוד תלמיד) הפניות למפתח זר (זיהוי סטודנט) תלמידים (זיהוי סטודנט) על מפל עדכונים על מחיקת מפל; לפיכך, אנו רואים שבמחלקת הישות (או הקשר) "תלמיד" מצוין מפתח זר ראשי המתייחס למחלקת הישות (או הקשר) האב "סטודנטים". כלל המפל לשמירה על שלמות ההתייחסות קובע שכאשר תכונות של כיתת הישות ההורה "סטודנטים" נמחקות או מתעדכנות, התכונות המתאימות של קשר הילד "תלמיד" יעודכנו או יימחקו באופן אוטומטי (במדורגים). באופן דומה, כאשר תכונות של כיתת הישות ההורה "סטודנטים" נמחקות או מתעדכנות, התכונות המתאימות של קשר הילד "סטודנטים" יעודכנו או יימחקו באופן אוטומטי. יש לציין שכלל יושרה התייחסותי זה משמש כאן, כי בהקשר זה (רשימת התלמידים) אין זה רציונלי לאסור מחיקה ועדכון של מידע, וגם להקצות ערך לא מוגדר במקום מידע אמיתי. . כעת ניתן דוגמה למחלקות הישות המתוארות בתרשים הקודם, המוצגות רק בצורת טבלה. אז יש לנו את טבלאות הקשר הבאות: תלמידים - קשר הורה המשלב מידע על התכונות של כל שאר מערכות היחסים:
תלמידי בתי ספר - יחסי ילדים:
סטודנטים - קשר ילד שני:
סטודנטים לדוקטורט - יחסי ילד שלישי:
אז, אכן, אנו רואים שכיתות הילד של הישויות אינן מכילות מידע על שם המשפחה, השם הפרטי והפטרונימי של התלמידים, כלומר תלמידי בית ספר, סטודנטים וסטודנטים לתארים מתקדמים. ניתן לקבל מידע זה רק באמצעות הפניות למחלקת הישות האב. אנו רואים גם שקודים שונים של תלמידים בכיתת הישות "סטודנטים" יכולים להתאים לכיתות ישות שונות. אז על התלמיד עם הקוד "1" ניקולאי זבוטין, שום דבר לא ידוע ביחסי ההורים, מלבד שמו, וכל שאר המידע (מי הוא, תלמיד בית ספר, תלמיד או סטודנט לתואר שני) ניתן למצוא רק על ידי הפניה למחלקת הישות המתאימה (נקבעת על ידי הקוד). באופן דומה, אתה צריך לעבוד עם שאר התלמידים, שהקודים שלהם מצוינים בכיתת הישות ההורה "סטודנטים". 5. הרכב היחס של מחלקות ישויות מסוג הרכב, כמו שתי הקודמות, אינו שייך לסוג הקשר הרקורסי. הרכב (או, כפי שזה נקרא לפעמים, צבירה מורכבת) הוא קשר של מחלקה של ישות חד-הורית עם מחלקות ישות מרובות, בדיוק כמו הקשר שדיברנו עליו קודם לכן. הַכלָלָה. אבל אם הכללה הוגדרה כקשר של מחלקות ישויות המתוארות על ידי זיהוי מלא של קשרים, אז הרכב, בתורו, מתואר על ידי זיהוי חלקי של קשרים, כלומר במהלך ההרכבה, כל תכונה של המפתח הראשי של מחלקת הישות האב נודדת לתכונת המפתח. של כיתת ישות הילד. ובאותו הזמן, תכונות המפתח המעביר יוצרות רק חלקית את המפתח הראשי של מחלקת הישות הילד. אז, עם צבירה מורכבת (עם הרכב), מחלקת הישות האב (או מצטבר) משויך למספר כיתות של ישות צאצאית (או רכיבים). במקרה זה, הרכיבים של הצבירה (כלומר, הרכיבים של מחלקת הישות האב) מתייחסים לצבירה באמצעות מפתח זר שהוא חלק מהמפתח הראשי, ולכן, אינו יכול להתקיים מחוץ לצבירה. באופן כללי, צבירה מורכבת היא צורה משופרת של צבירה פשוטה (עליה נדבר מעט מאוחר יותר). קומפוזיציה (או צבירה מורכבת) מתאפיינת בעובדה ש: 1) ההתייחסות למכלול מעורבת בזיהוי הרכיבים; 2) רכיבים אלו אינם יכולים להתקיים מחוץ למצרף. צבירה (קשר שנשקול עוד יותר) עם קשרים שאינם מזהים בהכרח לא מאפשרת לרכיבים להתקיים מחוץ לצבירה ולכן קרובה במשמעותה ליישום של צבירה מורכבת שתוארה לעיל. הבה נבנה דיאגרמת מפתח המתארת את הקשר בין מחלקה אחת של ישות אב לכמה מחלקות ישויות צאצאיות, כלומר, מתארת את הקשר של מחלקות ישויות מסוג צבירה מורכבת. תן לזה להיות דיאגרמת מפתח המתארת את הרכב הבניינים של קמפוס מסוים, כולל מבנים, כיתות לימוד ומעליות. אז התרשים הזה ייראה כך:
אז בואו נסתכל על התרשים שיצרנו זה עתה. מה אנחנו רואים בו? ראשית, אנו רואים שהקשר המשמש בצבירה מורכבת זו אכן מזהה ואכן אינו מזהה לחלוטין. אחרי הכל, המפתח הראשי של כיתת הישות ההורה "בניינים" מעורב ביצירת המפתח הראשי של כיתות הישות הילד "קהלים" ו"מעליות", אך אינו מגדיר אותו לחלוטין. המפתח הראשי "מקרה מס'" של מחלקת הישות ההורה עובר למפתחות הראשיים הלועזיים "מקרה מס' של שתי מחלקות הילד, אך בנוסף למפתח שהועבר זה, לשתי מחלקות הישות הראשיות יש גם מפתח ראשי משלהן, בהתאמה "קהל לא" ו-"מעלית מס' ", כלומר המפתחות הראשיים המרוכבים של מחלקות הישות הבנות הן תכונות שנוצרו באופן חלקי בלבד של המפתח הראשי של מחלקת הישות האב. כעת נסתכל על ריבוי הקישורים המחברים בין ההורה לבין שתי כיתות הילד. מכיוון שעסקינן בקישורים שאינם מזהים לחלוטין, הריבוי נוכח: "אחד" ו"רבים". הריבוי "אחד" קיים בקצה האב של שני הקשרים ומסמל שברשימה של כל הקורפוסים הזמינים (ומחלקת הישות "קורפוס" היא בדיוק רשימה כזו), כל מספר יכול להופיע רק פעם אחת, (ולא יותר מזה) פעמים. וגם, בתורו, בין התכונות של כיתות "קהל" ו"מעליות", כל מספר בניין יכול להופיע פעמים רבות, מכיוון שיש יותר קהלים (או מעליות) מבניינים, ובכל בניין ישנם מספר אולמות ומעליות. לפיכך, בעת רישום כל הכיתות והמעליות, נחזור בהכרח על מספרי הבניינים. ולבסוף, כמו במקרה של סוג החיבור הקודם, בואו נרשום את שברי האופרטורים ליצירת יחסים בסיסיים (או, שזה אותו דבר, מחלקות ישויות) "קהלים" ו"מעליות", ואנו נעשה לעשות זאת עם ההגדרה של כללים לשמירה על שלמות התייחסותית מסוג מפל. אז ההצהרה הזו תיראה כך: צור קהלים בטבלה ... מפתח ראשי (מספר קורפוס, מספר קהל) מפתח זר (מספר מקרה) הפניות דפוסים (מספר מקרה) על מפל עדכונים על מחיקת אשד צור מעליות טבלה ... מפתח ראשי (מספר תיק, מספר מעלית) מפתח זר (מספר מקרה) הפניות דפוסים (מספר מקרה) על מפל עדכונים על מחיקת מפל; לפיכך, קבענו את כל המפתחות הראשיים והזרים הדרושים של כיתות הישות הילד. שוב לקחנו את הכלל של שמירה על שלמות התייחסות כמפל, שכן כבר תיארנו אותו כרציונלי ביותר. כעת ניתן דוגמה בצורת טבלה של כל מחלקות הישות שחשבנו זה עתה. הבה נתאר את אותם יחסים בסיסיים ששיקפנו בעזרת דיאגרמה בצורת טבלאות, ולשם הבהירות, נציג שם כמות מסוימת של נתונים אינדיקטיביים. מארזים מערכת היחסים עם ההורים נראית כך:
קהלים - כיתת ישות ילד:
מעליות - כיתת הישות השנייה של כיתת האב "מארזים":
אז, אנו יכולים לראות כיצד המידע מאורגן עבור כל הבניינים, הכיתות והמעליות שלהם במסד נתונים זה, אשר יכול לשמש כל מוסד חינוכי בחיים האמיתיים. 6. צבירה צבירה היא סוג הקשר האחרון בין כיתות ישות שיישקלו כחלק מהקורס שלנו. הוא גם אינו רקורסיבי, ואחד משני הסוגים שלו די קרוב במשמעותו לצבירה המרוכבת שנחשבה בעבר. לפיכך, צבירה הוא הקשר של כיתת ישות אב אחת עם כיתות ישות מרובות. במקרה זה, ניתן לתאר את הקשר על ידי שני סוגים של קשרים: 1) קישורים שאינם מזהים בהכרח; 2) קישורים אופציונליים שאינם מזהים. זכור כי עם קשרים שאינם בהכרח מזהים, חלק מהמאפיינים של המפתח הראשי של מחלקת הישות ההורה מועברים לתכונה ללא מפתח של מחלקת הילד, וערכי Null עבור כל התכונות של המפתח המעביר אסורים. ועם קשרים שאינם בהכרח לא מזהים, ההגירה של מפתחות ראשיים מתרחשת בדיוק על פי אותו עיקרון, אך מותרים ערכי Null עבור חלק מהמאפיינים של המפתח המעביר. בעת צבירה, מחלקת הישות האב (או מצטבר) משויך למספר כיתות של ישות צאצאית (או רכיבים). הרכיבים של המצטבר (כלומר, מחלקת הישות האב) מתייחסים לצבירה דרך מפתח זר שאינו חלק מהמפתח הראשי, ולכן, במקרה לא בהכרח קישורים לא מזהים, רכיבים מצטברים יכולים להתקיים מחוץ למצרף. במקרה של צבירה עם קשרים שאינם בהכרח מזהים, אסור למרכיבי המצרף להתקיים מחוץ למצרף, ובמובן זה, צבירה עם קשרים שאינם בהכרח מזהים קרובה לצבירה מורכבת. כעת, לאחר שהתברר מהו קשר סוג צבירה, בואו נבנה דיאגרמת מפתח המתארת את פעולת הקשר הזה. תן לתרשים העתידי שלנו לתאר את הרכיבים המסומנים של מכוניות (כלומר המנוע והשלדה). יחד עם זאת, נניח שהשבתת המכונית מרמזת על השבתת השלדה יחד איתה, אך אינה מרמזת על ביטול בו-זמנית של המנוע. אז דיאגרמת המפתח שלנו נראית כך:
אז מה אנחנו רואים בתרשים מפתח זה? ראשית, הקשר של מחלקת הישות "מכוניות" עם מחלקת הישות הילדית "מנועים" אינו בהכרח בלתי מזהה, מכיוון שהתכונה "מכונית #" מאפשרת ערכי אפס בין ערכיה. בתורו, תכונה זו מאפשרת ערכי Null מהסיבה שביטול המנוע, לפי תנאי, אינו תלוי בהשבתה של הרכב כולו, ולכן היא לא בהכרח מתרחשת בעת הוצאת מכונית משימוש. אנו רואים גם שהמפתח הראשי "מנוע #" של מחלקת הישות "מכוניות" עובר לתכונה הלא-מפתח "מנוע #" של מחלקת הישות "מנועים". ובמקביל, תכונה זו מקבלת מעמד של מפתח זר. והמפתח הראשי במחלקת הישות הזו של Engines הוא תכונת Engine Marker, שאינה מתייחסת לאף תכונה של קשר האב. שנית, היחס בין מחלקת הישות ההורה "Motors" לבין מחלקת הישות הילדית "Chassis" הוא בהכרח קשר לא מזהה, מכיוון שתכונת המפתח הזר "Car #" אינה מאפשרת ערכי Null בין ערכיה. זה, בתורו, מתרחש מכיוון שידוע בתנאי שביטול המכונית מרמז על ביטול חובה בו-זמנית של השלדה. כאן, בדיוק כמו במקרה של מערכת היחסים הקודמת, המפתח הראשי של מחלקת הישות ההורה "מנועים" מועבר לתכונה הלא-מפתחית "מספר רכב" של מחלקת הישות הילדית "שלדה". יחד עם זאת, המפתח העיקרי של מחלקת ישות זו הוא התכונה "סמן שלדה", שאינה מתייחסת לאף תכונה של מערכת היחסים ההורה "מנועים". תמשיך הלאה. להטמעה מיטבית של הנושא, בואו נרשום שוב את שברי המפעילים ליצירת היחסים הבסיסיים "מנועים" ו"שלדה" עם הגדרת כללים לשמירה על שלמות התייחסותית. צור מנועי טבלה ... מפתח ראשי (סמן מנוע) מפתח זר (מספר רכב) הפניות מכוניות (מספר רכב) על מפל עדכונים על מחיקה הגדר Null צור מארז שולחן ... מפתח ראשי (סמן מארז) מפתח זר (מספר רכב) הפניות מכוניות (מספר רכב) על מפל עדכונים על מחיקת מפל; אנו רואים שהשתמשנו באותו כלל לשמירה על שלמות התייחסותית בכל מקום - מפל, שכן עוד קודם לכן זיהינו אותו כרציונלי מכולם. עם זאת, הפעם השתמשנו (בנוסף לכלל ה-cascade) בכלל ה-Null referential integrity set. יתר על כן, השתמשנו בו בתנאי הבא: אם נמחק ערך כלשהו של המפתח הראשי "מספר מכונית" ממחלקת הישות ההורה "מכוניות", אז הערך של המפתח הזר "מספר מכונית" של הקשר הבן "מנועים" בהתייחסות אליו יוקצה ערך Null . 7. איחוד תכונות אם, במהלך ההגירה של מפתחות ראשיים של מחלקת ישות אב מסוימת, תכונות ממחלקות הורה שונות החופפות במשמעותן נכנסות לאותה מחלקת צאצא, אז יש "למזג" תכונות אלו, כלומר, יש צורך לבצע זאת. -שקוראים לו איחוד תכונות. לדוגמה, במקרה שבו עובד יכול לעבוד בארגון, כשהוא רשום לא יותר ממחלקה אחת, לאחר איחוד התכונה "קוד ארגון", נקבל את דיאגרמת המפתח הבאה:
כאשר מעבירים את המפתח הראשי ממחלקות הישות ההורה "ארגון" ו"מחלקות" למחלקת הילד "עובדים", התכונה "מזהה ארגון" נכנסת למחלקת הישות "עובדים". ופעמיים: 1) פעם ראשונה עם מרקר PFK ממחלקת הישות "ארגון" בעת יצירת קשר זיהוי חלקי; 2) ובפעם השנייה, עם סמן FK עם התנאי של קבלת ערכי Null ממחלקת הישות "Departments" בעת יצירת קשר לא בהכרח לא מזהה. כאשר היא מאוחדת, התכונה "מזהה ארגון" מקבלת סטטוס של תכונת מפתח ראשי/זר, וסופגת את הסטטוס של תכונת המפתח הזר. בואו נבנה דיאגרמת מפתח חדשה המדגימה את תהליך האיחוד עצמו:
לפיכך, התרחש איחוד התכונות. הרצאה מס' 13. מערכות מומחה ומודל ייצור ידע 1. מינוי מערכות מומחים להכיר מושג חדש עבורנו כמו מערכות מומחים אנו, בתור התחלה, נעבור על ההיסטוריה של היצירה והפיתוח של כיוון "מערכות מומחה", ולאחר מכן נגדיר את עצם המושג של מערכות מומחים. בתחילת שנות ה-80. המאה ה -XNUMX במחקר על יצירת בינה מלאכותית, נוצר כיוון עצמאי חדש, הנקרא מערכות מומחים. מטרת המחקר החדש על מערכות מומחים היא לפתח תוכניות מיוחדות המיועדות לפתור סוגים ספציפיים של בעיות. מהי הסוג המיוחד הזה של בעיה שדרשה יצירת הנדסת ידע חדשה לגמרי? סוג מיוחד זה של משימות יכול לכלול משימות מכל תחום נושא. הדבר העיקרי שמבדיל אותם מבעיות רגילות הוא שנראה שזו משימה קשה מאוד עבור מומחה אנושי לפתור אותן. ואז הראשון שנקרא מערכת מומחים (כאשר תפקידו של מומחה לא היה עוד אדם, אלא מכונה), ומערכת המומחים זוכה לתוצאות שאינן נחותות באיכותן וביעילותן מהפתרונות שהשיג אדם רגיל – מומחה. את תוצאות העבודה של מערכות מומחים ניתן להסביר למשתמש ברמה גבוהה מאוד. איכות זו של מערכות מומחים מובטחת על ידי יכולתן לנמק את הידע והמסקנות שלהן. מערכות מומחים עשויות בהחלט לחדש את הידע שלהן בתהליך האינטראקציה עם מומחה. לפיכך, ניתן להעמיד אותם בביטחון מלא בשורה אחת עם בינה מלאכותית מעוצבת במלואה. חוקרים בתחום מערכות מומחים לשם הדיסציפלינה שלהם משתמשים לעתים קרובות גם במונח שהוזכר קודם לכן "הנדסת ידע", שהציג המדען הגרמני א' פייגנבוים כ"מביא את העקרונות והכלים של המחקר מתחום הבינה המלאכותית לפתרון בעיות יישומיות קשות הדורשות ידע מומחה." עם זאת, הצלחה מסחרית לחברות הפיתוח לא הגיעה מיד. במשך רבע מאה מ-1960 עד 1985. ההצלחות של בינה מלאכותית היו קשורות בעיקר לפיתוחים מחקריים. עם זאת, החל מ-1985 בערך, ובקנה מידה עצום מ-1987 עד 1990. נעשה שימוש פעיל במערכות מומחים ביישומים מסחריים. היתרונות של מערכות מומחים הם די גדולים והם כדלקמן: 1) טכנולוגיית מערכות מומחים מרחיבה באופן משמעותי את מגוון המשימות המשמעותיות באופן מעשי הנפתרות במחשבים אישיים, שהפתרון שלה מביא יתרונות כלכליים משמעותיים ומפשט מאוד את כל התהליכים הקשורים; 2) טכנולוגיית מערכת מומחים היא אחד הכלים החשובים ביותר בפתרון הבעיות הגלובליות של התכנות המסורתיות, כגון משך הזמן, האיכות, וכתוצאה מכך, העלות הגבוהה של פיתוח יישומים מורכבים, כתוצאה מכך ההשפעה הכלכלית הופחתה באופן משמעותי. ; 3) ישנה עלות גבוהה לתפעול ותחזוקה של מערכות מורכבות, שלעיתים עולה על עלות הפיתוח עצמו פי כמה, כמו גם רמה נמוכה של שימוש חוזר בתוכניות וכו'; 4) השילוב של טכנולוגיית מערכות מומחים עם טכנולוגיית תכנות מסורתית מוסיף איכויות חדשות למוצרי תוכנה על ידי, ראשית, מתן שינוי דינמי של יישומים על ידי משתמש רגיל, ולא על ידי מתכנת; שנית, "שקיפות" גדולה יותר של האפליקציה, גרפיקה טובה יותר, ממשק ואינטראקציה של מערכות מומחים. לדברי משתמשים רגילים ומומחים מובילים, בעתיד הקרוב, מערכות מומחים ימצאו את היישומים הבאים: 1) מערכות מומחים ישחקו תפקיד מוביל בכל שלבי התכנון, הפיתוח, הייצור, ההפצה, איתור באגים, בקרה ומתן שירותים; 2) טכנולוגיית מערכות מומחים, שזכתה להפצה מסחרית רחבה, תספק פריצת דרך מהפכנית באינטגרציה של יישומים ממודולים מוכנים לאינטראקציה אינטליגנטית. באופן כללי, מערכות מומחה מיועדות למה שנקרא משימות לא פורמליות, כלומר, מערכות מומחים אינן דוחות ואינן מחליפות את הגישה המסורתית לפיתוח תוכניות המתמקדת בפתרון בעיות פורמליות, אלא משלימות אותן, ובכך מרחיבות באופן משמעותי את האפשרויות. זה בדיוק מה שמומחה אנושי בלבד לא יכול לעשות. משימות מורכבות כאלה שאינן פורמליות מאופיינות ב: 1) כשל, אי דיוק, אי בהירות, כמו גם חוסר שלמות וחוסר עקביות של נתוני המקור; 2) כשל, אי בהירות, אי דיוק, חוסר שלמות וחוסר עקביות של ידע על אזור הבעיה ועל הבעיה הנפתרת; 3) מימד גדול של מרחב הפתרונות של בעיה ספציפית; 4) שונות דינמית של נתונים וידע ישירות בתהליך של פתרון בעיה בלתי פורמלית כזו. מערכות מומחים מבוססות בעיקר על חיפוש היוריסטי אחר פתרון, ולא על ביצוע של אלגוריתם ידוע. זהו אחד היתרונות העיקריים של טכנולוגיית מערכות מומחים על פני הגישה המסורתית לפיתוח תוכנה. זה מה שמאפשר להם להתמודד כל כך טוב עם המשימות שהוטלו עליהם. טכנולוגיית מערכות מומחה משמשת לפתרון מגוון בעיות. אנו מפרטים את עיקר המשימות הללו. 1. פשר. מערכות מומחים המבצעות פרשנות משתמשות לרוב בקריאות של מכשירים שונים כדי לתאר את מצב העניינים. מערכות מומחים פרשניות מסוגלות לעבד מגוון סוגי מידע. דוגמה לכך היא שימוש בנתוני אנליזה ספקטרלית ושינויים במאפיינים של חומרים כדי לקבוע את הרכבם ותכונותיהם. כמו כן, דוגמה לכך היא פירוש קריאות מכשירי המדידה בחדר הדוודים לתיאור מצב הדוודים והמים שבהם. מערכות פרשניות עוסקות לרוב ישירות בקריאות. בהקשר זה מתעוררים קשיים שאין לסוגים אחרים של מערכות. מהם הקשיים הללו? קשיים אלו מתעוררים בשל העובדה שמערכות מומחים צריכות לפרש מידע מיותר, לא שלם, לא אמין או שגוי סתום. מכאן, שגיאות או עלייה משמעותית בעיבוד הנתונים הם בלתי נמנעים. 2. נבואה. מערכות מומחים המבצעות תחזית של משהו קובעות את התנאים ההסתברותיים של מצבים נתונים. דוגמאות לכך הן תחזית הנזק שנגרם לקציר התבואה מתנאי מזג אוויר קשים, הערכת הביקוש לגז בשוק העולמי, תחזיות מזג אוויר לפי תחנות מטאורולוגיות. מערכות חיזוי משתמשות לפעמים במודלים, כלומר, תוכניות שמציגות כמה מערכות יחסים בעולם האמיתי כדי ליצור אותן מחדש בסביבת תכנות, ולאחר מכן לעצב מצבים שעלולים להיווצר עם נתונים ראשוניים מסוימים. 3. אבחון של מכשירים שונים. מערכות מומחים מבצעות אבחון כזה על ידי שימוש בתיאורים של כל מצב, התנהגות או נתונים על המבנה של רכיבים שונים על מנת לקבוע את הגורמים האפשריים למערכת הניתנת לאבחון תקלה. דוגמאות לכך הן ביסוס נסיבות המחלה לפי התסמינים הנצפים בחולים (ברפואה); זיהוי תקלות במעגלים אלקטרוניים וזיהוי רכיבים פגומים במנגנונים של מכשירים שונים. מערכות אבחון הן לעתים קרובות עוזרות שלא רק מבצעות אבחון, אלא גם עוזרות בפתרון בעיות. במקרים כאלה, מערכות אלו עשויות ליצור אינטראקציה עם המשתמש כדי לסייע בפתרון בעיות ולאחר מכן לספק רשימה של פעולות הנדרשות כדי לפתור אותן. כיום, מערכות אבחון רבות מפותחות כיישומים למערכות הנדסה ומחשוב. 4. תכנון אירועים שונים. מערכות מומחה המיועדות לתכנון תכנון פעולות שונות. מערכות קובעות מראש רצף כמעט שלם של פעולות לפני שהטמעתן מתחילה. דוגמאות לתכנון אירועים כאלה הן יצירת תכניות לפעולות צבאיות, הגנתיות והן התקפיות, שנקבעו מראש לתקופה מסוימת על מנת להשיג יתרון על פני כוחות האויב. 5. Проектирование. מערכות מומחים המבצעות עיצוב מפתחות צורות שונות של אובייקטים, תוך התחשבות בנסיבות הקיימות ובכל הגורמים הקשורים. דוגמה לכך היא הנדסה גנטית. 6. לשלוט. מערכות מומחים המפעילות בקרה משווים את ההתנהגות הנוכחית של המערכת להתנהגותה הצפויה. התבוננות במערכות מומחים מזהה התנהגות מבוקרת המאששת את הציפיות שלהם לעומת התנהגות רגילה או את ההנחה שלהם לגבי סטיות אפשריות. בקרה על מערכות מומחים, מעצם טבען, חייבות לעבוד בזמן אמת וליישם פרשנות תלוית זמן ותלוית הקשר של התנהגות האובייקט הנשלט. דוגמאות כוללות ניטור קריאות של מכשירי מדידה בכורים גרעיניים על מנת לזהות מצבי חירום או הערכת נתוני אבחון של חולים ביחידה לטיפול נמרץ. 7. Управление. הרי ידוע לכל כי מערכות מומחים המפעילות בקרה, מנהלות ביעילות רבה את התנהגות המערכת כולה. דוגמה לכך היא ניהול תעשיות שונות וכן הפצת מערכות מחשוב. מערכות מומחי בקרה חייבות לכלול התבוננות ברכיבים על מנת לשלוט בהתנהגות של אובייקט לאורך תקופה ארוכה, אך הן עשויות להזדקק גם לרכיבים אחרים מסוגי המשימות שכבר נותחו. מערכות מומחים משמשות בתחומים שונים: עסקאות פיננסיות, תעשיית הנפט והגז. טכנולוגיית מערכות מומחה יכולה להיות מיושמת גם באנרגיה, תחבורה, תעשיית התרופות, פיתוח חלל, תעשיות מתכות וכרייה, כימיה ותחומים רבים אחרים. 2. מבנה מערכות מומחים לפיתוח מערכות מומחים יש מספר הבדלים משמעותיים מפיתוח מוצר תוכנה קונבנציונלי. הניסיון ביצירת מערכות מומחים הראה שהשימוש במתודולוגיה שאומצה בתכנות מסורתיות בפיתוחן מגדיל במידה ניכרת את משך הזמן המושקע ביצירת מערכות מומחים, או אפילו מוביל לתוצאה שלילית. מערכות מומחים מחולקות בדרך כלל ל סטָטִי и דינמי. ראשית, שקול מערכת מומחים סטטית. תקן מערכת מומחים סטטית מורכב מהמרכיבים העיקריים הבאים: 1) זיכרון עבודה, הנקרא גם מסד הנתונים; 2) מאגרי ידע; 3) פותר, הנקרא גם מתורגמן; 4) מרכיבי רכישת ידע; 5) מרכיב הסבר; 6) רכיב דיאלוג. כעת נשקול כל רכיב ביתר פירוט. זיכרון עובד (באנלוגיה מוחלטת לעבודה, כלומר, זיכרון RAM במחשב) נועד לקבל ולאחסן את הנתונים הראשוניים והבינוניים של המשימה הנפתרת ברגע הנוכחי. База знаний נועד לאחסן נתונים ארוכי טווח המתארים תחום נושא ספציפי, וכללים המתארים את השינוי הרציונלי של נתונים בתחום זה של הבעיה הנפתרת. פּוֹתֵרהמכונה גם מְתוּרגְמָן, מתפקד כדלקמן: שימוש בנתונים הראשוניים מזיכרון העבודה ובנתונים ארוכי טווח ממאגר הידע, הוא יוצר את הכללים, שהיישום שלהם על הנתונים הראשוניים מוביל לפתרון הבעיה. במילה אחת, הוא באמת "פותר" את הבעיה המונחת לפניו; רכיב רכישת ידע עושה אוטומציה של תהליך מילוי מערכת המומחים בידע מומחה, כלומר רכיב זה הוא זה שמספק למאגר הידע את כל המידע הדרוש מתחום הנושא המסוים הזה. הסבר רכיב מסביר כיצד השיגה המערכת פתרון לבעיה זו, או מדוע היא לא קיבלה פתרון זה, ואיזה ידע היא השתמשה בכך. במילים אחרות, רכיב ההסבר מייצר דוח התקדמות. לרכיב זה חשיבות רבה בכל מערכת המומחים, שכן הוא מקל מאוד על בדיקת המערכת על ידי מומחה, וכן מגביר את הביטחון של המשתמש בתוצאה המתקבלת ולכן מזרז את תהליך הפיתוח. רכיב דיאלוג משמשת לספק ממשק משתמש ידידותי הן במהלך פתרון בעיה והן בתהליך רכישת ידע והכרזה על תוצאות העבודה. כעת, כשאנחנו יודעים מאילו רכיבים מורכבת מערכת מומחה סטטיסטית בדרך כלל, בואו נבנה תרשים שמשקף את המבנה של מערכת מומחה כזו. זה נראה כמו זה:
מערכות מומחים סטטיות משמשות לרוב ביישומים טכניים שבהם ניתן לא לקחת בחשבון שינויים בסביבה המתרחשים במהלך פתרון בעיה. מעניין לדעת שמערכות המומחים הראשונות שקיבלו יישום מעשי היו סטטיות בדיוק. אז, על זה נסיים לעת עתה את השיקול של מערכת המומחים הסטטיסטית, נעבור לניתוח של מערכת המומחים הדינמית. למרבה הצער, תוכנית הקורס שלנו אינה כוללת התייחסות מפורטת למערכת מומחים זו, ולכן נצמצם את עצמנו לנתח רק את ההבדלים הבסיסיים ביותר בין מערכת מומחים דינמית למערכת סטטית. בניגוד למערכת מומחים סטטית, המבנה מערכת מומחים דינמית בנוסף, מוצגים שני המרכיבים הבאים: 1) תת-מערכת לדוגמנות העולם החיצון; 2) תת-מערכת של יחסים עם הסביבה החיצונית. תת מערכת של יחסים עם הסביבה החיצונית זה רק יוצר קשרים עם העולם החיצון. היא עושה זאת באמצעות מערכת של חיישנים ובקרים מיוחדים. בנוסף, חלק מהמרכיבים המסורתיים של מערכת מומחים סטטית עוברים שינויים משמעותיים על מנת לשקף את ההיגיון הזמני של אירועים המתרחשים כיום בסביבה. זהו ההבדל העיקרי בין מערכות מומחים סטטיות לדינמיות. דוגמה למערכת מומחים דינמית היא ניהול ייצור תרופות שונות בתעשיית התרופות. 3. משתתפים בפיתוח מערכות מומחים נציגים של התמחויות שונות מעורבים בפיתוח מערכות מומחים. לרוב, מערכת מומחים ספציפית פותחה על ידי שלושה מומחים. זה בדרך כלל: 1) מומחה; 2) מהנדס ידע; 3) מתכנת לפיתוח כלים. הבה נסביר את תחומי האחריות של כל אחד מהמומחים המפורטים כאן. מומחה הוא מומחה בתחום, אשר משימותיו ייפתרו בעזרת מערכת מומחים זו המפותחת. מהנדס ידע הוא מומחה בפיתוח מערכת מומחים ישירות. הטכנולוגיות והשיטות המשמשות אותו נקראות טכנולוגיות ושיטות הנדסת ידע. מהנדס ידע מסייע למומחה לזהות מתוך כל המידע בתחום הנושא את המידע הדרוש לעבודה עם מערכת מומחה מסוימת המפותחת, ולאחר מכן לבנות אותה. זה מוזר שהיעדר מהנדסי ידע בין המשתתפים בפיתוח, כלומר החלפתם במתכנתים, או מוביל לכישלון הפרויקט כולו של יצירת מערכת מומחה ספציפית, או מגדיל משמעותית את זמן הפיתוח שלה. ולבסוף, מְתַכנֵת מפתחת כלים (אם כלים פותחו לאחרונה) שנועדו להאיץ את הפיתוח של מערכות מומחים. כלים אלו מכילים, עד גבול, את כל המרכיבים העיקריים של מערכת מומחה; המתכנת גם ממשק את הכלים שלו עם הסביבה שבה הוא ישמש. 4. מצבי הפעלה של מערכות מומחים מערכת המומחים פועלת בשני מצבים עיקריים: 1) באופן של רכישת ידע; 2) באופן פתרון הבעיה (נקרא גם אופן ההתייעצויות, או אופן השימוש במערכת המומחים). זה הגיוני ומובן, כי ראשית יש צורך, כביכול, להעמיס על מערכת המומחים מידע מתחום הנושא בו היא צריכה לעבוד, זהו מצב ה"אימון" של מערכת המומחים, האופן שבו היא מקבל ידע. ולאחר טעינת כל המידע הדרוש לעבודה, העבודה עצמה מגיעה. מערכת המומחים הופכת מוכנה לפעולה, וניתן להשתמש בה כעת להתייעצויות או לפתרון כל בעיה. בואו נשקול ביתר פירוט מצב רכישת ידע. במצב של רכישת ידע, העבודה עם מערכת המומחים מתבצעת על ידי מומחה באמצעות מהנדס ידע. במצב זה, המומחה, באמצעות רכיב רכישת הידע, ממלא את המערכת בידע (נתונים), אשר, בתורו, מאפשר למערכת לפתור בעיות מתחום נושא זה במצב הפתרון ללא השתתפות של מומחה. יש לציין שמצב רכישת הידע בגישה המסורתית לפיתוח תוכניות מתאים לשלבי האלגוריתמיזציה, התכנות והניפוי שבוצעו ישירות על ידי המתכנת. יוצא מכך שבניגוד לגישה המסורתית, במקרה של מערכות מומחים, פיתוח התוכנות מתבצע לא על ידי מתכנת, אלא על ידי מומחה, כמובן, בעזרת מערכות מומחה, כלומר, בגדול , אדם שאינו יודע תכנות. ועכשיו בואו נשקול את אופן התפקוד השני של מערכת המומחים, כלומר. מצב פתרון בעיות. במצב פתרון בעיות (או מה שנקרא מצב ייעוץ), התקשורת עם מערכות מומחים מתבצעת ישירות על ידי משתמש הקצה, המעוניין בתוצאה הסופית של העבודה ולעיתים בשיטת השגתה. יש לציין כי בהתאם למטרת מערכת המומחים, המשתמש אינו חייב להיות מומחה בתחום הבעייתי הזה. במקרה זה, הוא פונה למערכות מומחים לצורך התוצאה, ללא ידע מספיק כדי להשיג תוצאות. לחלופין, ייתכן שלמשתמש עדיין יש רמת ידע מספיקה כדי להשיג את התוצאה הרצויה בעצמו. במקרה זה, המשתמש יכול לקבל את התוצאה בעצמו, אך פונה למערכות מומחים על מנת לזרז את תהליך השגת התוצאה, או להקצות עבודה מונוטונית למערכות המומחים. במצב ייעוץ, נתונים על משימת המשתמש, לאחר שעובדו על ידי רכיב הדו-שיח, נכנסים לזיכרון העבודה. הפותר, המבוסס על נתוני קלט מזיכרון העבודה, נתונים כלליים על אזור הבעיה וחוקים ממסד הנתונים, מייצר פתרון לבעיה. בעת פתרון בעיה, מערכות מומחים לא רק מבצעות את הרצף שנקבע של פעולה ספציפית, אלא גם יוצרות אותה באופן ראשוני. זה נעשה במקרה שבו תגובת המערכת אינה ברורה לחלוטין למשתמש. במצב זה, המשתמש עשוי לדרוש הסבר מדוע מערכת מומחה זו שואלת שאלה מסוימת או מדוע מערכת מומחה זו אינה יכולה לבצע פעולה זו, כיצד מתקבלת תוצאה זו או אחרת המסופקת על ידי מערכת מומחה זו. 5. מודל ייצור של ידע במהותו, ייצור מודלים של ידע קרוב למודלים לוגיים, מה שמאפשר לך לארגן נהלים יעילים מאוד להסקת נתונים לוגית. זה מצד אחד. עם זאת, מצד שני, אם ניקח בחשבון מודלים של ייצור של ידע בהשוואה למודלים לוגיים, אז הראשונים מציגים ידע בצורה ברורה יותר, וזה יתרון שאין עוררין. לכן, ללא ספק, מודל הייצור של ידע הוא אחד האמצעים העיקריים לייצוג ידע במערכות בינה מלאכותית. אז בואו נתחיל בבחינה מפורטת של הרעיון של מודל ייצור של ידע. מודל הייצור המסורתי של ידע כולל את המרכיבים הבסיסיים הבאים: 1) מערכת כללים (או הפקות) המייצגות את בסיס הידע של מערכת הייצור; 2) זיכרון עבודה, המאחסן את העובדות המקוריות, וכן עובדות הנגזרות מהעובדות המקוריות באמצעות מנגנון ההסקה; 3) מנגנון ההסקה הלוגי עצמו, המאפשר, מהעובדות הזמינות, לפי כללי ההסקה הקיימים, לגזור עובדות חדשות. ובאופן מוזר, מספר פעולות כאלה יכול להיות אינסופי. כל כלל המייצג את בסיס הידע של מערכת הייצור מכיל חלק מותנה וחלק אחרון. החלק המותנה של הכלל מכיל עובדה אחת או מספר עובדות המחוברות בצירוף. החלק האחרון של הכלל מכיל עובדות שצריך למלא בזיכרון עבודה אם החלק המותנה של הכלל נכון. אם ננסה לתאר באופן סכמטי את מודל הייצור של ידע, אז ההפקה מובנת כביטוי לצורה הבאה: (א) ש; פ; א → ב ; נ; כאן i הוא שמו של דגם ייצור הידע או המספר הסידורי שלו, בעזרתו נבדל ייצור זה מכל מערך דגמי הייצור, המקבל איזשהו זיהוי. יחידה מילונית כלשהי המשקפת את המהות של המוצר הזה יכולה לשמש כשם. למעשה, אנו שמות מוצרים לתפיסה טובה יותר על ידי התודעה, על מנת לפשט את החיפוש אחר המוצר הרצוי מהרשימה. ניקח דוגמה פשוטה: קניית מחברת" או "סט של עפרונות צבעוניים. ברור שלרוב מתייחסים לכל מוצר במילים המתאימות לרגע. במילים אחרות, תקראו לאת כף. תמשיך הלאה. אלמנט ה-Q מאפיין את היקף מודל ייצור הידע המסוים הזה. תחומים כאלה מובחנים בקלות במוח האנושי, ולכן, ככלל, אין קשיים עם ההגדרה של אלמנט זה. בואו ניקח דוגמה. בואו ניקח בחשבון את המצב הבא: נניח שבאזור אחד בתודעה שלנו מאוחסן הידע כיצד לבשל אוכל, באחר, כיצד להגיע לעבודה, בשלישי, כיצד להפעיל נכון את מכונת הכביסה. חלוקה דומה קיימת גם בזיכרון של מודל הייצור של ידע. חלוקה זו של ידע לאזורים נפרדים יכולה לחסוך באופן משמעותי את הזמן המושקע בחיפוש אחר מודלים ספציפיים של ייצור של ידע הדרושים כרגע, ובכך מפשטת מאוד את תהליך העבודה איתם. כמובן, המרכיב העיקרי של הייצור הוא מה שנקרא הליבה שלו, אשר בנוסחה לעיל שלנו סומנה כ-A → B. ניתן לפרש נוסחה זו כ"אם תנאי A מתקיים, אז יש לבצע פעולה B." אם אנו עוסקים בבניות גרעין מורכבות יותר, אזי הבחירה החלופית הבאה מותרת בצד ימין: "אם תנאי א' מתקיים, אזי יש לבצע פעולה ב'1, אחרת עליך לבצע פעולה ב'2". עם זאת, הפרשנות של הליבה של מודל הייצור של ידע יכולה להיות שונה ותלויה במה שיהיה משמאל ומימין של הסימן העוקב "→". עם אחת הפרשנויות של ליבת מודל הייצור של הידע, ניתן לפרש את הרצף במובן הלוגי הרגיל, כלומר כסימן לתוצאה הלוגית של פעולה ב' מהמצב האמיתי א'. אף על פי כן, אפשריות גם פרשנויות אחרות לליבה של מודל ייצור הידע. כך, למשל, א' יכול לתאר תנאי כלשהו, שקילויו הכרחי על מנת שפעולה ב' כלשהי תתבצע. לאחר מכן, נשקול מרכיב של מודל הייצור של ידע R. Элемент Р מוגדר כתנאי לתחולת ליבת המוצר. אם תנאי P נכון, אז ליבת הייצור מופעלת. אחרת, אם התנאי P לא מתקיים, כלומר הוא שקר, לא ניתן להפעיל את הליבה. כדוגמה להמחשה, שקול את מודל ייצור הידע הבא: "זמינות כסף"; "אם אתה רוצה לקנות דבר א', אז אתה צריך לשלם את העלות שלו לקופאית ולהציג את הצ'ק למוכר." אנחנו מסתכלים, אם התנאי P נכון, כלומר, הרכישה משולמת והצ'ק מוצג, אז הליבה מופעלת. הרכישה הושלמה. אם במודל הייצור הזה של ידע תנאי הישימות של הליבה הוא שקרי, כלומר אם אין כסף, אז אי אפשר ליישם את הליבה של מודל ייצור הידע, והוא לא מופעל. ולבסוף ללכת לאלמנט N. האלמנט N נקרא postcondition של מודל נתוני הייצור. ה-postcondition מגדיר את הפעולות והנהלים שיש לבצע לאחר יישום ליבת הייצור. לתפיסה טובה יותר, בואו ניתן דוגמה פשוטה: לאחר קניית דבר בחנות, יש צורך להפחית את מספר הדברים מסוג זה באחד במלאי הסחורה של חנות זו, כלומר אם הרכישה מתבצעת (ולכן , הליבה נמכרת), אז לחנות יש יחידה אחת של המוצר המסוים הזה פחות. מכאן הפוסט-תנאי "מחצים את היחידה של הפריט הנרכש". לסיכום, אנו יכולים לומר שלייצוג של ידע כמערכת של כללים, כלומר באמצעות שימוש במודל ייצור של ידע, יש את היתרונות הבאים: 1) זוהי הקלות של יצירה והבנה של כללים בודדים; 2) זוהי הפשטות של מנגנון הבחירה הלוגית. עם זאת, בייצוג של ידע בצורה של מערכת כללים, ישנם גם חסרונות שעדיין מגבילים את היקף ותדירות היישום של מודלים של ידע ייצור. החיסרון העיקרי שכזה הוא העמימות של היחסים ההדדיים בין הכללים המרכיבים מודל ייצור ספציפי של ידע, כמו גם כללי הבחירה הלוגית. הערות 1. הגופן המסומן בקו תחתון במהדורה המודפסת של הספר מתאים ל מודגש נטוי בגרסה (אלקטרונית) זו של הספר. (העורך בקירוב)
▪ רפואה משפטית ופסיכיאטריה. עריסה
עור מלאכותי לחיקוי מגע
15.04.2024 פסולת חתולים של Petgugu Global
15.04.2024 האטרקטיביות של גברים אכפתיים
14.04.2024
▪ חומר ביולוגי יחליף את הפלסטיק ▪ מגבר הפעלה אנלוגי של טרנזיסטור דו מימדי ▪ נורות בלוטות' וחיישני בית חכם ▪ מצלמת DVR HD 450 Parkcity עם שתי מצלמות Full HD ▪ תכונות חדשות של מודול ה-WiFi SPWF01SA.11
▪ חלק של האתר שיחות וסימולטורים אודיו. מבחר מאמרים ▪ מאמר מצבי חירום טבעיים ממקור הידרולוגי: שיטפונות, זרימות בוץ, צונאמי. יסודות החיים בטוחים ▪ מאמר באיזו מדינה שיתוף קבצים בחינם מוכר רשמית כדת? תשובה מפורטת ▪ מאמר קולה תרבותי. אגדות, טיפוח, שיטות יישום ▪ מאמר הגנה על מנוע חשמלי תלת פאזי. אנציקלופדיה של רדיו אלקטרוניקה והנדסת חשמל
בית | הספרייה | מאמרים | <font><font>מפת אתר</font></font> | ביקורות על האתר
www.diagram.com.ua |



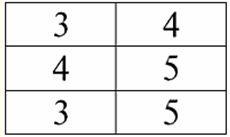
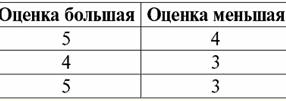

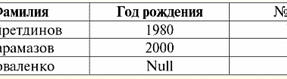

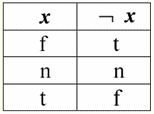

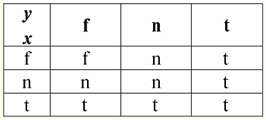
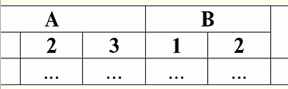


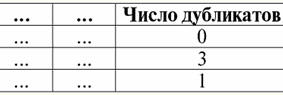
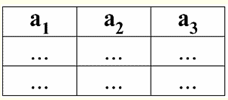






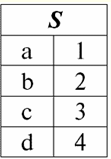
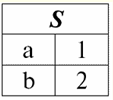

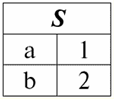

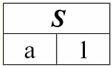
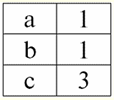

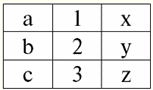









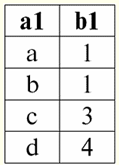






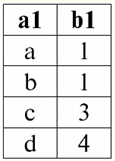



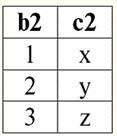

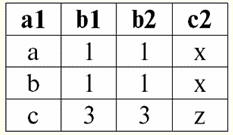







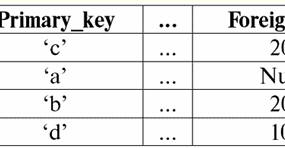











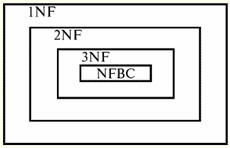

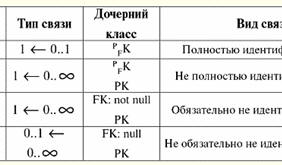









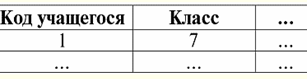
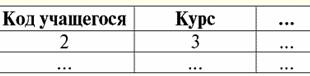





 ראה מאמרים אחרים סעיף
ראה מאמרים אחרים סעיף 